
Google ADK 深度探索(一):“一等公民”上下文 Context 解析
了解了 Google ADK 宏大的上下文架构设计(回顾上一篇文章),我们不禁要问:这些精妙的思想,最终是如何落地到一行行代码里的?
本文将聚焦 ADK 中作为“一等公民”的上下文(Context)机制,详解其如何通过会话状态、数据传递、服务访问等核心功能,解决智能体开发中的状态维护、跨步骤协作和资源调度难题。无论是管理用户偏好的 session.state,还是按需加载的工件存储,抑或是身份跟踪的 InvocationContext,ADK 的上下文设计无不体现着一种理念:智能体的能力边界,本质上取决于其上下文管理的精度与效率。
上下文(Context)
在智能体开发领域,一个日益凸显的挑战是上下文管理的复杂性。传统方法(如无限制地堆叠聊天历史或工具输出)会导致成本飙升、信号衰减甚至物理性性能瓶颈。而 ADK 的突破性在于——它将上下文从“被动拼接的文本”升级为系统化管理的架构核心,通过分层设计、动态编译和最小权限原则,实现了生产级智能体的高效运作。
在 ADK 中,上下文(Context)指的是智能体及其工具在特定操作期间所能获取的关键信息。它也是有效处理当前任务或者会话所需的必要背景知识和资源。
智能体有效运行需要的不只是最新的用户消息,上下文至关重要,通过上下文可以:
维护状态
存储对话过程中多个步骤的详细信息(例如,用户偏好、上一步的结果),这些都通过**会话状态(session.state)**来管理。
会话(Session)在 ADK 中是一个重要的概念,用于跟踪独立的对话。用户第一次与智能体交互时会创建一个 Session 对象,这个对象作为一个容器保存了与对话相关所有状态:
- 历史记录(
session.events):与该对话相关的所有交互,包括用户输入、智能体响应、工具调用请求/结果等。记录的事件序列提供了交互的完整、按时间顺序的历史记录,对于调试、审计和逐步了解代理行为非常有价值。这些信息是不可变的,是由框架自身维护的。 - 会话状态(
session.state):从数据结构上看是一个包含键值对的集合(字典或者 Map),用于存储智能体有效执行需要用到的信息,比如记录用户偏好、跟踪多轮流程中的步骤、收集信息等。session.state是可变的。
会话可以保存在内存(InMemorySessionService)、数据库(DatabaseSessionService、SqliteSessionService、PerAgentDatabaseSessionService)中,具体要看使用是哪种 SessionService 的实现了。比如最常见的 InMemorySessionService,从下面这行代码就很容易看出其储存结构了。
#self.sessions: dict[str, dict[str, dict[str, Session]]] = {}
session = self.sessions[app_name][user_id].get(session_id)
除了框架提供的实现外,我们可以通过实现 SessionService 自定义会话的存储方式。
ADK 中除了这几种实现外,还提供了与 VertexAi 兼容的实现。但是需要与平台绑定,这里不做介绍。下文同样与 VertexAi 相关的内容也一并跳过。
数据传递
通过上下文,可以将某一步骤(不管是 LLM 调用还是工具调用)生成的信息与后续的步骤共享。
用的比较多的非 session.state 莫属了。session.state 是可变的,所以我们可以执行的步骤中不断地更新数据,实现记录和共享。
session.state['booking_step'] = 'paid'
session.state['shopping_cart_items'] = ['item1', 'item2']
session.state.get('shopping_cart_items', []).append('te)
这里 booking_step、shopping_cart_items 是键,通常使用清晰明了的名称,比如 language_preference 方便 LLM 理解;存储的值则要求是可序列化的,方便 SessionService 的实现存储和加载。
session.state 中保存的 key 命名上除了提供了清晰的使用场景外,还可以通过前缀来管理其作用范围。
- 无前缀:特定于当前会话,与
session_id绑定,使用场景如跟踪当前任务进度booking_state。 user::特定于某个用户,与user_id绑定,在该用户的所有会话中共享,使用场景如保存用户偏好language_preference。app::特定于某个 app,与app_name绑定,通常用于保存如全局配置等的场景。temp::临时调用状态,特定于当前调用。这里的调用是指智能体从接受用户输入到输出结果的整个过程。ADK 中特别的工作流智能体(Workflow Agents),会编排和控制多个智能体的执行,会出现多个调用。
在 ADK 中提供了多种智能体类型:大模型智能体(
LlmAgent)、工作流智能体(SequentialAgent、LoopAgent、ParalleAgent)、自定义智能体。这几种类型智能体都是BaseAgent的实现。

服务(框架功能)访问
工件(Artifact)存储
工件存储用于存或者加载与会话关联的文件或数据件(可以是 PDF、图像、配置文件等任何类型文件)。文件上传后会作为工件保存,后续需要的时候可以加载到调用中。
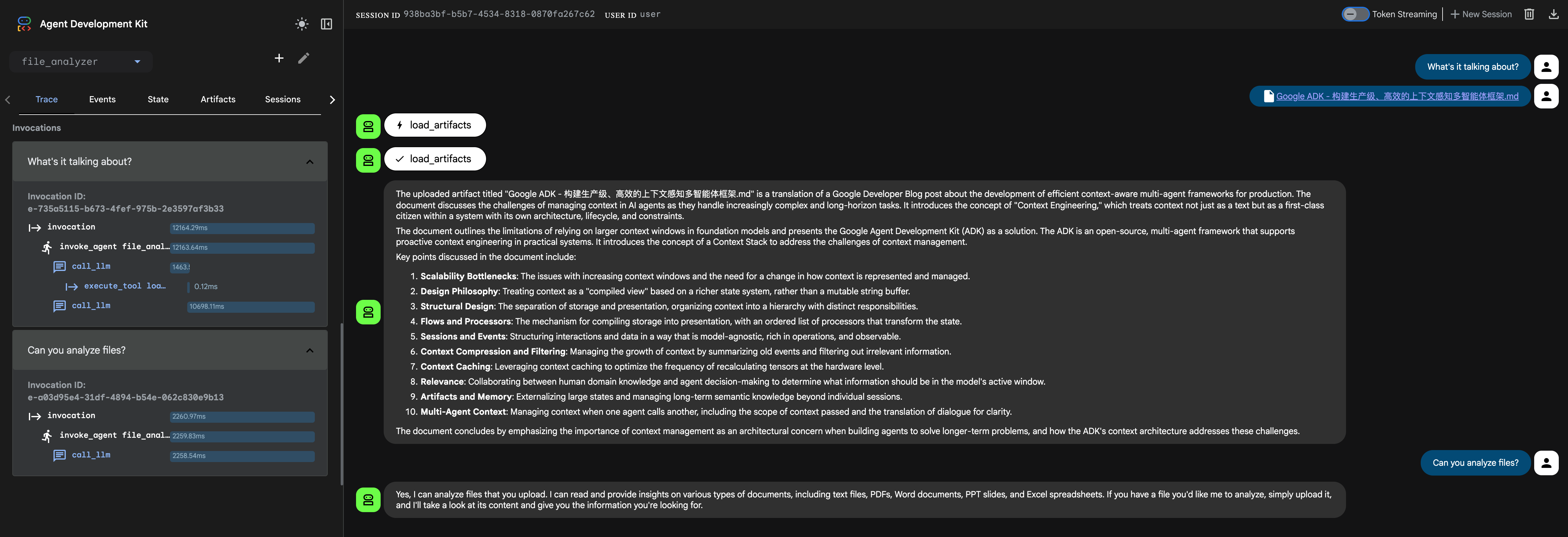
比如,一个分析文件的智能体,在一个会话的连续对话中每次调用 LLM 都会带上文件的内容,即使问的(Can you analyze files?)是与上传的文件不相关的内容。

我们为智能体添加代码使用工件存储功能。智能体只有在必要的时候(对话是与上传的内容相关)才会使用 load_artifacts_tool 工具加载内容发送给 LLM。
from google.adk.agents.llm_agent import Agent
from google.adk.apps import App
from google.adk.plugins.save_files_as_artifacts_plugin import SaveFilesAsArtifactsPlugin
from google.adk.tools.load_artifacts_tool import load_artifacts_tool
import models
file_analyzer_agent = Agent(
model=models.moonshot,
name='file_analyzer_agent',
description='A helpful agent that analyzes files uploaded by users',
instruction="""
You are an assistant that analyzes files uploaded by users. When a user uploads a file, you should analyze its content and provide insights to user. Use `load_artifacts_tool` to get the file content.
""",
tools=[load_artifacts_tool]
)
# To use SaveFilesAsArtifactsPlugin, we need to use it in an App.
app = App(
name='file_analyzer',
root_agent=file_analyzer_agent,
plugins=[SaveFilesAsArtifactsPlugin()]
)
我们可以看到同样的第二轮对话内容,处理时间显著比不使用工件功能少。想象下,我们上传的是体积更大的视频文件,token 的消耗和性能会相当明显。
可能你有注意到第一轮的对话内容增加了,这是因为调用
load_artifacts_tool多了一次 LLM 调用。这额外的一次调用相比大体积的文件带来的 token 消耗和性能影响如九牛一毛。
长期知识(Memory)
ADK 为智能体提供了从过去的交互(同一会话)或者外部长期知识库中搜索信息的能力。这里的长期知识(Long-Term Knowledge)是与前面介绍的会话正好的相对的。
在 ADK 提供的实现 InMemoryMemoryService 中,我们可以看到其将当前会话过去的所有交互信息作为数据源来搜索信息。

身份和跟踪(Identity and Tracking)
通过上下文可以了解当前运行的智能体的信息(agent.name)以及当前调用(invocation)的唯一标识(invocation_id)。
每个智能体被调用时都会先创建一个 InvocationContext 对象,这个对象持有很多有用的信息。
class InvocationContext(BaseModel):
model_config = ConfigDict(
arbitrary_types_allowed=True,
extra="forbid",
)
artifact_service: Optional[BaseArtifactService] = None
session_service: BaseSessionService
memory_service: Optional[BaseMemoryService] = None
credential_service: Optional[BaseCredentialService] = None
context_cache_config: Optional[ContextCacheConfig] = None
invocation_id: str
branch: Optional[str] = None
agent: BaseAgent
user_content: Optional[types.Content] = None
session: Session
agent_states: dict[str, dict[str, Any]] = Field(default_factory=dict)
end_of_agents: dict[str, bool] = Field(default_factory=dict)
end_invocation: bool = False
#...more
InvocationContext 对象中的信息如此之多,但除非需要自定义智能体(实现 BaseAgent)的话,基本不会直接使用。
class BaseAgent(BaseModel):
#...
async def _run_async_impl(self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]:
#...
总结
综上所述,从维护会话状态的 session.state,到实现数据传递的键值存储,再到通过 ArtifactService 和 MemoryService 按需访问资源,ADK 的上下文系统共同构筑了一个清晰、高效的信息流。它们使得智能体能够拥有状态记忆,并在严格的权限控制下与外部资源交互。
值得注意的是,承载这些能力的核心容器是功能强大的 InvocationContext 对象。然而,正如我们所看到的,在绝大多数应用开发场景下,我们无需直接与之打交道。ADK 通过提供如 ToolContext 等更高阶的抽象,将复杂性封装起来。这种“能力完备但接口精简”的设计,正是 ADK 上下文作为“一等公民”的精髓:它既提供了运行所需的全部深度,又为日常开发提供了简单友好的操作界面。
我们下一篇文章将要深入探讨的主题:不同语境下的专用上下文对象。



