
在 Kubernetes 集群中使用 MetalLB 作为 LoadBalancer(上)- Layer2
这是系列文章的上篇,下篇《在 Kubernetes 集群中使用 MetalLB 作为 LoadBalancer(下)- BGP》。
TL;DR
网络方面的知识又多又杂,很多又是系统内核的部分。原本自己不是做网络方面的,系统内核知识也薄弱。但恰恰是这些陌生的内容满满的诱惑,加上现在的工作跟网络关联更多了,逮住机会就学习下。
这篇以 Kubernetes LoadBalancer 为起点,使用 MetalLB 去实现集群的负载均衡器,在探究其工作原理的同时了解一些网络的知识。
由于 MetalLB 的内容有点多,一步步来,今天这篇仅介绍其中简单又容易理解的部分,不出意外还会有下篇(太复杂,等我搞明白先 :D)。
LoadBalancer 类型 Service
由于 Kubernets 中 Pod 的 IP 地址不固定,重启后 IP 会发生变化,无法作为通信的地址。Kubernets 提供了 Service 来解决这个问题,对外暴露。
Kubernetes 为一组 Pod 提供相同的 DNS 名和虚拟 IP,同时还提供了负载均衡的能力。这里 Pod 的分组通过给 Pod 打标签(Label )来完成,定义 Service 时会声明标签选择器(selector)将 Service 与 这组 Pod 关联起来。
根据使用场景的不同,Service 又分为 4 种类型:ClusterIP、NodePort、LoadBalancer 和 ExternalName,默认是 ClusterIP。这里不一一详细介绍,有兴趣的查看 Service 官方文档。
除了今天的主角 LoadBalancer 外,其他 3 种都是比较常用的类型。LoadBalancer 官方的解释是:
使用云提供商的负载均衡器向外部暴露服务。 外部负载均衡器可以将流量路由到自动创建的 NodePort 服务和 ClusterIP 服务上。

看到“云提供商提供”几个字时往往望而却步,有时又需要 LoadBalancer 对外暴露服务做些验证工作(虽然除了 7 层的 Ingress 以外,还可以使用 NodePort 类型的 Service),而 Kubernetes 官方并没有提供实现。比如下面要介绍的 MetalLB 就是个不错的选择。
MetalLB 介绍
MetalLB 是裸机 Kubernetes 集群的负载均衡器实现,使用标准路由协议。
注意: MetalLB 目前还是 beta 阶段。
前文提到 Kubernetes 官方并没有提供 LoadBalancer 的实现。各家云厂商有提供实现,但假如不是运行在这些云环境上,创建的 LoadBalancer Service 会一直处于 Pending 状态(见下文 Demo 部分)。
MetalLB 提供了两个功能:
- 地址分配:当创建 LoadBalancer Service 时,MetalLB 会为其分配 IP 地址。这个 IP 地址是从预先配置的 IP 地址库获取的。同样,当 Service 删除后,已分配的 IP 地址会重新回到地址库。
- 对外广播:分配了 IP 地址之后,需要让集群外的网络知道这个地址的存在。MetalLB 使用了标准路由协议实现:ARP、NDP 或者 BGP。
广播的方式有两种,第一种是 Layer 2 模式,使用 ARP(ipv4)/NDP(ipv6) 协议;第二种是 BGP。
今天主要介绍简单的 Layer 2 模式,顾名思义是 OSI 二层的实现。
具体实现原理,看完 Demo 再做分析,等不及的同学请直接跳到最后。
运行时
MetalLB 运行时有两种工作负载:
- Controller:Deployment,用于监听 Service 的变更,分配/回收 IP 地址。
- Speaker:DaemonSet,对外广播 Service 的 IP 地址。
Demo
安装之前介绍下网络环境,Kubernetes 使用 K8s 安装在 Proxmox 的虚拟机上。
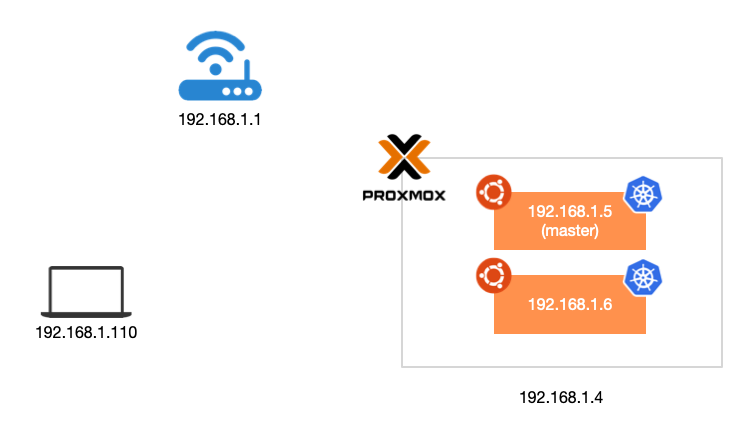
安装 K3s
安装 K3s,这里需要通过 --disable servicelb 禁用 k3s 默认的 servicelb。
参考 K3s 文档,默认情况下 K3s 使用 Traefik ingress 控制器 和 Klipper Service 负载均衡器来对外暴露服务。
curl -sfL https://get.k3s.io | sh -s - --disable traefik --disable servicelb --write-kubeconfig-mode 644 --write-kubeconfig ~/.kube/config
创建工作负载
使用 nginx 镜像,创建两个工作负载:
kubectl create deploy nginx --image nginx:latest --port 80 -n default
kubectl create deploy nginx2 --image nginx:latest --port 80 -n default
同时为两个 Deployment 创建 Service,这里类型选择 LoadBalancer:
kubectl expose deployment nginx --name nginx-lb --port 8080 --target-port 80 --type LoadBalancer -n default
kubectl expose deployment nginx2 --name nginx2-lb --port 8080 --target-port 80 --type LoadBalancer -n default
检查 Service 发现状态都是 Pending 的,这是因为安装 K3s 的时候我们禁用了 LoadBalancer 的实现:
kubectl get svc -n default
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 14m
nginx-lb LoadBalancer 10.43.108.233 <pending> 8080:31655/TCP 35s
nginx2-lb LoadBalancer 10.43.26.30 <pending> 8080:31274/TCP 16s
这时就需要 MetalLB 登场了。
安装 MetalLB
使用官方提供 manifest 来安装,目前最新的版本是 0.12.1。此外,还可以其他安装方式供选择,比如 Helm、Kustomize 或者 MetalLB Operator。
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/namespace.yaml
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/metallb.yaml
kubectl get po -n metallb-system
NAME READY STATUS RESTARTS AGE
speaker-98t5t 1/1 Running 0 22s
controller-66445f859d-gt9tn 1/1 Running 0 22s
此时再检查 LoadBalancer Service 的状态仍然是 Pending 的,嗯?因为,MetalLB 要为 Service 分配 IP 地址,但 IP 地址不是凭空来的,而是需要预先提供一个地址库。
这里我们使用 Layer 2 模式,通过 Configmap 为其提供一个 IP 段:
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 192.168.1.30-192.168.1.49
此时再查看 Service 的状态,可以看到 MetalLB 为两个 Service 分配了 IP 地址 192.168.1.30、192.168.1.31:
kubectl get svc -n default
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 28m
nginx-lb LoadBalancer 10.43.201.249 192.168.1.30 8080:30089/TCP 14m
nginx2-lb LoadBalancer 10.43.152.236 192.168.1.31 8080:31878/TCP 14m
可以请求测试下:
curl -I 192.168.1.30:8080
HTTP/1.1 200 OK
Server: nginx/1.21.6
Date: Wed, 02 Mar 2022 15:31:15 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 25 Jan 2022 15:03:52 GMT
Connection: keep-alive
ETag: "61f01158-267"
Accept-Ranges: bytes
curl -I 192.168.1.31:8080
HTTP/1.1 200 OK
Server: nginx/1.21.6
Date: Wed, 02 Mar 2022 15:31:18 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 25 Jan 2022 15:03:52 GMT
Connection: keep-alive
ETag: "61f01158-267"
Accept-Ranges: bytes
macOS 本地使用 arp -a 查看 ARP 表可以找到这两个 IP 及 mac 地址,可以看出两个 IP 都绑定在同一个网卡上,此外还有虚拟机的 IP 地址。也就是说 3 个 IP 绑定在该虚拟机的 en0 上:
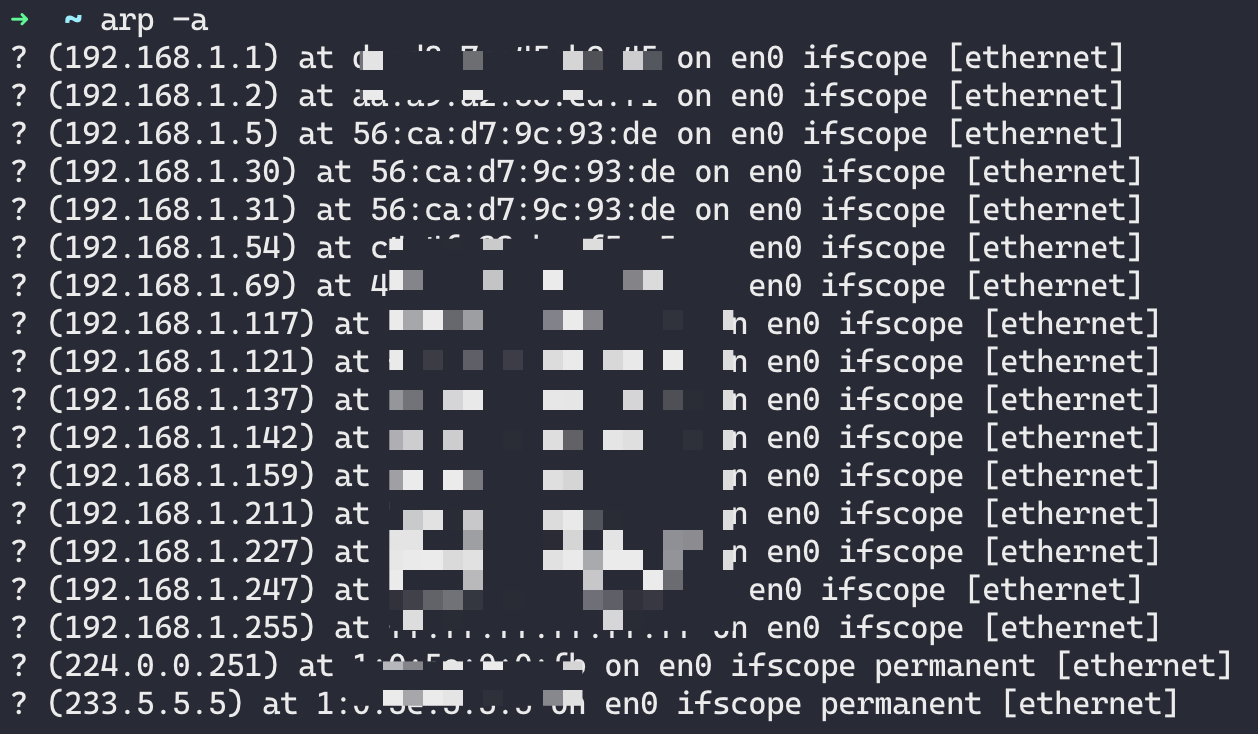
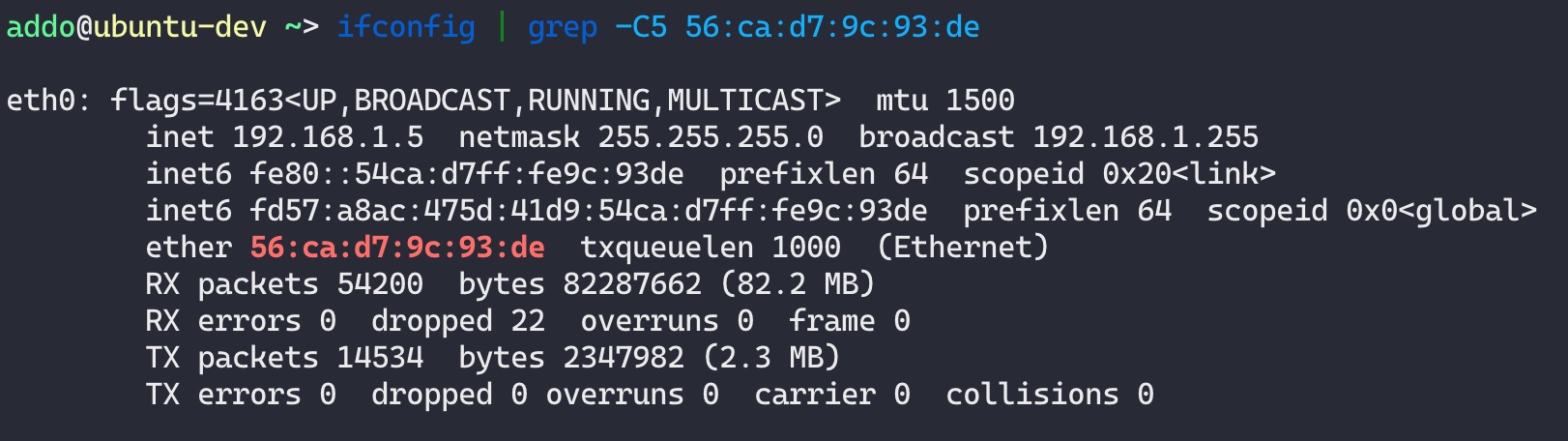
而去虚拟机(节点)查看网卡(这里只能看到系统绑定的 IP):
Layer 2 工作原理
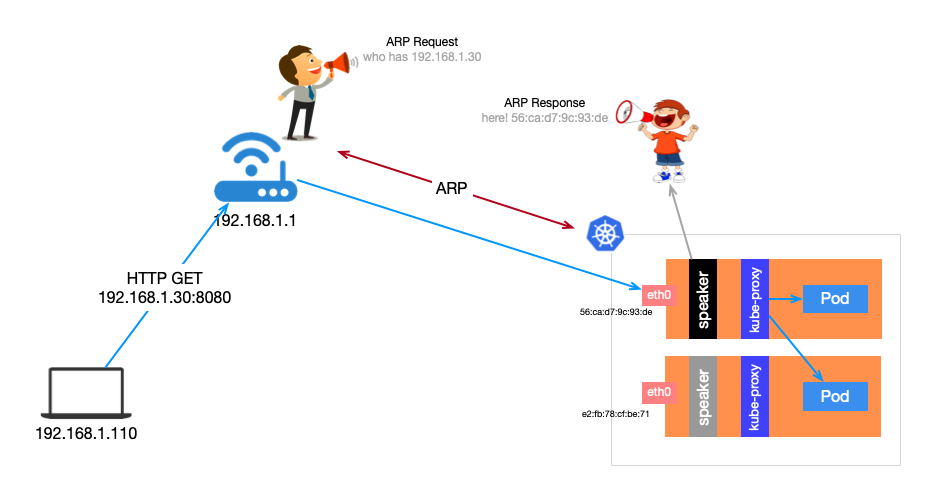
Layer 2 中的 Speaker 工作负载是 DeamonSet 类型,在每台节点上都调度一个 Pod。首先,几个 Pod 会先进行选举,选举出 Leader。Leader 获取所有 LoadBalancer 类型的 Service,将已分配的 IP 地址绑定到当前主机到网卡上。也就是说,所有 LoadBalancer 类型的 Service 的 IP 同一时间都是绑定在同一台节点的网卡上。
当外部主机有请求要发往集群内的某个 Service,需要先确定目标主机网卡的 mac 地址(至于为什么,参考维基百科)。这是通过发送 ARP 请求,Leader 节点的会以其 mac 地址作为响应。外部主机会在本地 ARP 表中缓存下来,下次会直接从 ARP 表中获取。
请求到达节点后,节点再通过 kube-proxy 将请求负载均衡目标 Pod。所以说,假如Service 是多 Pod 这里有可能会再跳去另一台主机。
优缺点
优点很明显,实现起来简单(相对于另一种 BGP 模式下路由器要支持 BGP)。就像笔者的环境一样,只要保证 IP 地址库与集群是同一个网段即可。
当然缺点更加明显了,Leader 节点的带宽会成为瓶颈;与此同时,可用性欠佳,故障转移需要 10 秒钟的时间(每个 speaker 进程有个 10s 的循环)。



