
Kubernetes 网络学习之 Cilium 与 eBPF
这是 Kubernetes 网络学习的第五篇笔记,也是之前计划中的最后一篇。
- 深入探索 Kubernetes 网络模型和网络通信
- 认识一下容器网络接口 CNI
- 源码分析:从 kubelet、容器运行时看 CNI 的使用
- 从 Flannel 学习 Kubernetes VXLAN 网络
- Kubernetes 网络学习之 Cilium 与 eBPF(本篇)
- …
开始之前说点题外话,距离上一篇 Flannel CNI 的发布已经快一个月了。这篇本想趁着势头在去年底完成的,正好在一个月内完成计划的所有内容。但上篇发布后不久,我中招了花了一个多周的时间才恢复。然而,恢复后的状态让我有点懵,总感觉很难集中精力,很容易精神涣散。可能接近网上流传的“脑雾”吧,而且 Cilium 也有点类似一团迷雾。再叠加网络知识的不足,eBPF 也未从涉足,学习的过程中断断续续,我曾经一度怀疑这篇会不会流产。
文章中不免会有问题,如果有发现问题或者建议,望不吝赐教。
背景
去年曾经写过一篇文章 《使用 Cilium 增强 Kubernetes 网络安全》 接触过 Cilium,借助 Cilium 的网络策略从网络层面对 pod 间的通信进行限制。但当时我不曾深入其实现原理,对 Kubernetes 网络和 CNI 的了解也不够深入。这次我们通过实际的环境来探寻 Cilium 的网络。
这篇文章使用的 Cilium 版本是 v1.12.3,操作系统是 Ubuntu 20.04,内核版本是 5.4.0-91-generic。
Cilium 简介
Cilium 是一个开源软件,用于提供、保护和观察容器工作负载(云原生)之间的网络连接,由革命性的内核技术 eBPF 推动。
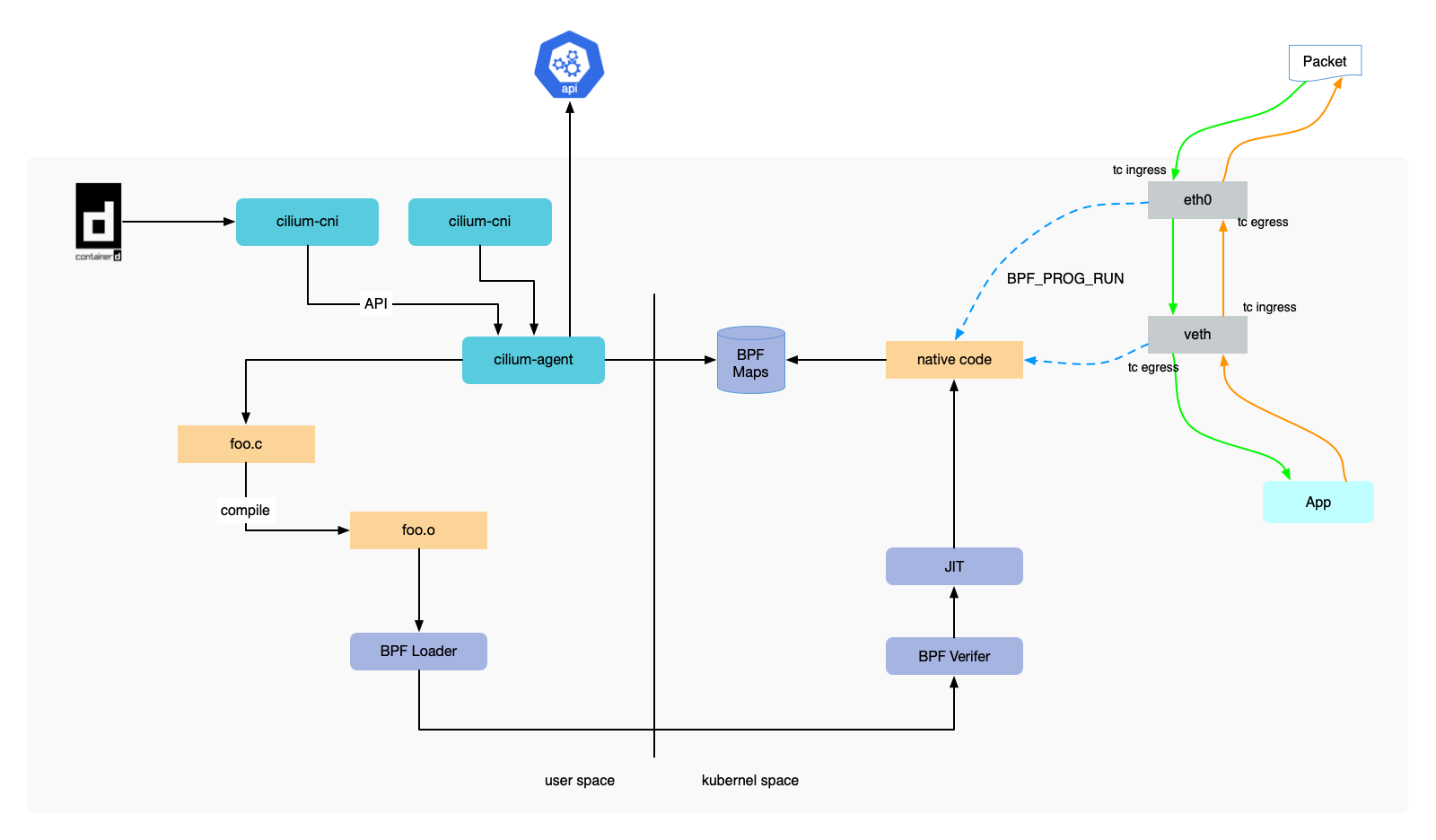
eBPF 是什么?
Linux 内核一直是实现监控/可观测性、网络和安全功能的理想地方。 不过很多情况下这并非易事,因为这些工作需要修改内核源码或加载内核模块, 最终实现形式是在已有的层层抽象之上叠加新的抽象。 eBPF 是一项革命性技术,它能在内核中运行沙箱程序(sandbox programs), 而无需修改内核源码或者加载内核模块。
将 Linux 内核变成可编程之后,就能基于现有的(而非增加新的)抽象层来打造更加智能、 功能更加丰富的基础设施软件,而不会增加系统的复杂度,也不会牺牲执行效率和安全性。
Linux 的内核在网络栈上提供了一组 BPF 钩子,通过这些钩子可以触发 BPF 程序的执行。Cilium datapah 使用这些钩子加载 BPF 程序,创建出更高级的网络结构。
通过阅读 Cilium 参考文档 eBPF Datapath 得知 Cilium 使用了下面几种钩子:
- XDP:这是网络驱动中接收网络包时就可以触发 BPF 程序的钩子,也是最早的点。由于此时还没有执行其他操作,比如将网络包写入内存,所以它非常适合运行删除恶意或意外流量的过滤程序,以及其他常见的 DDOS 保护机制。
- Traffic Control Ingress/Egress:附加到流量控制(traffic control,简称 tc)ingress 钩子上的 BPF 程序,可以被附加到网络接口上。这种钩子在网络栈的 L3 之前执行,并可以访问网络包的大部分元数据。适合处理本节点的操作,比如应用 L3/L4 的端点 1 策略、转发流量到端点。CNI 通常使用虚拟机以太接口对
veth将容器连接到主机的网络命名空间。使用附加到主机端veth的 tc ingress 钩子,可以监控离开容器的所有流量,并执行策略。同时将另一个 BPF 程序附加到 tc egress 钩子,Cilium 可以监控所有进出节点的流量并执行策略 . - Socket operations:套接字操作钩子附加到特定的 cgroup 并在 TCP 事件上运行。Cilium 将 BPF 套接字操作程序附加到根 cgroup,并使用它来监控 TCP 状态转换,特别是 ESTABLISHED 状态转换。当套接字状态变为 ESTABLISHED 时,如果 TCP 套接字的对端也在当前节点(也可能是本地代理),则会附加 Socket send/recv 程序。
- Socket send/recv:这个钩子在 TCP 套接字执行的每个发送操作上运行。此时钩子可以检查消息并丢弃消息、将消息发送到 TCP 层,或者将消息重定向到另一个套接字。Cilium 使用它来加速数据路径重定向。
因为后面会用到,这里着重介绍了这几种钩子。
环境搭建
前面几篇文章,我都是使用 k3s 并手动安装 CNI 插件来搭建实验环境。这次,我们直接使用 k8e,因为 k8e 使用 Cilium 作为默认的 CNI 实现。
还是在我的 homelab 上做个双节点(ubuntu-dev2: 192.168.1.12、ubuntu-dev3: 192.168.1.13)的集群。
Master 节点:
curl -sfL https://getk8e.com/install.sh | API_SERVER_IP=192.168.1.12 K8E_TOKEN=ilovek8e INSTALL_K8E_EXEC="server --cluster-init --write-kubeconfig-mode 644 --write-kubeconfig ~/.kube/config" sh -
Worker 节点:
curl -sfL https://getk8e.com/install.sh | K8E_TOKEN=ilovek8e K8E_URL=https://192.168.1.12:6443 sh -
部署示例应用,将其调度到不同的节点上:
NODE1=ubuntu-dev2
NODE2=ubuntu-dev3
kubectl apply -n default -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
labels:
app: curl
name: curl
spec:
containers:
- image: curlimages/curl
name: curl
command: ["sleep", "365d"]
nodeName: $NODE1
---
apiVersion: v1
kind: Pod
metadata:
labels:
app: httpbin
name: httpbin
spec:
containers:
- image: kennethreitz/httpbin
name: httpbin
nodeName: $NODE2
EOF
为了使用方便,将示例应用、cilium pod 等信息设置为环境变量:
NODE1=ubuntu-dev2
NODE2=ubuntu-dev3
cilium1=$(kubectl get po -n kube-system -l k8s-app=cilium --field-selector spec.nodeName=$NODE1 -o jsonpath='{.items[0].metadata.name}')
cilium2=$(kubectl get po -n kube-system -l k8s-app=cilium --field-selector spec.nodeName=$NODE2 -o jsonpath='{.items[0].metadata.name}')
Debug 流量
还是以前的套路,从请求发起方开始一路追寻网络包。这次使用 Service 来进行访问:curl http://10.42.0.51:80/get。
kubectl get po httpbin -n default -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
httpbin 1/1 Running 0 3m 10.42.0.51 ubuntu-dev3 <none> <none>
第 1 步:Pod1 发送请求
检查 pod curl 的路由表:
kubectl exec curl -n default -- ip route get 10.42.0.51
10.42.0.51 via 10.42.1.247 dev eth0 src 10.42.1.80
可知网络包就发往以太接口 eth0,然后从使用 arp 查到其 MAC 地址 ae:36:76:3e:c3:03:
kubectl exec curl -n default -- arp -n
? (10.42.1.247) at ae:36:76:3e:c3:03 [ether] on eth0
查看接口 eth0 的信息:
kubectl exec curl -n default -- ip link show eth0
42: eth0@if43: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether f6:00:50:f9:92:a1 brd ff:ff:ff:ff:ff:ff
发现其 MAC 地址并不是 ae:36:76:3e:c3:03,从名字上的 @if43 可以得知其 veth 对的索引是 43,接着 登录到节点 NODE1 查询该索引接口的信息:
ip link | grep -A1 ^43
43: lxc48c4aa0637ce@if42: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether ae:36:76:3e:c3:03 brd ff:ff:ff:ff:ff:ff link-netns cni-407cd7d8-7c02-cfa7-bf93-22946f923ffd
我们看到这个接口 lxc48c4aa0637ce 的 MAC 正好就是 ae:36:76:3e:c3:03。
按照 过往的经验,这个虚拟的以太接口 lxc48c4aa0637ce 是个 虚拟以太网口,位于主机的根网络命名空间,一方面与容器的以太接口 eth0 间通过隧道相连,发送到任何一端的网络包都会直达对端;另一方面应该与主机命名空间上的网桥相连,但是从上面的结果中并未找到网桥的名字。
通过 ip link 查看:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether fa:cb:49:4a:28:21 brd ff:ff:ff:ff:ff:ff
3: cilium_net@cilium_host: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 36:d5:5a:2a:ce:80 brd ff:ff:ff:ff:ff:ff
4: cilium_host@cilium_net: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 12:82:fb:78:16:6a brd ff:ff:ff:ff:ff:ff
5: cilium_vxlan: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether fa:42:4d:22:b7:d0 brd ff:ff:ff:ff:ff:ff
25: lxc_health@if24: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 3e:4f:b3:56:67:2b brd ff:ff:ff:ff:ff:ff link-netnsid 0
33: lxc113dd6a50a7a@if32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 32:3a:5b:15:44:ff brd ff:ff:ff:ff:ff:ff link-netns cni-07cffbd8-83dd-dcc1-0b57-5c59c1c037e9
43: lxc48c4aa0637ce@if42: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether ae:36:76:3e:c3:03 brd ff:ff:ff:ff:ff:ff link-netns cni-407cd7d8-7c02-cfa7-bf93-22946f923ffd
我们看到了多个以太接口:cilium_net、cilium_host、cilium_vxlan、cilium_health 以及与容器网络命名空间的以太接口的隧道对端 lxcxxxx。
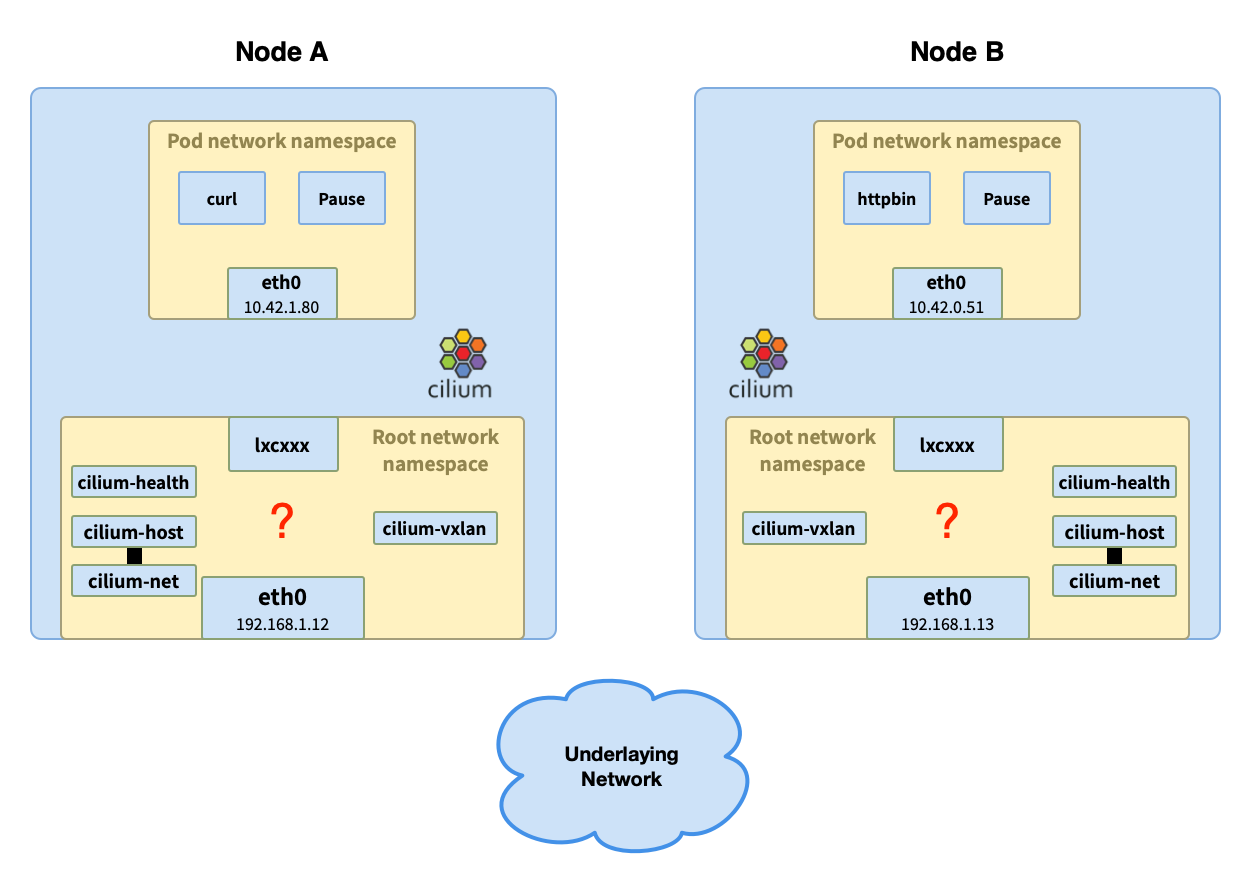
网络包到了 lxcxxx 这里再怎么走?接下来就轮到 eBPF 出场了。
注意 cilium_net、cilium_host 和 cilium_health 在文中不会涉及,因此不在后面的图中体现。
第 2 步:Pod1 LXC BPF Ingress
进入到当前节点的 cilium pod 也就是前面设置的变量 $cilium1 中使用 bpftool 命令检查附加该 veth 上 BPF 程序。
kubectl exec -n kube-system $cilium1 -c cilium-agent -- bpftool net show dev lxc48c4aa0637ce
xdp:
tc:
lxc48c4aa0637ce(43) clsact/ingress bpf_lxc.o:[from-container] id 2901
flow_dissector:
也可以登录到节点 $NODE1 上使用 tc 命令来查询。注意,这里我们指定了 ingress,在文章开头 datapath 部分。因为容器的 eth0 与主机网络命名空间的 lxc 组成通道,因此容器的出口(Egress)流量就是 lxc 的入口 Ingress 流量。同理,容器的入口流量就是 lxc 的出口流量。
#on NODE1
tc filter show dev lxc48c4aa0637ce ingress
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 bpf_lxc.o:[from-container] direct-action not_in_hw id 2901 tag d578585f7e71464b jited
可以通过程序 id 2901 查看详细信息。
kubectl exec -n kube-system $cilium1 -c cilium-agent -- bpftool prog show id 2901
2901: sched_cls name handle_xgress tag d578585f7e71464b gpl
loaded_at 2023-01-09T19:29:52+0000 uid 0
xlated 688B jited 589B memlock 4096B map_ids 572,86
btf_id 301
可以看出,这里加载了 BPF 程序 bpf_lxc.o 的 from-container 部分。到 Cilium 的源码 bpf_lxc.c 的 __section("from-container") 部分,程序名 handle_xgress:
handle_xgress #1
validate_ethertype(ctx, &proto)
tail_handle_ipv4 #2
handle_ipv4_from_lxc #3
lookup_ip4_remote_endpoint => ipcache_lookup4 #4
policy_can_access #5
if TUNNEL_MODE #6
encap_and_redirect_lxc
ctx_redirect(ctx, ENCAP_IFINDEX, 0)
if ENABLE_ROUTING
ipv4_l3
return CTX_ACT_OK;
(1):网络包的头信息发送给 handle_xgress,然后检查其 L3 的协议。
(2):所有 IPv4 的网络包都交由 tail_handle_ipv4 来处理。
(3):核心的逻辑都在 handle_ipv4_from_lxc。tail_handle_ipv4 是如何跳转到 handle_ipv4_from_lxc,这里用到了 Tails Call 。Tails call 允许我们配置在某个 BPF 程序执行完成并满足某个条件时执行指定的另一个程序,且无需返回原程序。这里不做展开有兴趣的可以参考 官方的文档。
(4):接着从 eBPF map cilium_ipcache 中查询目标 endpoint,查询到 tunnel endpoint 192.168.1.13 ,这个地址是目标所在的节点 IP 地址,类型是。
kubectl exec -n kube-system $cilium1 -c cilium-agent -- cilium map get cilium_ipcache | grep 10.42.0.51
10.42.0.51/32 identity=15773 encryptkey=0 tunnelendpoint=192.168.1.13 sync
(5):policy_can_access 这里是执行出口策略的检查,本文不涉及故不展开。
(6):之后的处理会有两种模式:
- 直接路由:交由内核网络栈进行处理,或者 underlaying SDN 的支持。
- 隧道:会将网络包再次封装,通过隧道传输,比如 vxlan。
- 使用代理:在 #5 中如果
policy_can_access返回了代理的端口时(如果网络策略作用在 L7,策略中自动指定代理的端口),会使用代理(Node level)进行路由。关于这部分,还是参考另一篇文章 Cilium 如何处理 L7 流量,对借助代理执行 7 层的流量策略进行了深入的解读。
这里我们使用的也是隧道模式。网络包交给 encap_and_redirect_lxc 处理,使用 tunnel endpoint 作为隧道对端。最终转发给 ENCAP_IFINDEX(这个值是接口的索引值,由 cilium-agent 启动时获取的),就是以太网接口 cilium_vxlan。
第 3 步:NODE 1 vxlan BPF Egress
先看下这个接口上的 BPF 程序。
kubectl exec -n kube-system $cilium1 -c cilium-agent -- bpftool net show dev cilium_vxlan
xdp:
tc:
cilium_vxlan(5) clsact/ingress bpf_overlay.o:[from-overlay] id 2699
cilium_vxlan(5) clsact/egress bpf_overlay.o:[to-overlay] id 2707
flow_dissector:
容器的出口流量对 cilium_vxlan 来说也是 engress,因此这里的程序是 to-overlay。
程序位于 bpf_overlay.c 中,这个程序的处理很简单,如果是 IPv6 协议会将封包使用 IPv6 的地址封装一次。这里是 IPv4 ,直接返回 CTX_ACT_OK。将网络包交给内核网络栈,进入 eth0 接口。
第 4 步:NODE1 NIC BPF Egress
先看看 BPF 程序。
kubectl exec -n kube-system $cilium1 -c cilium-agent -- bpftool net show dev eth0
xdp:
tc:
eth0(2) clsact/ingress bpf_netdev_eth0.o:[from-netdev] id 2823
eth0(2) clsact/egress bpf_netdev_eth0.o:[to-netdev] id 2832
flow_dissector:
egress 程序 to-netdev 位于 bpf_host.c。实际上没做重要的处理,只是返回 CTX_ACT_OK 交给内核网络栈继续处理:将网络包发送到 vxlan 隧道发送到对端,也就是节点 192.168.1.13 。中间数据的传输,实际上用的还是 underlaying 网络,从主机的 eth0 接口经过 underlaying 网络到达目标主机的 eth0 接口。
第 5 步:NODE2 NIC BPF Ingress
vxlan 网络包到达节点的 eth0 接口,也会触发 BPF 程序。
kubectl exec -n kube-system $cilium2 -c cilium-agent -- bpftool net show dev eth0
xdp:
tc:
eth0(2) clsact/ingress bpf_netdev_eth0.o:[from-netdev] id 4556
eth0(2) clsact/egress bpf_netdev_eth0.o:[to-netdev] id 4565
flow_dissector:
这次触发的是 from-netdev,位于 bpf_host.c 中。
from_netdev
if vlan
allow_vlan
return CTX_ACT_OK
对 vxlan tunnel 模式来说,这里的逻辑很简单。当判断网络包是 vxlan 的并确认允许 vlan 后,直接返回 CTX_ACT_OK 将处理交给内核网络栈。
第 6 步:NODE2 vxlan BPF Ingress
网络包通过内核网络栈来到了接口 cilium_vxlan。
kubectl exec -n kube-system $cilium2 -c cilium-agent -- bpftool net show dev cilium_vxlan
xdp:
tc:
cilium_vxlan(5) clsact/ingress bpf_overlay.o:[from-overlay] id 4468
cilium_vxlan(5) clsact/egress bpf_overlay.o:[to-overlay] id 4476
flow_dissector:
程序位于 bpf_overlay.c 中。
from_overlay
validate_ethertype
tail_handle_ipv4
handle_ipv4
lookup_ip4_endpoint 1#
map_lookup_elem
ipv4_local_delivery 2#
tail_call_dynamic 3#
(1):lookup_ip4_endpoint 会在 eBPF map cilium_lxc 中检查目标地址是否在当前节点中(这个 map 只保存了当前节点中的 endpoint)。
kubectl exec -n kube-system $cilium2 -c cilium-agent -- cilium map get cilium_lxc | grep 10.42.0.51
10.42.0.51:0 id=2826 flags=0x0000 ifindex=29 mac=96:86:44:A6:37:EC nodemac=D2:AD:65:4D:D0:7B sync
这里查到目标 endpoint 的信息:id、以太网口索引、mac 地址。在 NODE2 的节点上,查看接口信息发现,这个网口是虚拟以太网设备 lxc65015af813d1,正好是 pod httpbin 接口 eth0 的对端。
ip link | grep -B1 -i d2:ad
29: lxc65015af813d1@if28: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether d2:ad:65:4d:d0:7b brd ff:ff:ff:ff:ff:ff link-netns cni-395674eb-172b-2234-a9ad-1db78b2a5beb
kubectl exec -n default httpbin -- ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
28: eth0@if29: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 96:86:44:a6:37:ec brd ff:ff:ff:ff:ff:ff link-netnsid
(2):ipv4_local_delivery 的逻辑位于 l3.h 中,这里会 tail-call 通过 endpoint 的 LXC ID(29)定位的 BPF 程序。
第 7 步:Pod2 LXC BPF Egress
执行下面的命令并不会找到想想中的 egress to-container(与 from-container)。
kubectl exec -n kube-system $cilium2 -c cilium-agent -- bpftool net show | grep 29
lxc65015af813d1(29) clsact/ingress bpf_lxc.o:[from-container] id 4670
前面用的 BPF 程序都是附加到接口上的,而这里是直接有 vxlan 附加的程序直接 tail call 的。to-container 可以在 bpf-lxc.c 中找到。
handle_to_container
tail_ipv4_to_endpoint
ipv4_policy #1
policy_can_access_ingress
redirect_ep
ctx_redirect
(1):ipv4_policy 会执行配置的策略
(2):如果策略通过,会调用 redirect_ep 将网络包发送到虚拟以太接口 lxc65015af813d1,进入到 veth 后会直达与其相连的容器 eth0 接口。
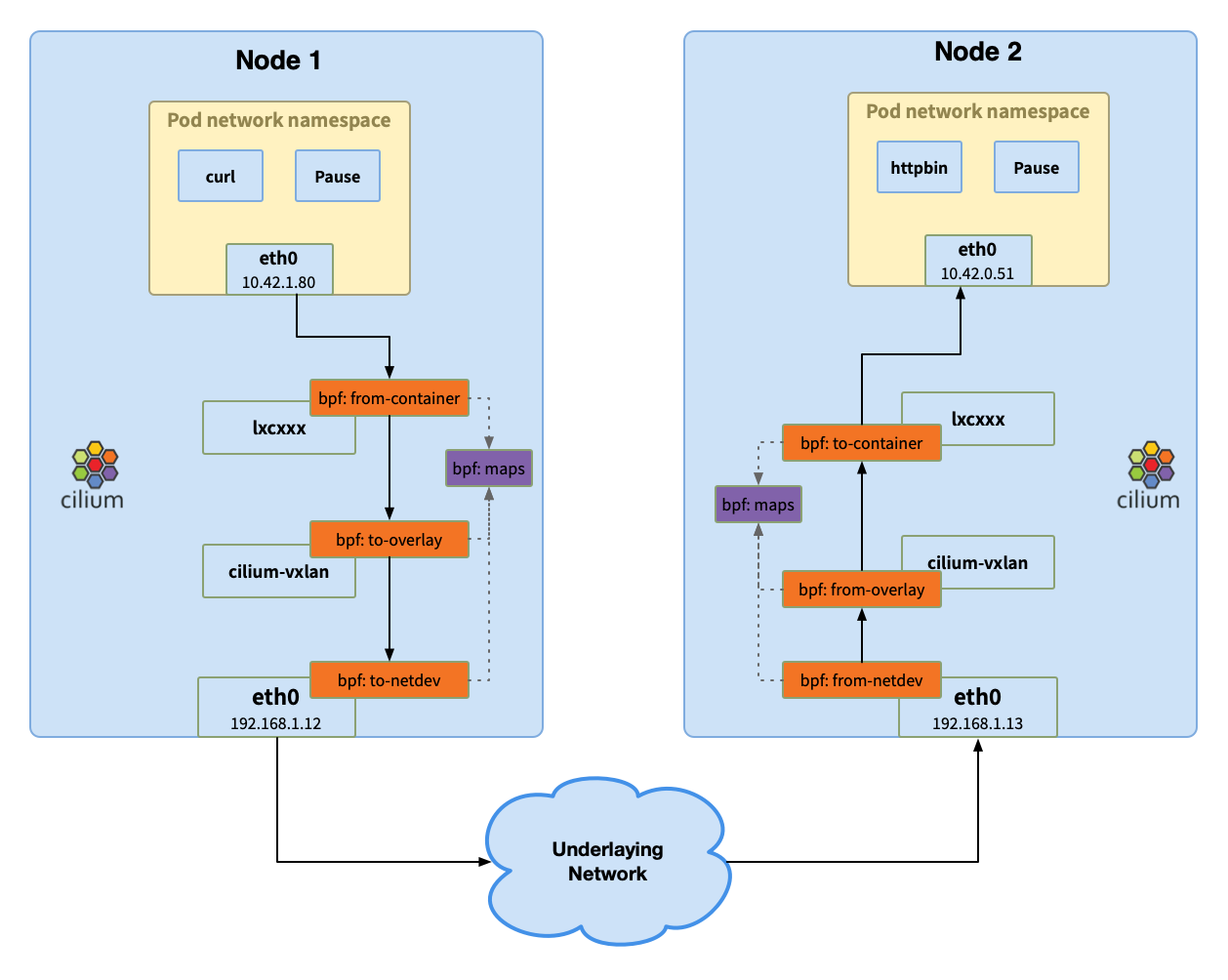
第 8 步:到达 Pod2
网络包到达 pod2,附上一张完成的图。
总结
说说个人看法吧,本文设计的内容还只是 Cilium 的冰山一角,对于内核知识和 C 语言欠缺的我来说研究起来非常吃力。Cilium 除此之外还有很多的内容,也还没有深入去研究。不得不感叹,Cilium 真是复杂,以我目前的了解,Cilium 维护了一套自己的数据在 BPF map 中,比如 endpoint、节点、策略、路由、连接状态等相当多的数据,这些都是保存在内核中;再就是 BPF 程序的开发和维护成本会随着功能的复杂度而膨胀,很难想象如果用 BPF 程序去开发 L7 的功能会多复杂。这应该是为什么会借助代理去处理 L7 的场景。
最后分享下学习 Cilium 过程中的经验吧。
首先是 BPF 程序的阅读,在项目的 bpf 的代码都是静态的代码,里面分布着很多的与配置相关的 if else,运行时会根据配置进行编译。这种情况下可以进入 Cilium pod,在目录 /run/cilium/state/templates 下有应用配置后的源文件,代码量会少很多;在 /run/cilium/state/globals/node_config 下是当前使用的配置,可以结合这些配置来阅读代码。
脚注
Cilium 通过为容器分配 IP 地址使其在网络上可用。多个容器可以共享同一个 IP 地址,就像 一个 Kubernetes Pod 中可以有多个容器,这些容器之间共享网络命名空间,使用同一个 IP 地址。这些共享同一个地址的容器,Cilium 将其组合起来,成为 Endpoint(端点)。 ↩︎



