
Kubernetes externalIPs:已知六年的安全漏洞,终于要移除了
TL;DR
Kubernetes Service 的 externalIPs 字段存在长达六年的中间人攻击漏洞(CVE-2020-8554),任何有 Service 创建权限的用户都可以劫持集群流量 –v1.36 终于启动了正式的废弃流程。
开篇:一条命令,劫持集群流量
想象这样一个场景。
你的集群里有一个开发者,他拥有普通的 Service 创建权限 – 这在大多数团队中再正常不过。他写了一段这样的配置:
apiVersion: v1
kind: Service
metadata:
name: dns-intercept
spec:
selector:
app: attacker-pod
ports:
- port: 53
protocol: UDP
externalIPs:
- 8.8.8.8
一条 kubectl apply,几秒钟后,集群内所有节点上发往 8.8.8.8:53 的 DNS 查询,全部被悄悄转发到他控制的 Pod。
没有提权,没有漏洞利用,没有任何异常告警。完全合法的 Kubernetes 操作。
这就是 CVE-2020-8554,2020 年底披露,六年后的今天才正式启动移除。
这篇文章拆解这个漏洞的来龙去脉:它为什么存在、怎么被利用、Kubernetes 为什么花了六年才下决心移除,以及你现在应该怎么做。
externalIPs 是什么
Service.spec.externalIPs 是 Kubernetes 早期引入的一个字段,允许你在 Service 上手动指定一组外部 IP 地址。配置之后,kube-proxy 会在集群的每个节点上添加 iptables 规则,将发往这些 IP 的流量路由到对应的 Service。
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- port: 80
externalIPs:
- 203.0.113.10
这个字段出现在 type: LoadBalancer 之前。那个年代,Kubernetes 还没有成熟的云厂商集成,裸金属集群也没有 MetalLB 这样的工具。externalIPs 是当时最直接的方式:告诉 kube-proxy" 把这个 IP 的流量交给我 “,流量路由到节点之后的事,由管理员自己在集群外处理。
它的设计有三个根本性的缺陷:
没有归属验证。 Kubernetes 不会检查这个 IP 是否真的属于这个集群、这台主机,或者这个用户。任何 IP 都可以填。
没有授权模型。 写 externalIPs 只需要 Service 的创建/更新权限,这是普通开发者通常都有的权限,和管理员权限没有任何区别。
没有冲突检测。 多个 Service 可以声明同一个 IP,先写入 iptables 规则的会胜出,后者的流量会被静默丢弃,没有任何告警。
这三个问题叠加在一起,构成了 CVE-2020-8554 的攻击面。
CVE-2020-8554:攻击原理拆解
kube-proxy 如何处理 externalIPs
理解攻击之前,先看 kube-proxy 做了什么。
当一个带有 externalIPs 的 Service 被创建后,kube-proxy 会在集群每个节点上写入一组 iptables 规则。完整的数据包处理链路如下:
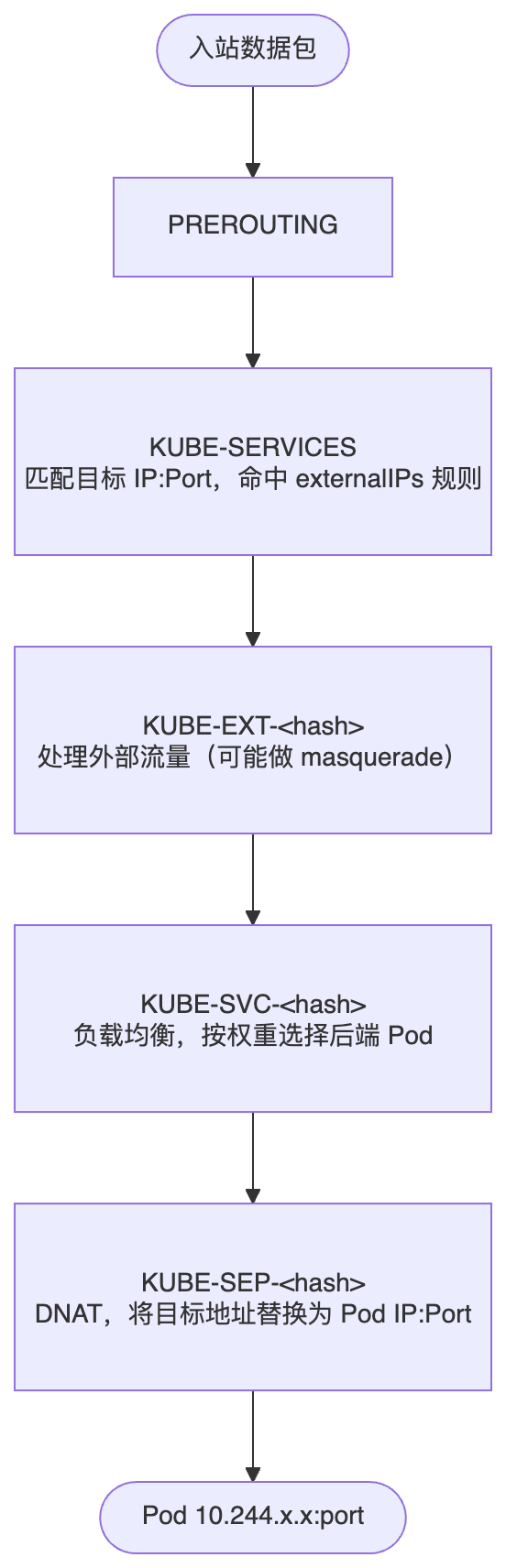
用实际规则展示(以 203.0.113.10:80 → Pod 10.244.1.5:8080 为例):
# 第一跳:KUBE-SERVICES 匹配 externalIP
-A KUBE-SERVICES -d 203.0.113.10/32 -p tcp --dport 80 \
-j KUBE-EXT-XXXXXXXXXXXXXXXX
# 第二跳:KUBE-EXT 处理外部来源流量
-A KUBE-EXT-XXXXXXXXXXXXXXXX \
-j KUBE-SVC-XXXXXXXXXXXXXXXX
# 第三跳:KUBE-SVC 负载均衡选后端(此处只有一个 Pod)
-A KUBE-SVC-XXXXXXXXXXXXXXXX \
-j KUBE-SEP-XXXXXXXXXXXXXXXX
# 第四跳:KUBE-SEP 执行 DNAT
-A KUBE-SEP-XXXXXXXXXXXXXXXX -p tcp \
-j DNAT --to-destination 10.244.1.5:8080
有两个细节值得关注:
规则写在 PREROUTING 链,这意味着数据包在进入本机路由决策之前就已经被改写了目标地址。无论这个 IP 是否真的分配给了这台主机,只要数据包到达节点,就会被拦截。
KUBE-SERVICES 链没有来源检查,规则只匹配目标地址(-d),不检查数据包从哪里来。这是攻击能够成立的技术基础 – 攻击者不需要控制流量的发起方,只需要让目标 IP 命中规则。
三种攻击路径
路径一:劫持外部服务流量
攻击者声明一个集群外的知名 IP,比如 8.8.8.8:
externalIPs:
- 8.8.8.8
ports:
- port: 53
protocol: UDP
效果:集群内所有 Pod 发出的 DNS 查询,凡是目标是 8.8.8.8:53 的,全部被拦截并转发到攻击者的 Pod。攻击者可以返回伪造的 DNS 响应,将任意域名解析到他控制的地址。
路径二:抢占 ClusterIP
攻击者声明一个已有 Service 的 ClusterIP:
externalIPs:
- 10.96.0.10 # 某个现有 Service 的 ClusterIP
由于 iptables 规则的匹配顺序,在特定条件下可以抢占原有 Service 的流量,实现集群内部的流量劫持。
路径三:声明节点 IP
externalIPs:
- 192.168.1.100 # 某个节点的真实 IP
发往该节点 IP 的流量全部被劫持,可以用来伪造 API Server 响应、拦截 SSH 连接,或者针对节点上运行的任意服务发起攻击。
为什么 RBAC 挡不住
这是这个漏洞最本质的问题。
Kubernetes 的 RBAC 模型假设:操作某类资源的权限,不应该影响到其他资源或基础设施。创建 Service,就只应该影响 Service 本身的行为。
但 externalIPs 打破了这个假设 – 写一个字段,影响的是节点级别的 iptables 规则,波及的是整个集群的网络层。
- 权限要求:
services/create或services/update(普通开发者权限) - 实际效果:修改所有节点的 iptables 规则,节点级别的网络劫持
没有任何 RBAC 规则可以在不禁止 Service 创建的情况下,单独限制 externalIPs 字段的使用 – 直到 v1.36 引入废弃之前,Kubernetes 连一个原生的字段级授权机制都没有。
废弃路线:v1.36 → v1.43
Kubernetes 的废弃流程一贯保守,这次也不例外。从发出第一个警告到彻底移除,跨越四个阶段、至少七个版本。
Phase 1:发出警告(v1.36,2026 年 4 月)
现阶段。API 字段标记为废弃,任何创建或更新带有 externalIPs 的 Service 时,都会收到警告:
Warning: spec.externalIPs is deprecated and will be removed in a future version
同时引入 feature gate AllowServiceExternalIPs,默认为 true,功能完全正常,只是多了警告。存量配置不受任何影响。
Phase 2:默认禁用(v1.40,预计 2027 年中)
AllowServiceExternalIPs 默认切换为 false。kube-proxy 停止为 externalIPs 写入 iptables 规则 –API 字段依然可以填写,但不会产生任何网络效果,相当于静默失效。
管理员可以手动将 feature gate 设回 true 来恢复功能,争取额外的迁移时间。
Phase 3:锁定移除(v1.43,预计 2028 年下半年)
Feature gate 锁定为 false,kube-proxy 中所有相关代码全部删除。此时无论 feature gate 设什么值,功能都不再存在。注意:KEP 明确写明 Phase 3 暂不移除 DenyServiceExternalIPs admission controller,留待 Phase 4 处理。
Phase 4:清理收尾(v1.46+,预计 2029 年及以后)
AllowServiceExternalIPs feature gate 本身和 DenyServiceExternalIPs admission controller 从代码库中彻底移除。API 字段在 apiserver 侧保留(避免反序列化错误),但已经是一个无意义的空字段。
时间线一览
| 版本 | 时间(估算) | 状态 |
|---|---|---|
| v1.36 | 2026 Q2 | 废弃警告,功能正常 |
| v1.40 | 2027 Q3 | 默认禁用,可手动恢复 |
| v1.43 | 2028 Q3 | 彻底移除,无法恢复 |
| v1.46+ | 2029+ | feature gate 和 admission controller 代码清除 |
迁移窗口大约两年。如果你的集群现在还在用 externalIPs,Phase 2 是真正的截止线 –v1.40 之后不做迁移,服务会静默失效,且没有任何报错。
现在该怎么做
第一步:扫描存量配置
先确认集群里是否有 Service 在使用 externalIPs:
kubectl get services -A -o json | \
jq -r '.items[] | select(.spec.externalIPs != null and (.spec.externalIPs | length) > 0) | "\(.metadata.namespace)/\(.metadata.name): \(.spec.externalIPs)"'
如果没有输出,你的集群不受影响。如果有,按下面的方案处理。
第二步:选择防御方案
方案一:启用 DenyServiceExternalIPs admission controller(最快)
修改 kube-apiserver 启动参数:
# /etc/kubernetes/manifests/kube-apiserver.yaml
- --enable-admission-plugins=NodeRestriction,DenyServiceExternalIPs
效果立竿见影:所有新增或更新 externalIPs 的请求直接被拒绝。存量配置不会自动清理,需要手动处理。
局限性:只拦截新增/更新请求,已有 Service 的 externalIPs 不受影响,需逐一排查清理;admission 发生在 API 层,无法覆盖直接操作 etcd 的场景;v1.43 会随 externalIPs 一起被移除,不适合作为长期方案。
方案二:提前关闭 feature gate(可选)
如果你想提前到 v1.40 的状态,可以在 kube-proxy 的 ConfigMap 里关闭:
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-proxy
namespace: kube-system
data:
config.conf: |
featureGates:
AllowServiceExternalIPs: false
kube-proxy 停止处理 externalIPs 规则,但 API 字段本身还在,不会产生报错。
局限性:只作用于 kube-proxy,API 字段仍然可以写入,容易造成 " 配置看起来正常、实际不生效 " 的混淆;kube-proxy 重启或集群升级后需确认 feature gate 没有被重置;对节点上已有的 iptables 规则不做立即清理,需等 kube-proxy 下一个同步周期才彻底生效。
方案三:Kyverno 策略(长期推荐)
admission controller 会被移除,Kyverno 策略不会。部署一次,长期有效:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: deny-service-external-ips
spec:
validationFailureAction: Enforce
rules:
- name: deny-external-ips
match:
any:
- resources:
kinds: [Service]
validate:
message: "spec.externalIPs is not allowed, use LoadBalancer or Gateway API instead"
deny:
conditions:
any:
- key: "{{ request.object.spec.externalIPs | length(@) }}"
operator: GreaterThan
value: 0
局限性:依赖 Kyverno 本身的可用性,Kyverno Pod 不可用时策略失效,建议将 failurePolicy 设为 Fail 以确保安全性优先;多集群环境需要每个集群单独部署,没有原生的跨集群策略同步机制。
行动优先级
| 时间 | 动作 |
|---|---|
| 立即 | 扫描存量 Service + 启用 DenyServiceExternalIPs |
| 短期 | 部署 Kyverno 策略替代 admission controller |
| v1.40 前 | 完成所有迁移,不依赖 feature gate 兜底 |
| v1.43 前 | 确认无遗留依赖 |
迁移到现代方案
迁移路径取决于你的集群环境和流量类型。
云环境:type: LoadBalancer
最直接的替代。云厂商的 LoadBalancer controller 会自动分配 IP,不需要手动声明:
# 迁移前
spec:
externalIPs:
- 203.0.113.10
ports:
- port: 80
# 迁移后
spec:
type: LoadBalancer
ports:
- port: 80
# 云厂商自动分配 EXTERNAL-IP,无需手动指定
如果需要固定 IP,各云厂商有对应的 annotation:
# AWS
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-eip-allocations: eipalloc-xxxx
# Azure
metadata:
annotations:
service.beta.kubernetes.io/azure-load-balancer-ipv4: 203.0.113.10
# GCP
spec:
loadBalancerIP: 203.0.113.10
裸金属:MetalLB + type: LoadBalancer
没有云厂商的裸金属集群,MetalLB 提供了等价的能力。
MetalLB 以 DaemonSet + Controller 的形式运行在集群中。当一个 type: LoadBalancer 的 Service 被创建时,Controller 从地址池中分配一个 IP,然后由节点上的 Speaker 负责将这个 IP 宣告到网络:
- Layer 2 模式:Speaker 通过 ARP(IPv4)或 NDP(IPv6)响应,将该 IP 绑定到某个节点的网卡,流量先到这个节点再由 kube-proxy 转发到 Pod(详见:LoadBalancer Service 与 MetalLB)
- BGP 模式:Speaker 与上游路由器建立 BGP 会话,将 IP 作为路由宣告出去,路由器直接将流量负载均衡到多个节点(详见:MetalLB BGP 模式)
关键点:IP 的归属由 MetalLB Controller 统一管理,写在 IPAddressPool 里,普通用户无法绕过它随意声明 IP– 这正是它比 externalIPs 安全的根本原因。
配置 IP 地址池,让 MetalLB 接管 LoadBalancer IP 的分配:
# 定义可用 IP 池
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: production-pool
namespace: metallb-system
spec:
addresses:
- 203.0.113.0/24
---
# Service 只需声明类型,IP 自动分配
apiVersion: v1
kind: Service
spec:
type: LoadBalancer
ports:
- port: 80
新项目:Gateway API
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: production-gateway
spec:
gatewayClassName: nginx
listeners:
- name: http
port: 80
protocol: HTTP
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: my-route
spec:
parentRefs:
- name: production-gateway
rules:
- backendRefs:
- name: my-service
port: 80
Gateway API 将 " 谁能管理入口 " 和 " 谁能配置路由 " 分离成两个角色,从设计上避免了 externalIPs 的授权问题。
方案选择参考
| 场景 | 推荐方案 |
|---|---|
| 公有云集群 | type: LoadBalancer(云厂商原生) |
| 裸金属/私有云 | MetalLB + type: LoadBalancer |
| HTTP/HTTPS 流量 | Gateway API |
| 多协议、复杂路由 | Gateway API |
| 存量 Ingress 迁移 | Ingress2Gateway 工具辅助迁移 |
为什么选择移除而不是修复
KEP-5707 的 Alternatives 章节里,有人提出过 " 加强安全控制 " 的方案:给 externalIPs 加 RBAC 字段级权限、加 IP 合法性验证、加冲突检测。KEP 的结论是:工程代价高,但这个功能有更好的替代品——安全问题是设计层面的缺陷,不是实现层面的 bug,不值得花大力气修补一个先天有问题的设计。
可以修复,但不值得修复。 字段级 RBAC 在 Kubernetes 里并不存在,要实现它需要改动 API machinery 的核心;IP 归属验证需要 kube-proxy 和 apiserver 之间新增协调机制;冲突检测需要全局状态的维护。每一项都是相当大的工程投入,而且修完之后,这个功能也只是 " 勉强安全 “,不会比 LoadBalancer 或 Gateway API 更好用。
临时缓解掩盖了真实风险。 2020 年引入的 DenyServiceExternalIPs admission controller 是可选的,默认不开启。六年来,绝大多数集群并没有启用它。这意味着问题一直存在,只是被一个 " 管理员可以选择关闭 " 的开关遮住了。
替代方案成熟是移除的真正前提。 Kubernetes 社区对废弃一贯保守,原因很简单:移除一个功能,意味着有人的生产环境会出问题。只有当替代方案足够成熟 –LoadBalancer 在云环境普及、MetalLB 在裸金属场景稳定、Gateway API 进入 GA– 移除才有足够的底气。
这背后是 Kubernetes 项目一贯的取舍哲学:宁可慢,不留烂账。一个设计上有缺陷的功能,迟早要还债。早移除,早干净。
externalIPs 从引入到彻底移除,横跨了 Kubernetes 从早期工具到生产基础设施的整个演进历程。它的退场,某种程度上也是一个信号:Kubernetes 的网络模型已经足够成熟,不再需要这类 " 凑合能用 " 的早期设计。



