
Google ADK 深度探索(三):Agent 架构——从单一职责到多智能体协作
1. 引言
在 上一篇文章 中,我们深入探讨了 Google ADK 的 Context 机制——UserContext、SessionContext、AgentContext 解决了智能体 " 记住什么 " 的问题。但一个完整的 Agent 系统还需要回答另一个核心问题:" 如何行动 “。
如果说 Context 是 Agent 的 " 记忆 “,那么 Agent 就是 " 大脑 “。ADK 通过代码优先的设计哲学,让开发者用 Python 直接定义 Agent 的身份、使命、工具和协作关系——并通过 sub_agents 将多个 Agent 组合成层次化团队。本文将从单一 Agent 的核心要素出发,逐步解析 Multi-Agent 协作模式,帮你掌握构建可组合、可生产部署的多智能体系统的思维框架。
2. Google ADK 中的 Agent 概念
Agent = 目标驱动的执行单元
在传统软件架构中,函数是确定性的:给定相同的输入,总是产生相同的输出。而 Agent(智能体) 则不同——它的本质是从 " 执行指令 " 升级为 " 理解目标 “。开发者不再需要编写 if-else 来覆盖所有分支,而是定义 Agent 的使命(instruction)和能力(tools),让 LLM 在运行时推理出最佳执行路径。这种从确定性执行到推理式决策的转变,正是 Agent 区别于传统软件组件的核心。
Google ADK 的 Agent 设计哲学
Google ADK 在设计 Agent 时遵循三个核心原则:
1. Agent 是一等公民(与 Context 并列)
Context 负责 " 记住什么 “,Agent 负责 " 做什么 “。两者通过 InvocationContext 在运行时建立联系——每个 Agent 被调用时会创建一个 InvocationContext 对象,持有当前会话的状态、用户信息、工件存储等上下文数据。
2. 代码优先:Agent 即代码,而非配置文件
传统 AI 框架喜欢用 YAML/JSON 定义 Agent,但配置文件难以版本控制,且缺乏类型检查。ADK 反其道而行之:
# ✅ ADK 方式:一切都是 Python 对象
from google.adk.agents import Agent
import models
reviewer = Agent(
model=models.moonshot,
name="code_reviewer",
instruction="你是一个严格的代码审查者",
tools=[run_linter, check_security]
)
# ❌ 传统方式:配置文件 + 运行时解析
# agent_config.yaml:
# name: reviewer
# instruction: "你是一个严格的代码审查者"
# ...
3. 组合优于继承:通过 sub_agents 构建复杂系统
ADK 不鼓励继承 LlmAgent 来扩展功能,而是通过 sub_agents 参数组合多个 Agent:
# 团队负责人 Agent
team_lead = Agent(
model=models.moonshot,
name="lead",
instruction="协调代码审查流程",
sub_agents=[
quality_checker, # 质量检查
security_auditor, # 安全审计
performance_tester # 性能测试
]
)
这种设计让每个 Agent 保持单一职责,通过组合实现复杂协作。
Agent 的核心要素
一个 ADK Agent 通过以下参数定义其 " 人格 “:
from google.adk.agents import Agent
import models
code_reviewer = Agent(
model=models.moonshot, # 大脑:用哪个模型推理
name="code_reviewer", # 身份:我是谁
instruction="审查代码质量和安全性", # 使命:我该做什么
description="负责代码审查", # 职责:我能做什么(给其他 Agent 看)
tools=[run_linter], # 能力:我有哪些工具
sub_agents=[security_agent] # 团队:我管理哪些下属
)
每个参数都有明确的语义边界:
- model:指定推理使用的大语言模型
- name:Agent 的唯一标识符,用于日志追踪和调用
- instruction:内部使命,直接注入到 LLM 的 system prompt
- description:外部职责说明,父 Agent 通过此字段决定何时调用它
- tools vs sub_agents:工具是 " 手 “(确定性执行),sub_agent 是 " 同事 “(推理式协作)

特别注意:Agent 定义中不包含
context参数,Context 是运行时通过InvocationContext注入的。这让 Agent 保持无状态,可以在不同会话中复用。
3. 环境搭建
前置要求
- Python 3.10+(推荐 3.11 或 3.12)
- pip 或 uv(推荐使用 uv,速度更快)
- API Key:Moonshot AI 或 DeepSeek 的 API 密钥
安装 ADK
# 使用 pip
pip install google-adk
# 或使用 uv(推荐)
uv pip install google-adk
创建 Agent 项目
ADK 推荐使用以下项目结构组织代码:
mkdir my_agent && cd my_agent
touch agent.py .env __init__.py
my_agent/
agent.py # 主 Agent 代码
.env # API 密钥配置
__init__.py
配置模型与 root_agent
在 agent.py 中定义 root_agent:
from google.adk.agents import Agent
from google.adk.models import LiteLlm
moonshot = LiteLlm(model="moonshot/moonshot-v1-128k")
root_agent = Agent(
model=moonshot,
name="greeter",
description="A friendly assistant",
instruction="你是一个友好的助手,请简洁地回答问题",
)
root_agent是 ADK 的约定入口——adk run命令会自动查找这个变量作为启动点,无需额外配置。
设置环境变量
# .env
MOONSHOT_API_KEY=sk-xxxx
MOONSHOT_API_BASE=https://api.moonshot.cn/v1
# 或 DeepSeek
DEEPSEEK_API_KEY=sk-xxxx
运行 Agent
ADK 提供两种运行方式,按需选择:
命令行适合快速验证逻辑;Web UI 适合调试多 Agent 调用链路。
方式 1:命令行界面
# 从父目录运行
cd ..
adk run my_agent
方式 2:Web 界面
adk web --port 8888 --reload_agents
访问 http://localhost:8888,可以可视化查看 Agent 调用链路、Context 状态和工具调用详情。
--reload_agents让你修改代码后无需重启即可生效,开发阶段强烈推荐加上。
注意:
adk web需要从包含my_agent/的父目录运行。
4. 第一个 Agent:代码审查助手
环境搭建完成后,让我们构建一个具有实际价值的 Agent——代码审查助手。
核心观察:你不需要告诉 Agent " 先调用工具 A,再调用工具 B”。Agent 会根据使命自己推理出需要调用哪些工具、以什么顺序调用——这正是 Agent 与传统函数的本质区别:目标驱动而非指令驱动。
为 Agent 添加工具
Agent 的智能来自 LLM,但其能力边界由工具(tools) 定义。工具是普通的 Python 函数,Agent 会在需要时自动调用它们。
创建 code_reviewer/agent.py:
from google.adk.agents import Agent
from google.adk.models import LiteLlm
moonshot = LiteLlm(model="moonshot/moonshot-v1-128k")
# 工具 1:代码风格检查
def check_code_style(code: str, language: str) -> dict:
"""检查代码风格是否符合规范"""
issues = []
if language == "python":
if "import *" in code:
issues.append("避免使用 'import *',应明确导入")
if not code.strip().endswith("\n"):
issues.append("文件应以换行符结尾")
return {
"status": "success" if not issues else "warning",
"issues": issues,
"checked_lines": len(code.split("\n"))
}
# 工具 2:安全漏洞扫描
def scan_security(code: str) -> dict:
"""扫描常见安全问题"""
vulnerabilities = []
if "eval(" in code:
vulnerabilities.append("发现 eval() 调用,存在代码注入风险")
if "password" in code.lower() and "=" in code:
vulnerabilities.append("检测到硬编码密码,建议使用环境变量")
return {
"status": "critical" if vulnerabilities else "safe",
"vulnerabilities": vulnerabilities
}
root_agent = Agent(
model=moonshot,
name="code_reviewer",
description="专业代码审查助手,检查代码风格和安全问题",
instruction="""你是一个严格但友好的代码审查者。
职责:
1. 使用 check_code_style 工具检查代码风格
2. 使用 scan_security 工具扫描安全漏洞
3. 综合两个工具的结果,给出清晰的审查报告
报告格式:
- 代码风格:[问题列表或"无问题"]
- 安全检查:[漏洞列表或"无漏洞"]
- 建议:[具体改进建议]
""",
tools=[check_code_style, scan_security]
)
工具设计的关键点
1. 类型注解是必需的
ADK 会解析函数签名生成工具描述,供 LLM 理解参数类型和用途:
def check_code_style(code: str, language: str) -> dict:
"""检查代码风格是否符合规范"""
2. Docstring 是工具说明书
LLM 通过 docstring 决定何时调用这个工具,写得越清晰,调用越准确:
def scan_security(code: str) -> dict:
"""扫描常见安全问题""" # ← LLM 看到这个描述决定是否调用
3. 返回结构化数据
返回 dict 让 LLM 能精确引用具体字段,而不是从字符串里猜测结果:
# ✅ 推荐
return {"status": "warning", "issues": ["问题1", "问题2"]}
# ❌ 不推荐
return "发现 2 个问题:问题1,问题2"
测试 Agent
配置好 .env 后运行:
adk run code_reviewer
测试 1:干净的代码
你: 帮我审查这段代码:
import os
def get_config():
return os.getenv("API_KEY")
Agent: [调用 check_code_style] [调用 scan_security]
审查报告:
- 代码风格:✅ 无问题
- 安全检查:✅ 无漏洞
- 建议:代码规范,使用环境变量管理敏感信息,符合最佳实践。
测试 2:有问题的代码
你: 审查:
from os import *
password = "admin123"
eval(input())
Agent: [调用 check_code_style] [调用 scan_security]
审查报告:
- 代码风格:
⚠️ 避免使用 'import *',应明确导入
- 安全检查:
🚨 发现 eval() 调用,存在代码注入风险
🚨 检测到硬编码密码,建议使用环境变量
- 建议:
1. 将 'from os import *' 改为明确导入
2. 移除 eval(),使用 ast.literal_eval 或其他安全方式
3. 将密码移到环境变量或密钥管理系统
注意:Agent 自己推理出需要同时调用两个工具才能完成完整审查——你只告诉了它 " 使命 “,没有规定执行步骤。
5. 工具生态系统:扩展 Agent 能力
Agent 的能力边界由工具定义。ADK 支持三种工具来源,可以灵活组合。
自定义函数——业务特定逻辑
最灵活的方式,用普通 Python 函数定义:
def check_code_style(code: str, language: str) -> dict:
"""检查代码风格是否符合规范"""
# 你的业务逻辑
return {"issues": [...], "count": 10}
最佳实践:
- 添加详细的 docstring(LLM 用它理解工具用途)
- 使用类型注解(
str、int、dict等) - 返回结构化数据(
dict优于纯字符串) - 做好错误处理(返回错误信息而非抛异常)
OpenAPI 工具——集成第三方 API
从 OpenAPI 规范自动生成工具,无需手写集成代码。适合对接有标准 API 文档的服务(如 GitHub、Jira、Stripe 等):
from google.adk.tools.openapi_tool import OpenAPIToolset
# 示意代码,spec_str 替换为实际 OpenAPI 规范内容
github_tools = OpenAPIToolset(
spec_str='{"openapi": "3.0.0", "...": "..."}',
spec_str_type="json"
)
agent = Agent(
model=moonshot,
name="github_bot",
tools=github_tools.get_tools()
)
ADK 会自动解析规范文件,将每个 API endpoint 转换为 LLM 可调用的工具,省去手写 wrapper 的工作。
MCP 工具——接入通用工具生态
MCP(Model Context Protocol) 是 Anthropic 主导的开放协议,定义了 LLM 与外部工具交互的标准方式。ADK 原生支持 MCP,可以直接接入整个 MCP 生态:
from google.adk.tools.mcp_tool import McpToolset
from google.adk.tools.mcp_tool.mcp_toolset import StreamableHTTPConnectionParams
mcp_tools = McpToolset(
connection_params=StreamableHTTPConnectionParams(
url="https://your-mcp-server-url/mcp",
headers={"Authorization": "Bearer your-auth-token"}
)
)
agent = Agent(
model=moonshot,
name="agent_with_mcp",
tools=mcp_tools.get_tools()
)
与自定义函数相比,MCP 工具的优势在于可复用性——文件系统、数据库、Git、Slack 等数百个现成工具开箱即用,不需要自己实现。
如何选择?
| 工具类型 | 适用场景 | 典型例子 |
|---|---|---|
| 自定义函数 | 业务特定逻辑、内部系统 | 查询公司数据库、调用内部 API |
| OpenAPI 工具 | 有标准 API 文档的第三方服务 | GitHub、Jira、Stripe |
| MCP 工具 | 通用能力、优先复用现有生态 | 文件读写、Git 操作、Slack 消息 |
实践建议:先看 MCP 生态有没有现成的,没有再考虑 OpenAPI,最后才自己写函数。
6. Multi-Agent 协作:从单兵到团队
单个 Agent 适合处理明确的单一任务。但现实场景往往更复杂——就像一个人很难同时是代码质量专家、安全审计专家和性能优化专家。ADK 通过 sub_agents 参数让多个 Agent 组成协作团队,每个成员各司其职。
sub_agents:动态委派
机制说明:父 Agent 不需要显式调用子 Agent,没有 call_sub_agent() 这样的函数。LLM 通过读取每个子 Agent 的 description 字段,自己推理出 " 这个任务应该交给谁 “。这意味着 description 写得越清晰,委派越准确。
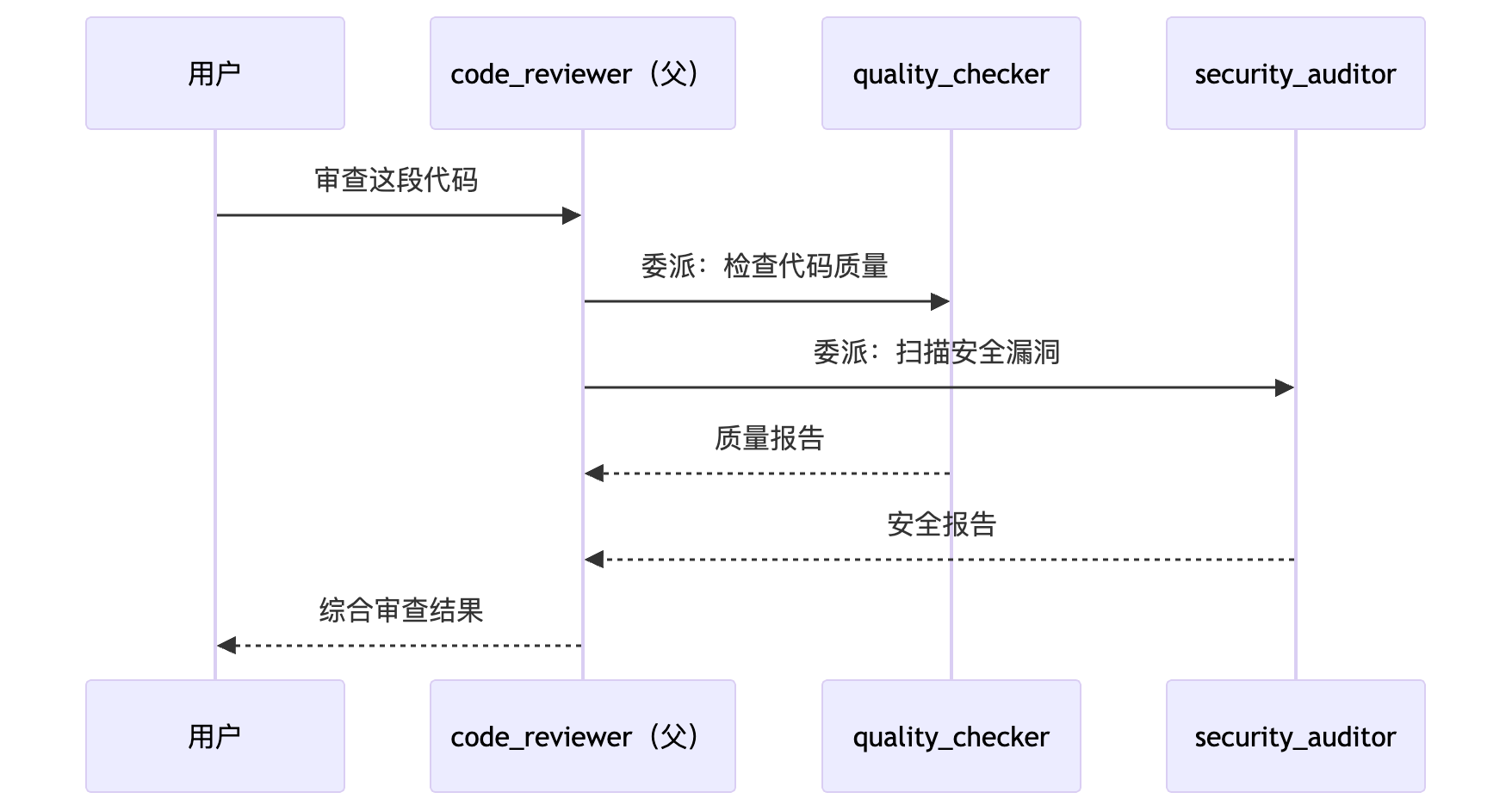
from google.adk.agents import Agent
from google.adk.models import LiteLlm
moonshot = LiteLlm(model="moonshot/moonshot-v1-128k")
# 子 Agent 1:代码质量检查
# description 要具体,父 Agent 靠它决定何时委派
quality_checker = Agent(
model=moonshot,
name="quality_checker",
description="检查代码质量和风格规范", # ← 清晰的职责边界
instruction="分析代码可读性、命名规范、注释完整性",
tools=[check_code_style]
)
# 子 Agent 2:安全审计
security_auditor = Agent(
model=moonshot,
name="security_auditor",
description="扫描 SQL 注入、XSS、硬编码密码等安全漏洞", # ← 具体到漏洞类型
instruction="识别常见安全问题并给出修复建议",
tools=[scan_security]
)
# 父 Agent:协调者
code_reviewer = Agent(
model=moonshot,
name="code_reviewer",
description="代码审查协调者,统筹质量检查和安全审计流程",
instruction="""你是代码审查的协调者。
工作流程:
1. 将代码质量检查任务委派给 quality_checker
2. 将安全审计任务委派给 security_auditor
3. 综合两者报告,生成最终审查结果
注意:如发现严重安全问题,优先级高于代码风格问题。
""",
sub_agents=[quality_checker, security_auditor]
)
SequentialAgent:有序流水线
当任务之间有依赖关系,需要按固定顺序执行时,使用 SequentialAgent——前一个 Agent 的输出自动作为下一个的输入:
from google.adk.agents.sequential_agent import SequentialAgent
step1_analyzer = Agent(
model=moonshot,
name="analyzer",
description="分析需求文档,提取关键需求和约束",
instruction="提取核心需求和约束条件"
)
step2_designer = Agent(
model=moonshot,
name="designer",
description="根据需求设计技术方案和接口",
instruction="设计架构和接口定义"
)
step3_reviewer = Agent(
model=moonshot,
name="reviewer",
description="评审方案可行性,识别技术风险",
instruction="评估技术风险和实现难度"
)
workflow = SequentialAgent(
name="requirement_workflow",
description="需求分析 → 方案设计 → 可行性评审",
sub_agents=[step1_analyzer, step2_designer, step3_reviewer]
)
ParallelAgent:并行提速
当任务之间相互独立时,使用 ParallelAgent 同时执行,等所有结果返回后再继续:
from google.adk.agents.parallel_agent import ParallelAgent
ci_pipeline = ParallelAgent(
name="ci_checks",
description="CI 流水线:代码检查 + 类型检查 + 测试同时运行",
sub_agents=[lint_checker, type_checker, test_runner]
)
这三种模式可以嵌套组合:比如用
SequentialAgent串联多个阶段,每个阶段内部用ParallelAgent并行执行独立检查。
三种模式对比
| 模式 | 执行方式 | 适用场景 |
|---|---|---|
| sub_agents | LLM 推理决定委派 | 任务边界模糊、需要动态决策 |
| SequentialAgent | 按顺序依次执行 | 步骤有依赖、前序输出是后序输入 |
| ParallelAgent | 同时执行 | 任务相互独立、需要缩短总耗时 |
两条核心设计原则
1. 单一职责——每个 Agent 只做一件事:
# ✅ 好
quality_checker = Agent(description="检查代码质量")
security_auditor = Agent(description="扫描安全漏洞")
# ❌ 不好
super_agent = Agent(description="检查质量、安全、性能、文档...")
2. description 要具体——父 Agent 靠它选人,写得越精准,委派越准确:
# ✅ 好
Agent(description="扫描 SQL 注入、XSS、硬编码密码等安全漏洞")
# ❌ 不好
Agent(description="处理安全相关的事情")
其他注意事项:避免循环依赖(A 是 B 的父,同时又是 B 的子);协作层级建议不超过 3 层,否则调试成本会急剧上升。
7. 状态管理与上下文传递
Agent 有了协作能力之后,下一个问题自然浮现:状态如何在 Agent 之间传递? 这正是 ADK Context 机制的核心职责。
状态的层级关系
ADK 通过 Session.state 的前缀机制和 InvocationContext 管理不同作用域的状态:
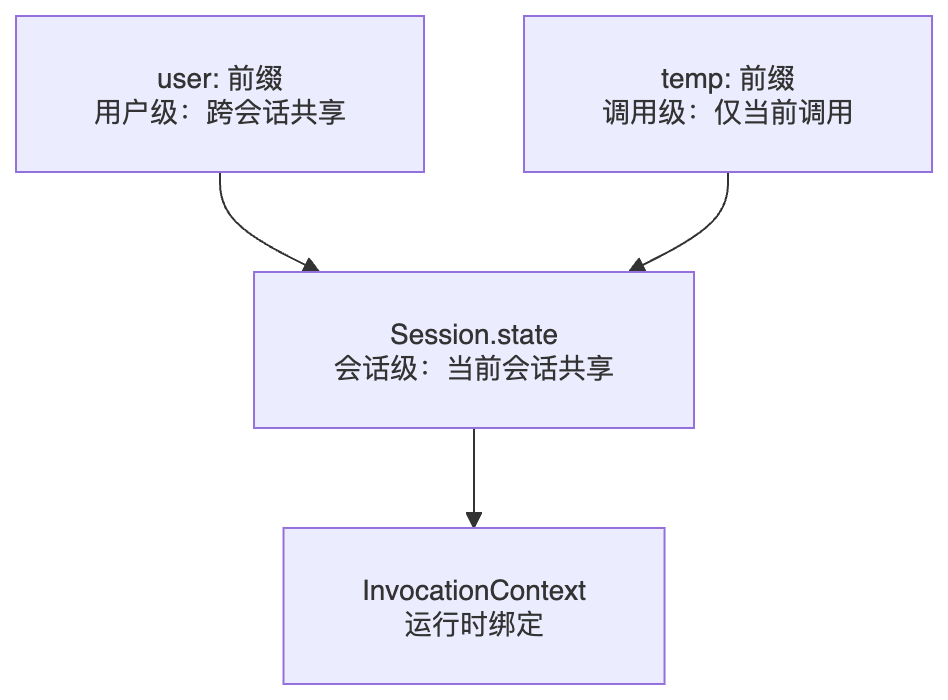
- 用户级状态(
user:前缀):跨会话共享,存用户偏好、历史设置 - 会话级状态(无前缀):当前会话内共享,存任务进度、上传文件列表
- InvocationContext:单次调用内,绑定 Agent、Session 和各类 Service,是运行时的核心上下文
运行时通过 InvocationContext 绑定,Agent 通过它访问所有层级的状态。
状态前缀:控制数据作用范围
Session.state 支持通过前缀声明数据的归属范围——这是 ADK 状态管理最精妙的设计之一:
# 通过 SessionService 创建 Session
session_service = InMemorySessionService()
session = await session_service.create_session(
app_name="my_app", user_id="u1"
)
session.state["progress"] = "50%" # 无前缀:当前会话
session.state["user:theme"] = "dark" # user: 跨会话保留
session.state["app:version"] = "1.0" # app: 全局配置
session.state["temp:file_content"] = "..." # temp: 仅当前调用
一句话记住:
| 前缀 | 生命周期 | 典型用途 |
|---|---|---|
| 无前缀 | 当前会话 | 购物车、任务进度 |
user: | 跨会话 | 语言偏好、主题设置 |
app: | 全局 | API 端点、功能开关 |
temp: | 当前调用 | 中间结果、临时缓存 |
在工具中访问 Context
Agent 的工具函数可以通过 ToolContext 参数访问运行时上下文。ADK 会自动识别参数类型并注入:
from google.adk.tools.tool_context import ToolContext
def analyze_with_context(tool_context: ToolContext) -> str:
"""读取 Context 状态"""
# 通过 tool_context.state 直接访问 session state
lang = tool_context.state.get("user:language_preference", "en")
# 读取会话状态
files = tool_context.state.get("files_uploaded", [])
return f"已处理 {len(files)} 个文件,语言:{lang}"
Multi-Agent 中的状态传递
子 Agent 自动继承父 Agent 的 InvocationContext,可以直接读取父 Agent 写入的状态:
# 父 Agent 写入
parent_agent = Agent(
instruction="""协调代码审查流程。
将上传的文件列表保存到 session.state['files'],
子 Agent 会自动读取并处理。
""",
sub_agents=[quality_checker, security_auditor]
)
# 子 Agent 读取(无需显式传参)
quality_checker = Agent(
instruction="从 session.state['files'] 读取文件列表并检查质量"
)
注意:子 Agent 应只读取父 Agent 设置的状态,避免直接修改全局 state。原因是:当多个子 Agent 并行运行时,同时写入同一个 key 会产生竞争条件,导致状态不一致。
工件存储:处理大数据
对于文件内容、图片、生成报告等大体积数据,使用 ArtifactService 而非 session.state:
from google.adk.tools.load_artifacts_tool import load_artifacts_tool
file_analyzer = Agent(
model=moonshot,
name="analyzer",
instruction="使用 load_artifacts_tool 加载用户上传的文件并分析",
tools=[load_artifacts_tool]
)
选择依据:
| 数据类型 | 存储方式 |
|---|---|
| 文件名、进度、偏好设置 | session.state |
| 文件内容、图片、生成报告 | ArtifactService |
状态管理最佳实践
1. 明确前缀,避免作用域混淆
# ✅ 好
session.state["user:theme"] = "dark" # 明确是用户偏好
# ❌ 不好
session.state["theme"] = "dark" # 会话结束就丢失了
2. 临时数据用 temp: 前缀
# ✅ 好
session.state["temp:intermediate"] = {...} # 调用结束自动清理
# ❌ 不好
session.state["intermediate"] = {...} # 污染会话状态
3. 用 state 记录推理链路
tool_context.state["temp:step_progress"] = "步骤 1:加载文件完成,发现 3 个问题"
# temp: 前缀确保仅在当前调用中可见,不会污染会话状态
# 在 adk web 中可以通过 session state 查看调试信息
8. 结语
一个思维模式的转变
ADK 带来的最大改变,不是 API 层面的,而是思考问题的方式:
# 传统方式:显式控制每一步
if "quality" in request:
check_quality()
if "security" in request:
check_security()
combine_results()
# ADK 方式:声明目标,让 Agent 推理路径
Agent(
instruction="审查代码质量和安全性",
sub_agents=[quality_checker, security_auditor]
)
你不再需要编写所有分支,而是定义能力边界(tools)和协作关系(sub_agents),剩下的交给 LLM 推理。Context 管 " 记什么 “,Agent 管 " 做什么 “,两者通过 InvocationContext 在运行时咬合——这就是 ADK 的完整拼图。
本系列文章:
- Google ADK 深度探索(一):高效的上下文感知多智能体框架
- Google ADK 深度探索(二):不同语境下的专用上下文对象
- Google ADK 深度探索(三):Agent 架构——从单一职责到多智能体协作(本文)



