
让 AI 自己进化自己:深入 HyperAgents
TL;DR
Meta 开源的 HyperAgents 用 “Agent 训练 Agent” 的思路实现自动进化:meta-agent 观察 task-agent 的表现,直接写代码补丁修改它,循环迭代。用 claude-opus-4.6 实测两个场景,5 代后准确率从 0% 升至 80%;模型越强,进化效果越好——强者恒强。如果说大模型预训练是第一阶段," 训练 Agent" 或许是下一个竞争维度。
一、引子
如果 AI 不只是执行任务,而是能改进自己的执行方式,会发生什么?
2026 年 3 月,Meta 开源了 HyperAgents,一个让 AI agent 自动进化自身的框架。发布一周内 GitHub stars 突破 1200,论文同步挂上 arXiv:《HyperAgents》。
它的核心思路只有一句话:用一个 meta-agent 观察 task-agent 的表现,自动生成代码补丁修改它,循环往复,让 agent 越来越强。
不是手工调 prompt,不是人工设计 few-shot 样本——是 AI 自己写代码改自己。
二、核心架构:双层 Agent
HyperAgents 的架构由两层组成:
task-agent:执行具体任务的 agent。根据任务场景的不同,它可能在判断搜索结果质量、解数学证明题、或者写多语言代码。它是被进化的对象。
meta-agent:观察者和改造者。它读取代码库和历史评分,输出 diff/patch,直接修改 task-agent 的代码。
整个进化循环是这样运转的:
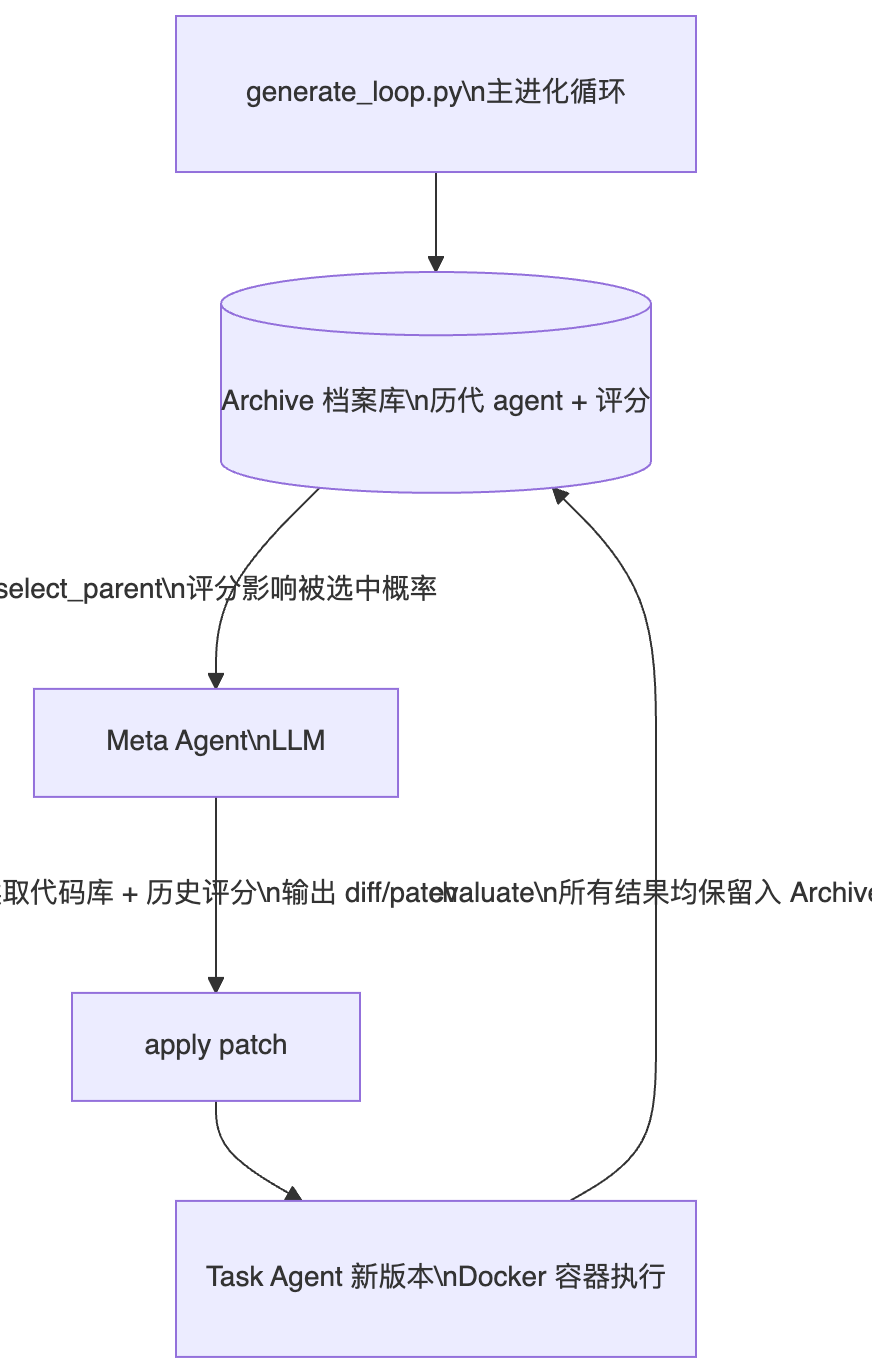
每一代都在 Docker 容器里隔离执行,安全且可复现。Archive 不只保存最优解,而是维护一个多样化的 agent 集合,类比进化算法中的 " 种群 “。
三、进化引擎:它怎么 " 进化 "
3.1 Archive 档案库
Archive 是整个进化的记忆。每一代 agent 跑完评估后,结果和代码都存入 archive.jsonl——JSONL(JSON Lines)格式,每行记录一代 agent 的代码和评分,支持持续追加,读取时也无需加载整个文件。
关键设计:Archive 不做淘汰。所有历史都保留,包括表现差的 agent——低分节点只是在父代选择时被选中的概率降低,但永远不会从种群里删除。这是为了维护种群多样性——过早收敛到一个局部最优,往往意味着进化卡住了。
3.2 评分与选择压力
进化需要 " 选择压力 “,而选择压力来自评分。HyperAgents 针对不同任务场景定义了不同的评分指标:
| 任务场景 | 评分指标 | 含义 |
|---|---|---|
| search_arena / paper_review | overall_accuracy | 判断正确率 |
| polyglot | accuracy_score | 测试用例通过率 |
| balrog | average_progress | 游戏关卡推进程度 |
| genesis | average_fitness | 机器人控制适应度 |
| imo_proof | points_percentage | 数学证明得分百分比 |
评估流程里还有一个重要的设计——Staged Eval(分阶段评估):
- search_arena / paper_review:先用 10% 的样本(约 10 条)快速评估,分数够高才跑完整 100 条
- polyglot:先跑
small.json子集,超过阈值才继续跑medium.json,逐步扩大评估范围
目的都是一样:快速淘汰明显差的 agent,大幅节省 API 调用成本。
3.3 父代选择策略
每一代进化时,meta-agent 需要选一个 " 父代 " 来读取和修改。HyperAgents 提供了 5 种选择策略,默认使用 score_child_prop:
| 策略 | 逻辑 |
|---|---|
best | 选评分最高(贪心) |
latest | 选最新通过编译的 |
random | 完全随机 |
score_prop | 按分数概率采样(sigmoid 归一化) |
score_child_prop | 分数概率 × 子代惩罚(最有意思) |
其中 score_child_prop 的权重公式值得单独看一眼:
weight = sigmoid(score) × exp(-(children/8)³)
子代数量越多,权重被指数衰减惩罚越重。背后的逻辑:如果一个 agent 已经被选为父代很多次,说明它的 " 变体空间 " 可能已经被充分探索了,强迫系统去看看其他分支。
这借鉴了进化算法里的 MAP-Elites / Quality-Diversity 思想:不只追求最优,也要保持多样。
3.4 递归自修改:进化 " 如何进化 "
这是整个框架最骚的设计。
select_next_parent.py——也就是父代选择策略本身——也在 meta-agent 的可修改范围内。启动时加上 --edit_select_parent 参数即可开启:
python generate_loop.py --domains search_arena --edit_select_parent
开启后,系统可以进化出 " 更聪明的父代选择策略 “——自我优化 " 如何自我优化 “,真正的递归自修改。理论上,如果给足够多代,系统可能会涌现出比人工设计的 5 种策略更优秀的选择机制。
四、支持的任务场景
HyperAgents 内置了 6 个任务场景,从易到难:
search_arena — 判断两段搜索结果哪个更好。任务直觉,依赖最少,适合入门。数据来自 HuggingFace lmarena-ai/search-arena-v1-7k。
paper_review — 论文审稿。输入论文全文,输出评审意见,按照判断准确率评分。
polyglot — 多语言编程题(Python / Rust / Go / JavaScript / C++ / Java),每道题在独立 Docker 容器里执行测试验证,深度在 paper_review 之上。
balrog — 游戏/冒险环境中的 agent 行为,包含 BabyAI、BabaIsAI、MiniHack、NetHack 等多个子场景,按关卡推进程度评分。
imo — 数学竞赛题,分两种模式:imo_grading(判题)和 imo_proof(生成证明),均需要配套 proof grader,门槛高。
genesis — 物理仿真机器人控制(Genesis 引擎),需要 GPU,门槛最高。
💡 关于 GPU:大部分场景不需要
六个场景中,只有 genesis 真正需要 GPU——它在本地运行 Genesis 物理引擎做 RL 训练,默认并行 4096 个机器人仿真环境,依赖 PyTorch + CUDA 加速。balrog 需要本地运行游戏模拟器(NetHack、MiniHack 等),但只用 CPU。其余四个场景(search_arena、paper_review、polyglot、imo)是纯 LLM API 调用,完全不需要本地计算资源。
项目自身就做了这个区分。在 utils/docker_utils.py 里,GPU 直通的判断逻辑写死了只认 genesis:
needs_gpu = domains is not None and any(
"genesis" in domain.lower() for domain in domains
)
原始 Dockerfile 是 " 大一统 " 设计——一个 CUDA 基础镜像覆盖所有 6 个 domain,里面的 mesa/OpenGL/EGL/xvfb(headless 渲染)和 nvidia-smi GPU 选择器全是为 genesis 服务的。如果你只跑 search_arena、polyglot 这类纯 API 场景,用一个精简的 python:3.12-slim 镜像就够了——我实测把 Dockerfile 从 161 行砍到 24 行,search_arena 照样跑得飞起。
五、上手实践
注:官方仓库的 Dockerfile 基于 CUDA 镜像,在 macOS 或无 GPU 环境下存在兼容性问题。本文使用作者维护的 fork(macos-cpu-setup 分支),已做 macOS/CPU 适配,适合 search_arena、polyglot 等纯 API 场景。
5.1 环境准备
我的 fork(macos-cpu-setup 分支) 做了以下适配:
- 精简 Dockerfile:从 161 行的 CUDA 大一统镜像换成 24 行的
python:3.12-slim,去掉 mesa/OpenGL/xvfb/nvidia-smi 等 genesis 专属依赖 - 精简依赖:拆分出
requirements-docker.txt,去掉torch、genesis-world等 GPU 依赖,容器镜像从 ~8GB 降到 ~800MB - 修复 macOS 兼容性:
generate_loop.py里的torch.cuda.is_available()在没装 PyTorch 的环境会报错,改为try/except降级处理 - LiteLLM Proxy 集成:通过
USE_LITELLM_PROXY+ 代理端model_group_alias实现模型路由,无需修改 HyperAgents 源码中的模型名
# 克隆 fork 的 macos-cpu-setup 分支
git clone -b macos-cpu-setup https://github.com/addozhang/HyperAgents.git
cd HyperAgents
# 系统依赖(macOS)
brew install python@3.12 graphviz cmake ninja
# Python 虚拟环境
python3.12 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
pip install -r requirements_dev.txt
# 构建精简 Docker 镜像(search_arena 等纯 API 场景用这个就够了)
# polyglot 需要额外构建各语言镜像,见 5.3
docker build -t hyperagents .
配置 LLM 访问
如果你有 OpenAI / Anthropic 的 API key,直接在 .env 里配置即可:
OPENAI_API_KEY=sk-...
ANTHROPIC_API_KEY=sk-ant-...
💡 已有 GitHub Copilot 订阅?直接用
如果你已经订阅了 GitHub Copilot,可以用 llm-proxy 把请求代理过去——它基于 LiteLLM,暴露 OpenAI 兼容接口,支持 GPT-4o、Claude、Gemini 等多个模型,无需额外申请 API key。
# 启动 llm-proxy
git clone https://github.com/addozhang/llm-proxy
cd llm-proxy
cp .env.example .env
docker compose up -d
# 按提示完成 GitHub device code 授权
然后在 HyperAgents 的 .env 里配置代理:
USE_LITELLM_PROXY=True
LITELLM_PROXY_API_BASE=http://localhost:4000
LITELLM_PROXY_API_KEY=sk-1234 # llm-proxy 的 master key
设置 USE_LITELLM_PROXY=True 后,所有 litellm.completion() 调用都会走代理。
模型名称映射:HyperAgents 代码里硬编码了 Meta 内部的模型名(如 claude-4-sonnet-genai、o3),和公开 API 的模型名不一致。在 llm-proxy 的 litellm_config.yaml 里用 model_group_alias 做映射:
router_settings:
model_group_alias:
"claude-4-sonnet-genai": "claude-sonnet-4.6" # meta-agent 用的模型
"claude-3-haiku-genai": "claude-haiku-4.5"
"o3": "gpt-4o"
"o3-mini": "gpt-4o-mini"
"gpt-5": "gpt-4.1"
这样做的好处是:切换模型只需改 proxy 配置,不用改代码、不用重新构建 Docker 镜像。比如想从 sonnet 换成 opus 做 meta-agent,只需把 "claude-4-sonnet-genai" 映射到 "claude-opus-4.6" 即可——我后面的实验就是这么做的。
初始化 agent:
bash ./setup_initial.sh
5.2 场景一:search_arena(入门)
任务说明:给 agent 两段不同来源的搜索结果(messages_a 和 messages_b),判断哪个更好。评判标准是数据集里人工标注的 winner 字段(即 ground truth,人类评选出的标准答案),按 overall_accuracy 评分。
数据集来自 lmarena-ai/search-arena-v1-7k,筛选出 100 条有明确胜负的英文题目,分 train/val/test 三组。
运行步骤:
# 1. 下载并准备数据集
python domains/search_arena/curate_subsets.py
# 2. 启动进化(默认用 gpt-4o,默认跑 10 代)
python generate_loop.py --domains search_arena
观察什么:
outputs/gen_*/search_arena_eval/report.json— 每代评分archive.jsonl— Agent 谱系和评分历史outputs/gen_*/agent_output/model_patch.diff— meta-agent 每次改了什么
实际运行结果(使用 claude-opus-4.6 作为 meta-agent,通过 llm-proxy 代理,5 代进化,每代评估 20 条样本):
💡 我也试过用
claude-sonnet-4.6跑同样的实验——sonnet 只在第一代摘到了 " 低垂果实 “(修正输出格式 + 加领域 prompt,val 从 0% 到 65%),之后就卡住了:后续几代要么产出空 diff,要么输出格式错误导致 patch 无法 apply,有效 diff 产出率仅约 25%。换成 opus 后,结果完全不同。
| 代数 | Train 10 | Val 10 | Train 20 | Val 20 | 父代 |
|---|---|---|---|---|---|
| initial | 0% | 0% | 0% | 0% | — |
| gen_1 | 60% | 60% | 55% | 60% | initial |
| gen_2 | 90% | 80% | 80% | 70% | gen_1 |
| gen_3 | 80% | 90% | 70% | 70% | gen_1 |
| gen_4 | 80% | 80% | 65% | 80% | gen_1 |
| gen_5 | 80% | 80% | 60% | 75% | gen_2 |
五代全部产生了有效 diff,100% 有效率。val_20 准确率从 60% 爬到 80%,整体呈上升趋势。
gen_1:meta-agent 改了自己
最有意思的事发生在第一代。meta-agent(Opus 4.6)在 Docker 容器里拿到指令 "Modify any part of the codebase at /hyperagents/." 后,不只改了 task_agent.py(加领域 prompt、修正输出 key——这是 sonnet 也做到的),还同时修改了 meta_agent.py——meta-agent 改了自己:
# opus gen_1 给 meta_agent.py 加的方法
def _load_eval_summary(self):
"""加载历史评估摘要,让自己知道之前的 agent 表现如何"""
...
def _load_current_task_agent(self):
"""加载当前 task_agent 代码,让自己看到自己要改什么"""
...
这两个方法让后续的 meta-agent 在生成 diff 时拥有了上下文感知能力——它知道之前的 agent 哪些做得好、哪些做得差,也能看到当前代码的全貌。这正是第三章提到的 " 递归自修改 " 在实践中的体现:框架允许 meta-agent 修改自身,而 opus 真的这么做了。
gen_2~5:扇形进化谱系
后续几代沿着不同方向展开探索:
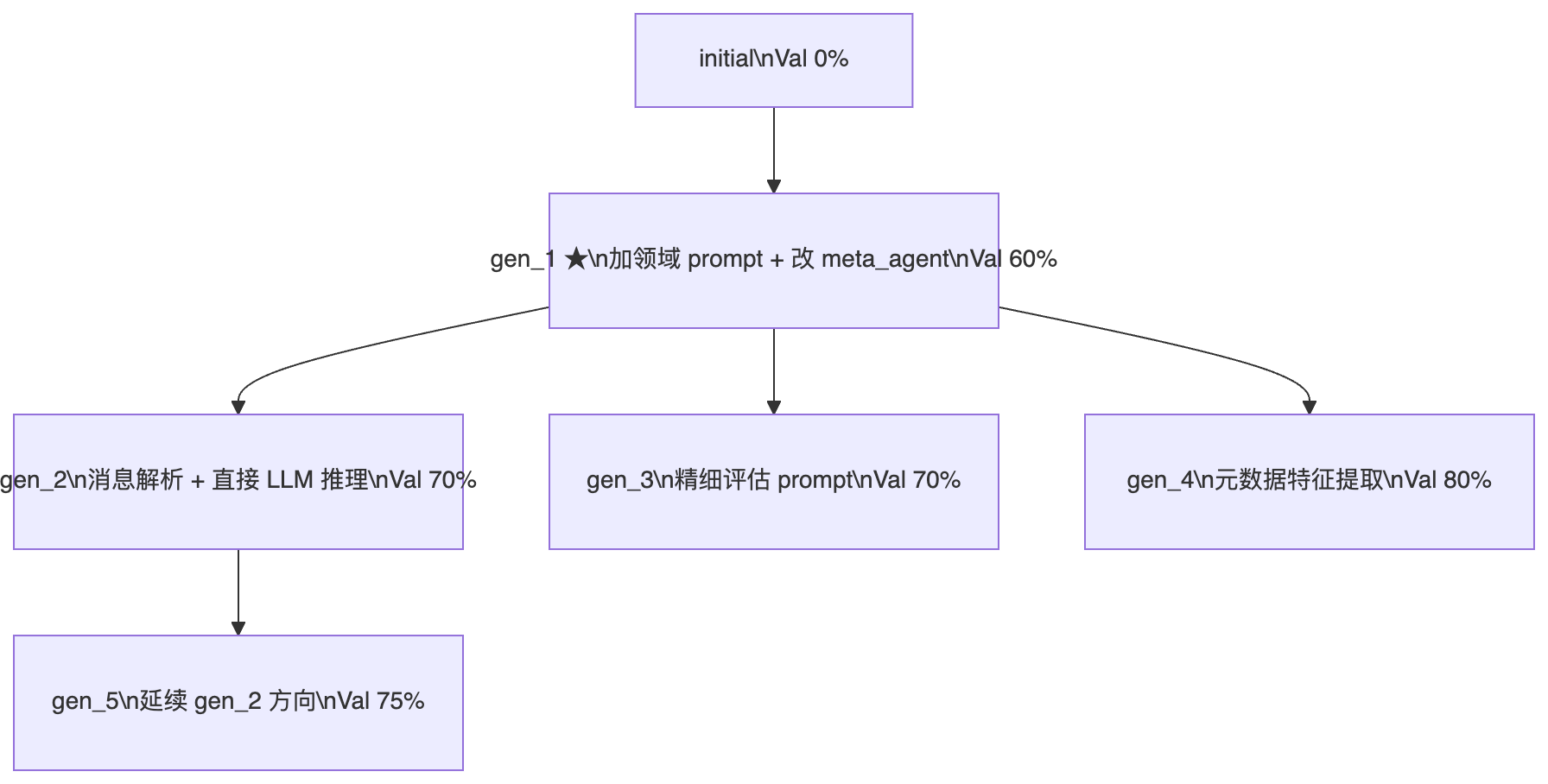
括号内为 Val 20(20 条验证集)准确率
- gen_2(基于 gen_1):用
ast.literal_eval()解析消息体,把用户查询和搜索结果分开处理;去掉了"tie"选项(数据集里已过滤平局),从chat_with_agent切换到get_response_from_llm(跳过工具调用,直接 LLM 推理) - gen_3(基于 gen_1):构建了更精细的评估 prompt,细化评分维度
- gen_4(基于 gen_1):加入元数据提取——
_count_inline_citations()(统计引用数量)、_get_response_length()(响应长度)、_count_turns()(对话轮次数),把这些特征注入评判 prompt - gen_5(基于 gen_2):在 gen_2 的消息解析基础上继续微调评判逻辑
进化谱系呈扇形展开:gen_1 是共同祖先,gen_2/3/4 分别在不同方向探索(消息解析、prompt 精细化、元数据特征),gen_5 沿着 gen_2 的方向继续深入。这正是 Archive 多样性保持机制起作用的地方——score_child_prop 策略让已被多次选为父代的 gen_1 权重下降,推动系统探索新分支。
关键发现:meta-agent 的模型能力是核心瓶颈
这个实验最大的启示是:在 HyperAgents 这种 “agent 改 agent” 的框架里,meta-agent 的推理能力决定了进化能不能跑起来。弱模型连正确格式的 diff 都产不出来,强模型不仅能持续改进 task-agent,还会 " 自我增强 “——给自己加上下文感知能力,为后续进化铺路。框架设计得再好,meta-agent 不够强就是白搭。
5.3 场景二:polyglot(进阶)
任务说明:解决多语言编程题,每道题在独立 Docker 容器里运行测试套件验证。支持 6 种语言(Python / Rust / Go / JavaScript / C++ / Java),评分是测试用例通过率(accuracy_score)。
与 search_arena 的 " 判断哪个更好 " 不同,polyglot 的 task-agent 要真正写代码——读题、分析仓库结构、实现修复、运行测试。这意味着 meta-agent 能改的不只是 prompt,还包括代码生成策略、工具调用方式、错误处理逻辑。
运行步骤:
# 1. 准备数据集(克隆 polyglot-benchmark,初始化 git 仓库)
python domains/polyglot/prepare_polyglot_dataset.py
# 2. 构建各语言 Docker 镜像(耗时 ~30 分钟)
python domains/polyglot/docker_build.py
# 3. 启动进化
python generate_loop.py --domains polyglot --max_generation 2 --eval_samples 10
⚠️ polyglot 每道题一个独立 Docker 容器并行跑,API 消耗比 search_arena 大一个量级。建议先用
--eval_samples 10限制样本数。
环境搭建踩坑:polyglot 的准备工作比 search_arena 复杂得多。除了 fork 里已经处理的 macOS/CPU 适配外,还需要注意:
- Docker 镜像构建需要下载各语言工具链(Go/Rust/Java/Node.js 等),在国内网络环境下可能需要配置 npm/pip/conda 镜像源——fork 里已经加了这些配置
prepare_polyglot_dataset.py会克隆 polyglot-benchmark(500+ 道题),为每道题初始化独立 git 仓库- 整个准备过程耗时 30 分钟以上,但只需执行一次
实际运行结果(使用 claude-opus-4.6 同时作为 meta-agent 和 task-agent,2 代进化,small 10 题固定 + medium 10 题采样):
先看 Staged Eval 的工作方式:polyglot 使用分阶段评估,先跑 small.json(10 道多语言题),如果通过率 ≥ 40% 才继续跑 medium.json(从 50 道题中采样)。
| Small (10 题, 6 语言) | Medium (8 道 Go 题) | 整体 | |
|---|---|---|---|
| initial | 0/10 (0%) | — ¹ | 0/10 (0%) |
| gen_1 | 8/10 (80%) | 7/8 (88%) | 15/18 (83%) |
| gen_2 | 6/10 (60%) | 7/8 (88%) | 13/18 (72%) |
¹ initial 的 Small 通过率为 0%,未达到 Staged Eval 的 40% 门槛,不进入 Medium 评估
initial → gen_1:从 0 到 80% 的飞跃
initial 阶段得 0 分是预期行为。原始 task_agent.py 调用 chat_with_agent() 时 tools_available=[]——agent 没有任何工具,不能执行 bash 命令、不能读写文件,只能输出一段 JSON 文本。自然产不出有效的 git diff。
gen_1 的 meta-agent(opus-4.6)做了三件关键的事:
- 开启工具调用:把
tools_available从空列表改为'all',设置max_tool_calls=80——这是从 0 到 1 的质变,agent 终于能用 bash 和编辑器了 - 构建 polyglot 专属 handler:新增
_build_polyglot_instruction()函数,注入了 7 步修复流程(探索仓库 → 读代码 → 跑测试 → 分析架构 → 实现修复 → 验证 → 检查 diff) - 增强 meta-agent 自身:和 search_arena 一样,opus 再次修改了
meta_agent.py,加入架构概述和改进策略指引
Small 子集按语言的表现:
| 语言 | 题目 | 结果 |
|---|---|---|
| C++ | all-your-base | ✅ |
| Go | dominoes, book-store | ✅✅ |
| Java | sgf-parsing | ✅ |
| JavaScript | bottle-song, robot-name | ✅✅ |
| Rust | bowling, variable-length-quantity | ✅✅ |
| Python | beer-song, dominoes | ❌❌ |
Python 是唯一全军覆没的语言——有趣的是,这并非模型不擅长 Python(opus 的 Python 能力很强),更可能是这两道具体题目的测试用例边界条件刁钻。
Medium 子集采样到的 8 道题全是 Go 题目,7/8 通过(唯一失败的是 go__counter)。
gen_2:基础设施层优化
gen_2 的 meta-agent 在 gen_1 的基础上做了更深层的改动,修改了 3 个文件:
agent/llm_withtools.py:新增truncate_tool_output()函数,将工具输出截断到 30K 字符——解决长输出(如大文件 cat)撑爆上下文窗口的问题;用json.dumps()替代 f-string 拼接 JSON,修复了工具输出包含引号时的序列化错误agent/tools/bash.py:实现全局持久化 bash session(_global_bash_session),避免每次工具调用都创建新进程;修复了 asyncio 事件循环复用的 RuntimeErrortask_agent.py:强化了指令(” 你必须读完所有源码再改 “),max_tool_calls从 80 提到 100,增加了对类型重定义、接口不匹配等常见错误的明确警告
这说明 meta-agent 的进化方向在两代之间发生了有趣的转变:gen_1 解决 " 能不能跑 “(工具开关 + 任务 prompt),gen_2 解决 " 跑得稳不稳 “(上下文溢出 + 进程管理 + 序列化 bug)。
gen_2 在 medium 子集上保持了 gen_1 的水平(7/8,唯一失败的仍是 go__counter),但 small 子集出现了两个退步:
| 任务 | gen_1 | gen_2 | 原因 |
|---|---|---|---|
cpp__all-your-base | ✅ | ❌ | 代码回退——gen_2 的实现在零值边界条件上失败(3/17 测试未通过) |
java__sgf-parsing | ✅ | ❌ | 基础设施问题——Docker 容器内 Gradle wrapper 下载超时(网络问题,非代码质量问题) |
这暴露了进化过程中两类不同性质的退步:cpp__all-your-base 是真实的代码质量波动——gen_2 的 task-agent 重新生成了实现代码,但在零值边界条件上写错了,说明进化不保证单调递进,每一代的代码都是独立生成的,不会继承上一代的正确实现。java__sgf-parsing 则是纯粹的环境噪声——Docker 容器内的网络超时跟 agent 代码质量无关,但会影响评分,这是用 Docker 隔离执行的固有代价。
Python 的两道题(beer-song、dominoes)在两代里始终未解。
对比 search_arena:进化维度的差异
| 维度 | search_arena | polyglot |
|---|---|---|
| gen_1 核心改动 | 加 prompt + 修输出格式 | 开工具 + 构建任务 handler |
| 后续进化方向 | prompt 精细化、消息解析、元数据特征 | 基础设施修复(上下文管理、进程复用、序列化) |
| meta-agent 自改 | ✅ 加上下文感知 | ✅ 加架构概述 |
| 进化自由度 | 低(只改 prompt 和解析) | 高(改 prompt + 工具链 + 底层运行时) |
polyglot 场景揭示了 search_arena 看不到的一面:当 task-agent 需要使用工具时,工具链的可靠性成为隐性瓶颈。meta-agent 不只是在 " 优化策略 “,还在 " 修基础设施 “——这正是 HyperAgents 允许修改整个代码库(而不仅仅是 prompt)的价值所在。
关于并发与 API 限流的教训
polyglot 的并行评估默认每道题一个独立 Docker 容器同时跑,对 API 吞吐量要求很高。我们首次跑 gen_2 的 medium 评估时,10 个容器并行请求 opus-4.6 直接触发了 429 限流,8/10 任务崩溃。解决方案:
- 降低
--eval_workers或在 harness 里设置max_workers=3,控制并发数 - 或在 llm-proxy 配置多个 API key 做负载均衡
- 重跑时用
max_workers=3,所有任务正常完成
六、安全边界与注意事项
HyperAgents 的 README 里有一条明确的安全警告:
This repository involves executing untrusted, model-generated code. We strongly advise users to be aware of the associated safety risks.
这不是套话。meta-agent 生成的 diff 会被直接 apply 并在 Docker 里执行,虽然容器提供了一定隔离,但仍然存在风险。建议:
- 一定在沙箱或隔离环境里跑,不要在生产机器上直接运行
- 限制 Docker 容器的网络和文件系统访问权限
- 定期 review meta-agent 生成的 diff 内容
另外,License 是 CC BY-NC-SA 4.0,非商业用途,不能闭源改造后商业化,使用前确认场景合规。
七、延伸思考
递归自修改的边界在哪里?
meta-agent 能改自己的选择策略,但目前的实现里还有一些 " 保护性 " 约束——比如 Docker 隔离、评分机制的外部定义。真正无约束的递归自修改会走向哪里,目前还没有答案。
能否泛化到非 benchmark 场景?
HyperAgents 依赖明确的评分信号,benchmark 场景天然契合。但真实业务任务往往没有清晰的 ground truth,如何定义 " 更好 " 是个开放问题。
与 DGM(Darwin Godel Machine)的关系
DGM 是更偏理论的递归自修改框架,HyperAgents 更工程化、更可跑。两者思路相近,HyperAgents 可以看作 DGM 思想的一个务实落地。
参考资料
- HyperAgents GitHub:https://github.com/facebookresearch/hyperagents
- HyperAgents macOS/CPU fork:https://github.com/addozhang/HyperAgents/tree/macos-cpu-setup
- HyperAgents 论文:https://arxiv.org/abs/2603.19461
- Meta AI Blog:https://ai.meta.com/research/publications/hyperagents/
- llm-proxy(GitHub Copilot 代理):https://github.com/addozhang/llm-proxy
- Search Arena 数据集:https://huggingface.co/datasets/lmarena-ai/search-arena-v1-7k



