
深入容器运行时:从 stdout/stderr 到 kubectl logs 的完整日志流处理机制
TL;DR
理解容器运行时如何处理 stdout/stderr 流,不仅能满足技术好奇心,更有实际价值:
- 故障排查:日志丢失、截断、延迟等问题的根本原因
- 性能优化:高吞吐量场景下的 I/O 配置调优
- 架构决策:选择合适的容器运行时和日志收集方案
- 深入理解:Kubernetes、Containerd、Runc 各层的职责边界。
引言
作为一名长期使用 Kubernetes 的开发者,我一直对容器日志的底层机制充满好奇。每次执行 kubectl logs 命令,看着应用程序的输出实时流式显示在终端上,我都会忍不住思考:这些日志是如何从容器内部的 stdout 和 stderr 流,穿越多层抽象,最终到达屏幕?虽然日常工作中频繁使用这个功能,但对于这条路径上的技术细节,我却一直没有深入了解过。
这次,我决定彻底弄清楚这个问题:从应用程序的 printf() 或 console.log(),到终端看到的日志,这中间经历了哪些关键步骤?让我们从头开始,逐层揭开这个机制的面纱。
以下的内容基于目前最新的 Kubernetes v1.35.0 和 Containerd v2.2.1。
完整的日志流处理架构
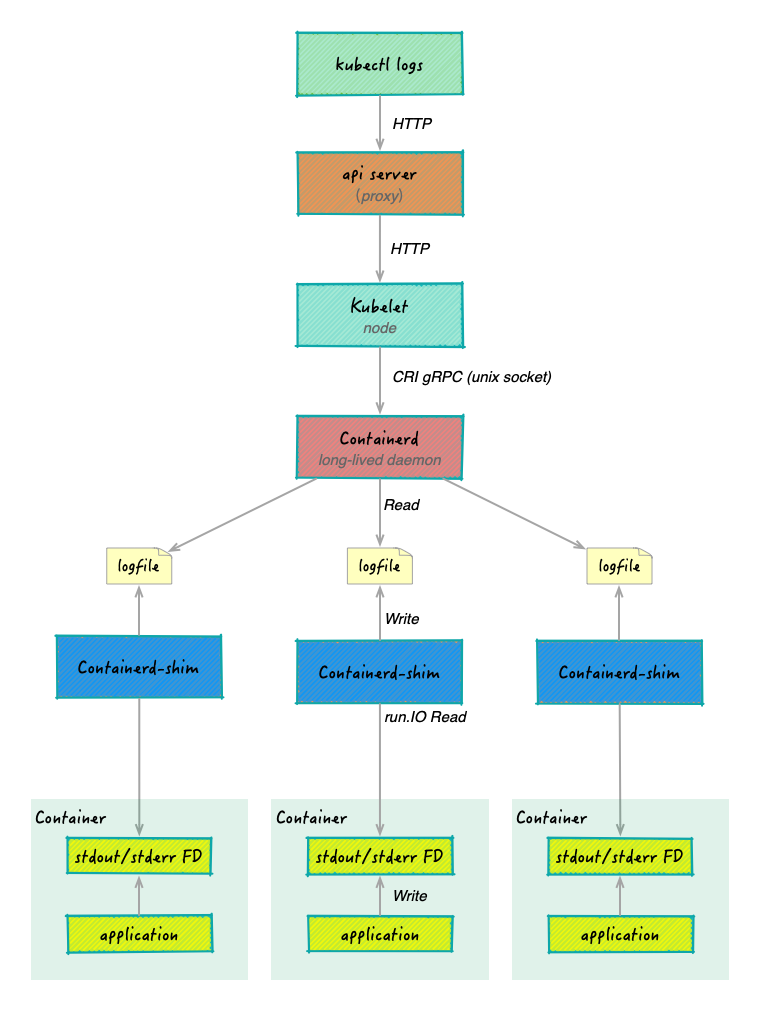
核心概念:CRI、Shim
在深入技术细节之前,我们需要理解三个关键组件。它们构成了容器日志流处理的基础架构。
CRI:Container Runtime Interface
CRI 是 Kubernetes 与容器运行时之间的标准接口。它的出现解决了一个关键问题:如何让 Kubernetes 支持多种容器运行时,而不需要为每个运行时编写专门的集成代码? 关于 CRI 的详细介绍,可以浏览我之前的文章 Kubernetes 容器运行时接口 CRI。
在日志处理的语境下,CRI 定义了:
- Kubelet 如何请求容器的日志流
- 容器运行时应该以什么格式返回日志
- 日志存储位置的约定
这种标准化意味着,无论你使用 Containerd、CRI-O 还是其他容器运行时,Kubelet 都能用同样的方式获取容器日志。
Container Shim:隐形的 I/O 管家
Shim 是容器运行时架构中最容易被忽视,却至关重要的一层。它的职责包括:
- 解耦运行时和容器进程:即使 containerd 重启,容器进程依然运行
- I/O 流管理:处理容器的 stdin/stdout/stderr 流
- 生命周期管理:监控容器进程,报告退出状态
在日志处理中,Shim 负责:
- 从容器进程读取 stdout/stderr 输出(通过
io.CopyBuffer) - 格式化日志(添加时间戳、流类型)
- 直接写入日志文件(
/var/log/pods/...)
关键理解:
- Shim 完成所有工作:读取、格式化、写入
- Kubelet 直接读文件:不通过 CRI 接口
Runc
在 Containerd 的下层,是 Runc——真正负责启动和管理容器进程的 OCI Runtime。理解 Runc 如何设置 I/O 重定向,能让我们看到整个机制的最底层实现。
在日志流处理的链路中,Runc 的职责非常明确:
- 创建容器进程
- 将容器进程的 stdout/stderr 重定向到指定的文件描述符
- 确保 I/O 管道在容器启动时正确连接
Containerd、Runc、Shim 的协作
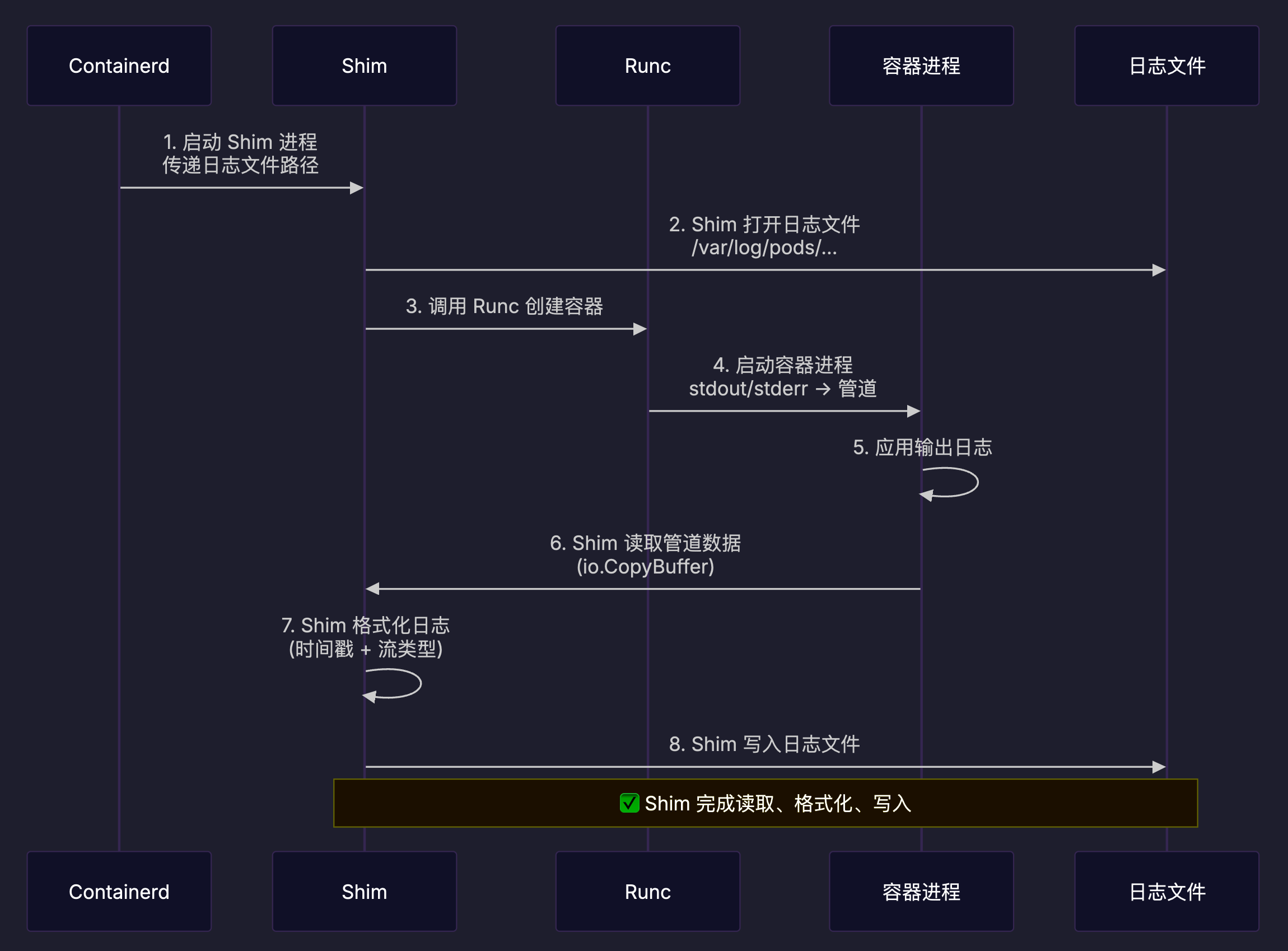
Containerd 的日志写入实现
Containerd 作为目前 Kubernetes 生态中最主流的容器运行时,它的日志处理实现具有代表性。让我们深入看看它是如何一步步处理容器的输出流的。
Shim 直接写入日志文件
在 Kubernetes 场景中,Containerd Shim 进程直接负责日志的读取、格式化和写入。
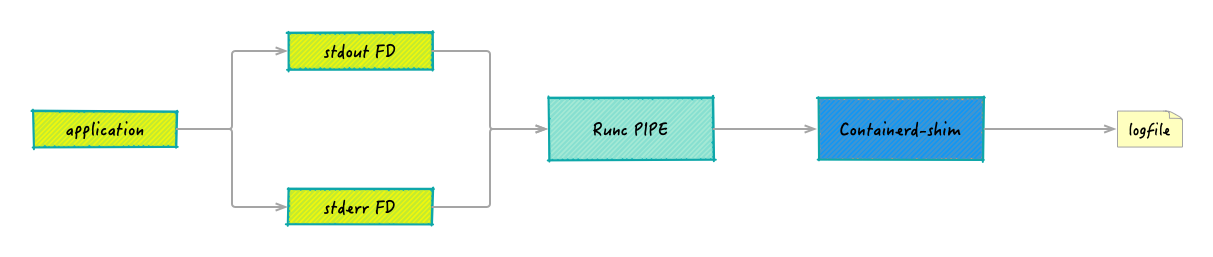
数据流转路径:
- 容器进程输出:应用程序向 stdout/stderr 文件描述符写入数据
- Runc 管道:Runc 将容器的 stdout/stderr 重定向到管道
- Shim 读取:Shim 通过
io.CopyBuffer从管道读取数据 - Shim 格式化:为每行日志添加 CRI 格式元数据
- Shim 写入:直接写入日志文件
/var/log/pods/...
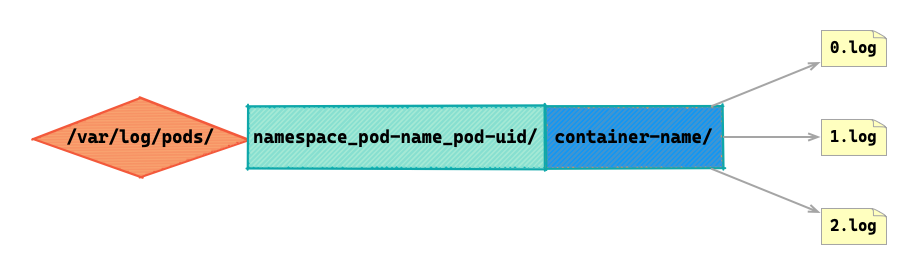
日志文件格式:/var/log/pods/{namespace}_{pod-name}_{pod-uid}/{container-name}/{restart-count}.log。日志文件的路径和文件名,由 Containerd 指定并通知 Shim。
参考源码:
- 创建日志文件和管道 IO:/cmd/containerd-shim-runc-v2/process/io.go#L110
- 打开文件写入器:/cmd/containerd-shim-runc-v2/process/io.go#L201
- 读取管道数据并格式化后写入:/cmd/containerd-shim-runc-v2/process/io.go#L149
完整的容器日志数据流
日志软链接
软链接(Symbolic Link)是一种特殊的文件,它包含指向另一个文件或目录的路径。类似于 Windows 中的“快捷方式”。
在 Kubernetes 容器日志的场景中:
- 实际日志文件位置(目标文件):
/var/log/pods/{namespace}_{pod-name}_{pod-uid}/{container-name}/{restart-count}.log - 软连接位置:
/var/log/containers/{pod-name}_{namespace}_{container-name}-{container-id}.log
为什么要使用日志软链接?
实际日志文件:按 Pod UID 组织,目录结构清晰;包含容器重启次数(0, 1, 2…);容器每次重启创建新的日志文件。但是路径太长,而且要先查到 Pod UID 才能找到日志,随机的 UDI 也不便于人工查看。
软链接:路径简短,易于理解;包含可读的元数据(Pod 名、命名空间、容器名);所有日志在同一目录,便于通配符匹配。尤其是最后一点,更方便日志收集工具(Fluentd/Fluent Bit)发现和解析,包含了容器 ID 便于关联。
Kubernetes 集成:从 Kubelet 到 kubectl logs
理解了 Containerd 和 Runc 如何处理容器输出后,让我们看看 Kubernetes 如何将这些日志暴露给用户。
日志文件的路径约定和可视化
上面我们介绍了日志文件的标准路径结构,实际上这是一种可视化的路径结构。
kubectl logs 请求的完成流程
kubectl 客户端层
容器日志的查看命令:
kubectl logs <pod-name> -c <container-name> --follow --tail=100
kubectl 客户端解析命令行参数、验证并构建请求,向 kube-apiserver 发起 HTTP 流式请求。
参考源码:/staging/src/k8s.io/kubectl/pkg/polymorphichelpers/logsforobject.go#L127
kube-apiserver 层
API 端点:
GET /api/v1/namespaces/{ns}/pods/{pod}/log?container={name}&follow=true&tailLines=100...
apiserver 收到请求、验证参数,然后构建 kubelet URL:通过 Pod 所在的节点信息,获取 kubelet 的连接信息(IP、端口、TLS),构建 kubelet 日志 URL:
https://{node-ip}:10250/containerLogs/{namespace}/{pod}/{container}?follow=true×tamps=true&tailLines=100...
然后 apiserver 将请求反向代理到 kubelet。
参考源码:/pkg/registry/core/pod/strategy.go#L660
kubelet 层
API 端点:
GET https://{node-ip}:10250/containerLogs/{namespace}/{pod}/{container}
kubelet :
- 解析 URL 参数可以获取到 namespace、podID、containerName
- 验证参数和 Pod、Container 存在
- 验证容器状态,获取 containerID
- 调用 CRI 获取容器状态,进而获取日志文件路径
- 读取日志转换格式
参考源码:
- /pkg/kubelet/server/server.go#L739
- /pkg/kubelet/kubelet_pods.go#L1579
- /pkg/kubelet/kuberuntime/kuberuntime_logs.go#L36
性能与配置优化
理解了整个流程后,我们可以针对性地优化日志处理的性能。
高吞吐量场景的优化
比如应用程序每秒输出大量日志(如高并发 Web 服务的访问日志)高吞吐量场景。
经常可见问题:
- 磁盘 I/O 成为瓶颈
- 日志轮转过于频繁
- CPU 占用高(格式化、时间戳计算)
优化策略:
- 调整日志文件大小和数量(kubelet 配置)
- 使用更快的磁盘(将
/var/log/pods挂载到 SSD 或 NVMe 盘) - 减少日志输出(属于应用层优化,比如降低日志级别)
- 禁用时间戳(如果不需要精确时间戳,可以减少 CPU 开销)
日志行长度限制调优
应用程序输出大量长日志(如 JSON 对象)的场景。
常见问题:
- 超过 16KB 的日志被分割成多行
- 日志收集工具(Fluentd)解析困难
解决方案:
- 增加行长度限制(containerd 配置)
- 应用层分行输出
总结
从应用程序的 printf() 或 console.log(),到你在终端看到的日志,这条路径经历了多层抽象和精心设计的机制。
理解这条路径上的每一个环节,你就能:
- 快速定位日志问题的根源
- 合理配置以优化性能
- 设计可靠的日志收集架构
- 在关键时刻不慌乱地排查故障
从最初对容器日志底层机制的好奇,到现在对整个流程的深入理解,这个探索过程不仅解答了我的疑问,也希望能帮助到同样对这个话题感兴趣的你。



