
Obsidian Skills:让 AI 智能体精通 Obsidian 知识管理
TL;DR
Obsidian Skills 不仅仅是一个技能包,它标志着 Agent Skills 生态正在从通用技能向垂直领域深度集成演进。过去,Agent Skills 主要侧重于任务类型的通用能力,比如代码审查、PDF 处理等广泛适用的场景。而 Obsidian Skills 的出现代表了一个重要转折点,工具官方开始主动拥抱 AI 代理,为自己的产品创建官方维护的专属技能包。这种垂直领域技能的价值在于深入理解工具的设计哲学,掌握最佳实践和惯用模式,与插件生态无缝对接,并能跟随工具版本同步更新,为用户提供权威且完整的解决方案。
本文通过详细介绍 Obsidian Skills 的三个核心技能(Obsidian Markdown、Obsidian Bases、JSON Canvas),展示了 AI 智能体如何真正理解 Obsidian 的独特之处。两个实战案例进一步证明了这些技能的实用价值,通过 Base 技能管理阅读清单,通过 Canvas 技能可视化知识网络,让 AI 成为知识管理的得力助手。随着更多工具厂商跟进,垂直领域技能将成为 AI 代理与专业工具深度融合的标准模式,最终实现用自然语言操作复杂工具的愿景。
引言:从 Agent Skills 到垂直领域应用
两周前,我写了一篇关于 Agent Skills 深度解析:为 AI 代理构建可复用的技能生态系统 的文章,探讨了 Agent Skills 规范如何让 AI 智能体获得模块化、可复用的能力。文章发布后,很多读者对这个生态的发展前景表示乐观。
当时,我们主要关注的是通用技能 - 代码审查、PDF 处理、文档生成等适用于各种场景的技能。但 Agent Skills 的潜力远不止于此。
就在浏览 X 时,我发现了一个非常有意思的仓库:kepano/obsidian-skills。Kepano 是谁?Steph Ango,Obsidian 的 CEO。
这意味着什么?工具官方开始拥抱 Agent Skills 规范,并为自己的产品创建官方技能包。
这不仅仅是一个技能仓库那么简单。它标志着 Agent Skills 生态正在从通用技能向垂直领域深度集成演进。Obsidian Skills 成为了第一个由主流工具官方维护的 Agent Skills 实现。
本文将深入探讨:
- 为什么 Obsidian 需要专门的技能包?
- Obsidian Skills 包含哪些核心能力?
- AI 智能体如何使用这些技能?
- 这对整个 Agent Skills 生态意味着什么?
为什么 Obsidian 需要专门的技能包?
Obsidian 不只是 Markdown 编辑器
作为一名 Obsidian 的重度使用者,我已经使用 Obsidian 好几年了。从最初简单的 Markdown 笔记,到现在构建起包含数千篇笔记的个人知识库,Obsidian 早已成为我日常工作和学习不可或缺的工具。这几年的深度使用经验让我深刻理解到:Obsidian 远不只是一个 Markdown 编辑器。
在回答这个问题之前,我们需要先理解 Obsidian 的独特之处。
很多人初次接触 Obsidian 时,会把它当成一个 Markdown 编辑器。这就像把 Notion 当成文档编辑器,或者把 Figma 当成绘图软件一样 - 只看到了表面,错过了本质。
Obsidian 的三大核心理念:
本地优先(Local-first)
- 所有数据以纯文本形式存储在本地
- 你完全拥有和控制自己的数据
- 不依赖云服务,永远可访问
双向链接(Bi-directional Links)
- 不仅仅是链接到文件,而是建立知识网络
- 通过反向链接(backlinks)发现思维间的关联
- 知识图谱可视化思想的连接
可扩展性(Extensibility)
- 强大的社区插件生态(1000+ 插件)
- 可以深度定制工作流程
- 支持各种知识管理方法论(Zettelkasten、PARA、MOC 等)
关于 Obsidian 插件生态的深度实践
正是因为 Obsidian 强大的插件系统,让它能够满足各种个性化的知识管理需求。我之前写过几篇文章深入介绍 Obsidian 的插件生态:
- 提升 Obsidian 使用体验的插件与技巧 - 分享我日常使用的核心插件和配置技巧
- Image Upload Toolkit 稳定版发布 这是我开发的一个实用的图片上传插件
作为插件开发者,我深刻体会到 Obsidian 的可扩展性不仅体现在丰富的 API,更在于它开放的生态和活跃的社区。这种开放性也是 Obsidian Skills 能够成功的基础 - 当工具本身拥抱开放和扩展,官方发布 AI Agent Skills 就成为了自然的演进。
基于这些理念,Obsidian 发展出了一套独特的 Markdown 扩展语法和功能,这就是 Obsidian Flavored Markdown。
Obsidian 特有的概念
对比标准 Markdown,Obsidian 提供了独特的扩展功能:
- Wikilinks - 使用
[[笔记名]]语法,支持链接到标题[[笔记#标题]]和块[[笔记#^block-id]] - Callouts - 语义化信息框,如
> [!tip]> [!warning]> [!bug]等 - Embeds - 嵌入其他笔记
![[会议记录#核心决策]]实现 DRY 原则 - Properties - YAML 元数据配合 Dataview 查询,像数据库一样管理笔记
- Canvas - 可视化思维工具,使用开放的 JSON Canvas 格式
AI 智能体面临的挑战
理解了 Obsidian 的这些独特功能后,问题就显而易见了:
没有 Obsidian Skills 的 AI 智能体:
- 生成标准 Markdown 链接
[]() - 不知道 Callouts 语法,只会用简单的引用块
> - 不会添加 Properties 元数据
- 不理解 Block References 和 Embeds
- 无法生成 Canvas 文件
结果:内容虽然可读,但失去了 Obsidian 的核心价值 - 双向链接、知识网络、可查询元数据、内容复用等等。就像请了一个只会写纯文本的助手来管理复杂的知识库。
拥有 Obsidian Skills 的 AI 智能体:
- 使用 Wikilinks
[[]]建立知识网络 - 用合适类型的 Callouts 突出信息
- 添加结构化 Properties 便于查询
- 正确使用 Block References 和 Embeds
- 生成规范的 Canvas 文件
结果:原生 Obsidian 体验,充分利用工具的所有优势。
Obsidian Skills 深度解析
理解了为什么需要专门技能后,让我们深入了解 Obsidian Skills 提供了什么。
技能全貌
仓库结构:
kepano/obsidian-skills/
├── .claude-plugin/ # Claude Code 插件配置
├── skills/
│ ├── obsidian-markdown/ # Obsidian Flavored Markdown
│ ├── obsidian-bases/ # Obsidian Bases 格式
│ └── json-canvas/ # JSON Canvas 格式
├── LICENSE
└── README.md
三个核心技能,每个都针对 Obsidian 生态的不同方面。
技能 1:Obsidian Markdown - 核心技能
Obsidian Markdown 最重要的技能,覆盖了 Obsidian Flavored Markdown 的所有扩展语法。
覆盖的核心特性:
- 链接系统 - Wikilinks
[[]]、链接到标题和块、搜索链接 - 嵌入系统 - 嵌入笔记、图片、PDF、音频等
![[]] - Callouts - 13+ 种语义化标注框,支持可折叠和嵌套
- Properties - YAML frontmatter 支持多种数据类型
- Tags - 内联标签和嵌套标签
- Block References - 块引用和精确引用
- 高级格式 - 高亮、任务列表、Mermaid 图表、LaTeX 公式、注释等
通过这个技能,AI 可以生成包含完整 Obsidian 特性的笔记,充分利用双向链接、元数据查询、内容嵌入等功能。
我觉得这个技能对于熟练掌握了 Obsidian Flavored Markdown 语法的用户用处就不大了,而且我更喜欢自己记录笔记,因为记录的过程也是学习、整理和记忆的过程。
技能 2:Obsidian Bases - 结构化数据
Obsidian Bases 提供纯文本的结构化数据格式,适用于项目管理、联系人管理、库存管理等需要数据库功能的场景。
- 核心能力
- 创建/编辑 Base 记录(键值对、多行记录)
- 与 Markdown 笔记通过 Wikilinks 建立关联
- 按字段过滤/分组/排序,支持日期、枚举、布尔
- 由 AI 生成模板、批量导入/规范化字段
- 基本示例(单条记录;多条记录以空行分隔)
name: 任务:完善登录页
status: in-progress
priority: high
owner: [[张三]]
due: 2026-03-31
related: [[产品需求文档]]
- 典型用法
- 项目任务/里程碑台账(状态、负责人、Due、优先级)
- 轻量 CRM(联系人、公司、跟进记录)
- 物料/知识清单(来源、版本、标签)
技能 3:JSON Canvas - 可视化思维
JSON Canvas 是 Obsidian 的开放格式规范,用于描述无限画布。AI 可以生成思维导图、知识图谱、工作流程图等可视化内容。
- 核心能力
- 创建节点(text/file/link/group)与连线(edges)
- 将现有笔记作为 file 节点嵌入,形成可视化知识图谱
- 生成布局(坐标/尺寸)与分组,支持后续人工拖拽微调
- 最小示例
{
"nodes": [
{ "id": "n1", "type": "text", "text": "发布计划", "x": 0, "y": 0, "width": 200, "height": 60 },
{ "id": "n2", "type": "file", "file": "产品需求文档.md", "x": 280, "y": 0, "width": 380, "height": 300 }
],
"edges": [ { "id": "e1", "fromNode": "n1", "toNode": "n2" } ]
}
- 典型用法
- 需求→方案→任务链路图(将关键笔记嵌入,串联产出)
- 读书/论文的知识地图(概念节点 + 引用原文的文件节点)
- 研讨会/复盘的决策脉络图(分组归档,连线表达因果)
技术实现:AI 智能体如何使用这些技能
Obsidian Skills 采用 Agent Skills 规范的渐进式披露原则,关于这一原则的分析可以看 上一篇文章。简单来说:
首先是工作流程:
- 启动 - AI 加载技能元数据 (仅名称和描述,几百字节)
- 匹配 - 基于用户输入的关键词识别相关技能
- 激活 - 加载完整的技能指令 (10-20 KB)
- 执行 - 按照指令生成符合 Obsidian 规范的内容
效率提升也是很明显的:
- 传统方式:每次对话发送完整指令 (50-100 KB)
- Agent Skills:按需加载,减少 70-90% 的上下文消耗
安装
KiloCode(笔者常用) 原生支持 Agent Skills,安装最简单。这里使用工具 ai-agent-skills,但是其还没支持 KiloCode:
注意: ai-agent-skills 对 KiloCode 的支持已通过 PR #4 提交,目前正在审核中。合并后即可使用
--agent kilocode参数。目前可以将npx ai-agent-skills替换为npx github:addozhang/ai-agent-skills。
# 使用 AI Agent Skills CLI
npx ai-agent-skills install kepano/obsidian-skills --agent kilocode
命令行中有时我也会使用 OpenCode,OpenCode 也同样支持 Agent Skills。在 OpenCode 中安装:
# 使用 AI Agent Skills CLI
npx ai-agent-skills install kepano/obsidian-skills --agent opencode
检查安装情况
在 OpenCode 中输入 显示所有的 skill:
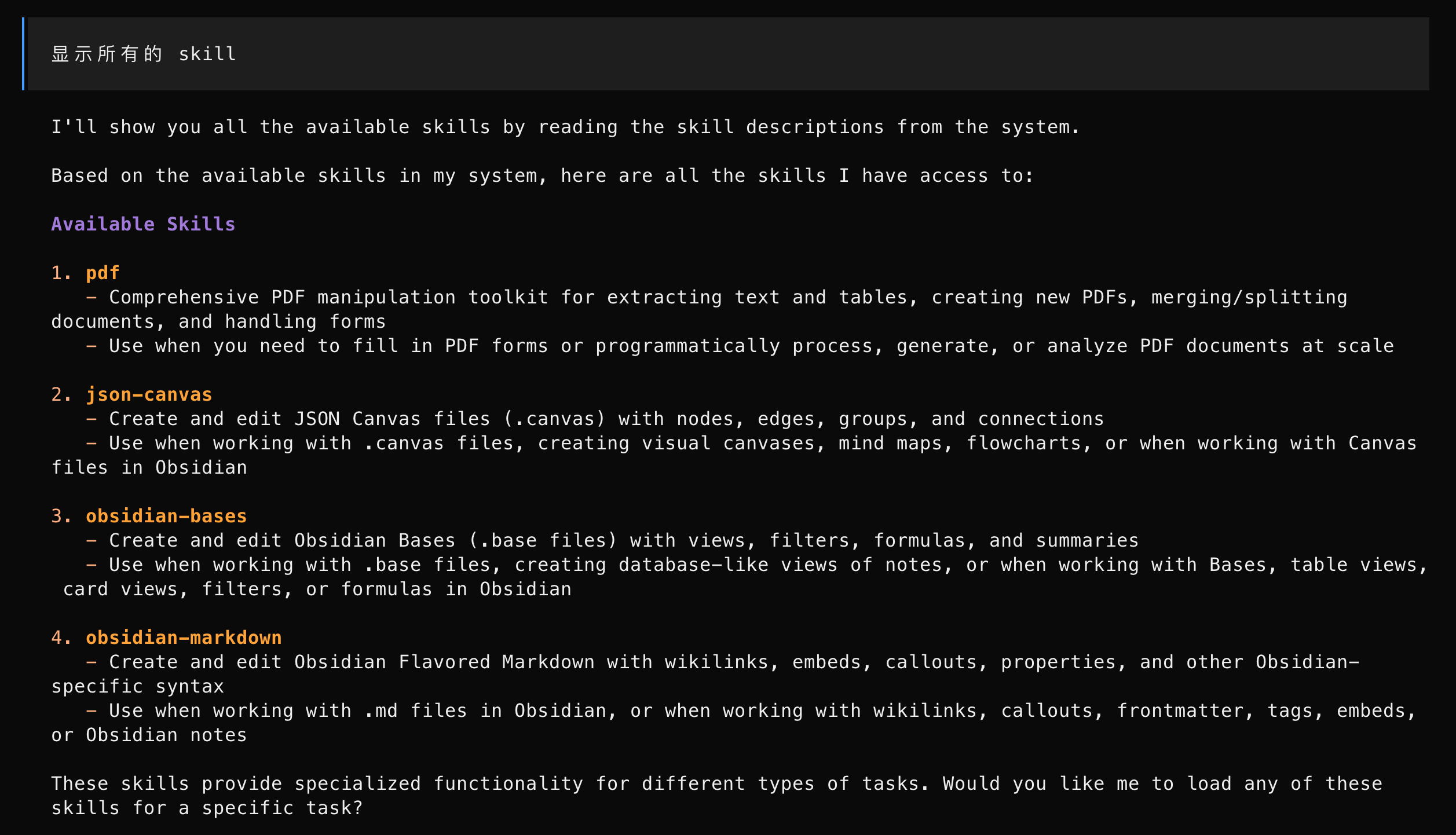
实战案例
通过两个真实的应用场景,看看 Obsidian Skills 如何解决实际问题。
案例 1:使用 Base 技能管理阅读清单
背景:作为一名技术从业者,我通过 Readwise 进行碎片化阅读,收集感兴趣的文章、推文和博客。Readwise 官方提供了 Obsidian 插件,可以自动同步高亮和笔记到本地知识库。但同步后的内容是独立的 Markdown 文件,缺少统一的视图来管理和浏览。
需求:想要创建一个 " 最近阅读文章 " 的视图,按时间倒序展示所有阅读过的文章,方便回顾和管理。
使用 Obsidian Skills 的解决方案:
通过简单的 prompt:
为所有 category 为 article 的 md 文件创建一个 base 视图,按照创建日期的倒序排序
AI 会自动识别并激活 Obsidian Bases 技能,根据 Base 格式规范生成符合标准的 .base 文件。
生成的 Base 文件示例 (阅读清单.base):
filters:
and:
- category == "articles"
formulas:
created_date: if(date, date(date).format("YYYY-MM-DD"), "")
days_since: if(date, date(date).relative(), "")
properties:
title:
displayName: 标题
author:
displayName: 作者
date:
displayName: 创建日期
formula.days_since:
displayName: 天数前
url:
displayName: 链接
views:
- type: table
name: 文章列表
groupBy:
property: date
direction: DESC
order:
- file.name
- title
- author
- date
- formula.days_since
- url
summaries:
file.name: Unique
columnSize:
note.date: 127
- type: cards
name: 卡片视图
order:
- file.name
- title
- author
- date
- url
视图:
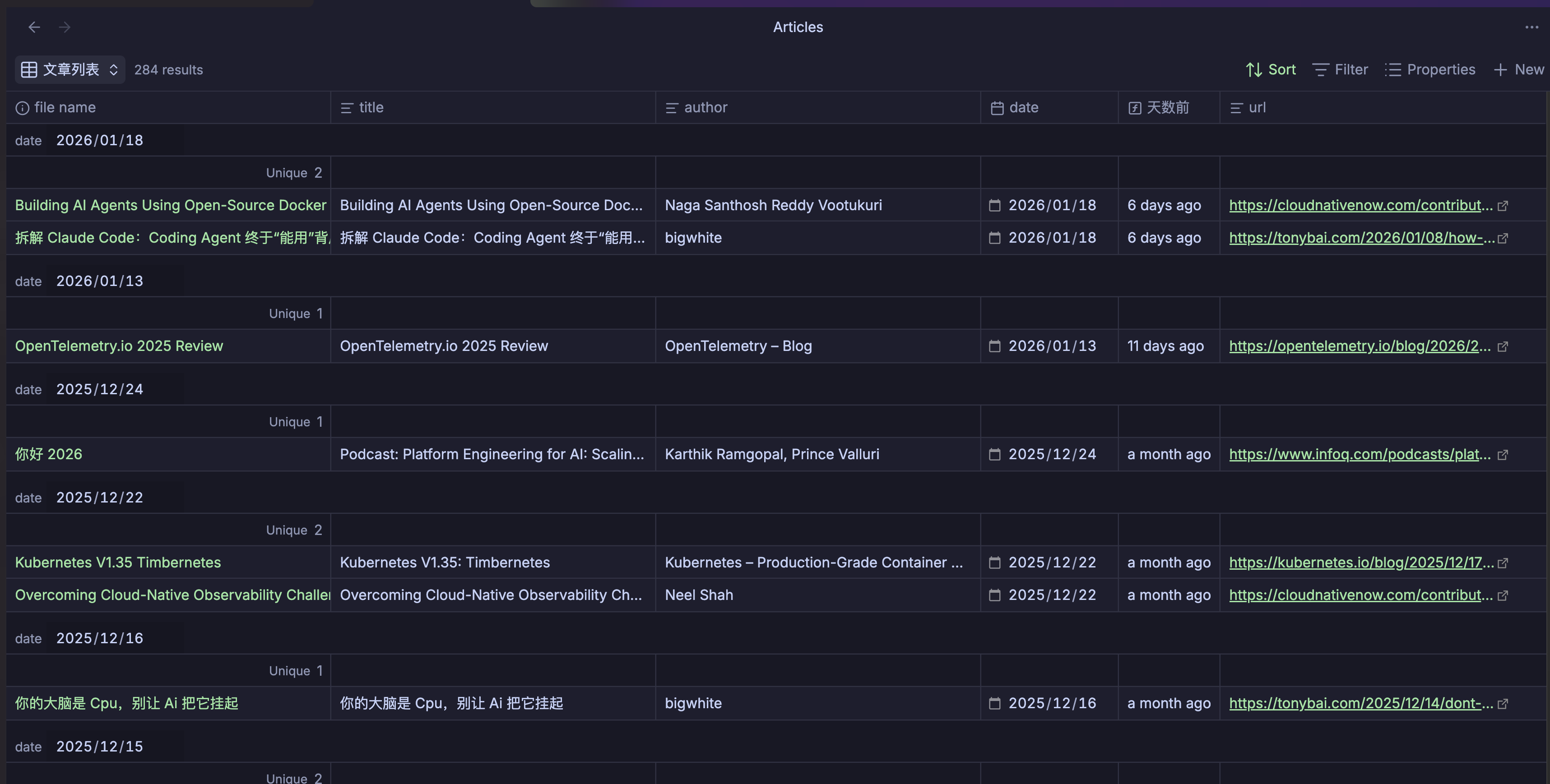
价值体现:
- 自动化管理:无需手动整理,AI 自动创建和维护视图
- 结构化数据:通过 Base 格式统一管理元数据
- 灵活筛选:可以按标签、日期、作者等维度筛选和排序
- 知识关联:通过 Wikilinks 链接到原文笔记,保持知识网络的连贯性
这个功能对于需要管理大量阅读材料的知识工作者特别有用 - 研究人员、博主、学生等都可以用类似方式管理自己的知识输入。
案例 2:使用 Canvas 技能可视化知识网络
背景:前几年我在 Kubernetes 网络方面写过多篇博客文章,涉及 CNI、Service Mesh、网络策略、Ingress 等多个主题。这些文章散落在 " 笔记 " 目录中,虽然有互相引用,但缺少一个全局视图来展示它们之间的关系。
需求:创建一个可视化的思维导图,将所有 Kubernetes 网络相关的笔记串联起来,形成一个清晰的知识地图。
使用 Obsidian Skills 的解决方案:
通过一个简单的 prompt:
根据我"笔记"目录中所有关于"kubernetes 网络"的内容,制作一个思维导图
AI 会自动识别并激活 JSON Canvas 技能,根据 Canvas 格式规范生成符合标准的 .canvas 文件,包含节点、分组和连线的完整布局。
创建的 “Kubernetes 网络思维导图.canvas“文件内容太长,就不贴上来了。
在 Obsidian 中打开后的效果:
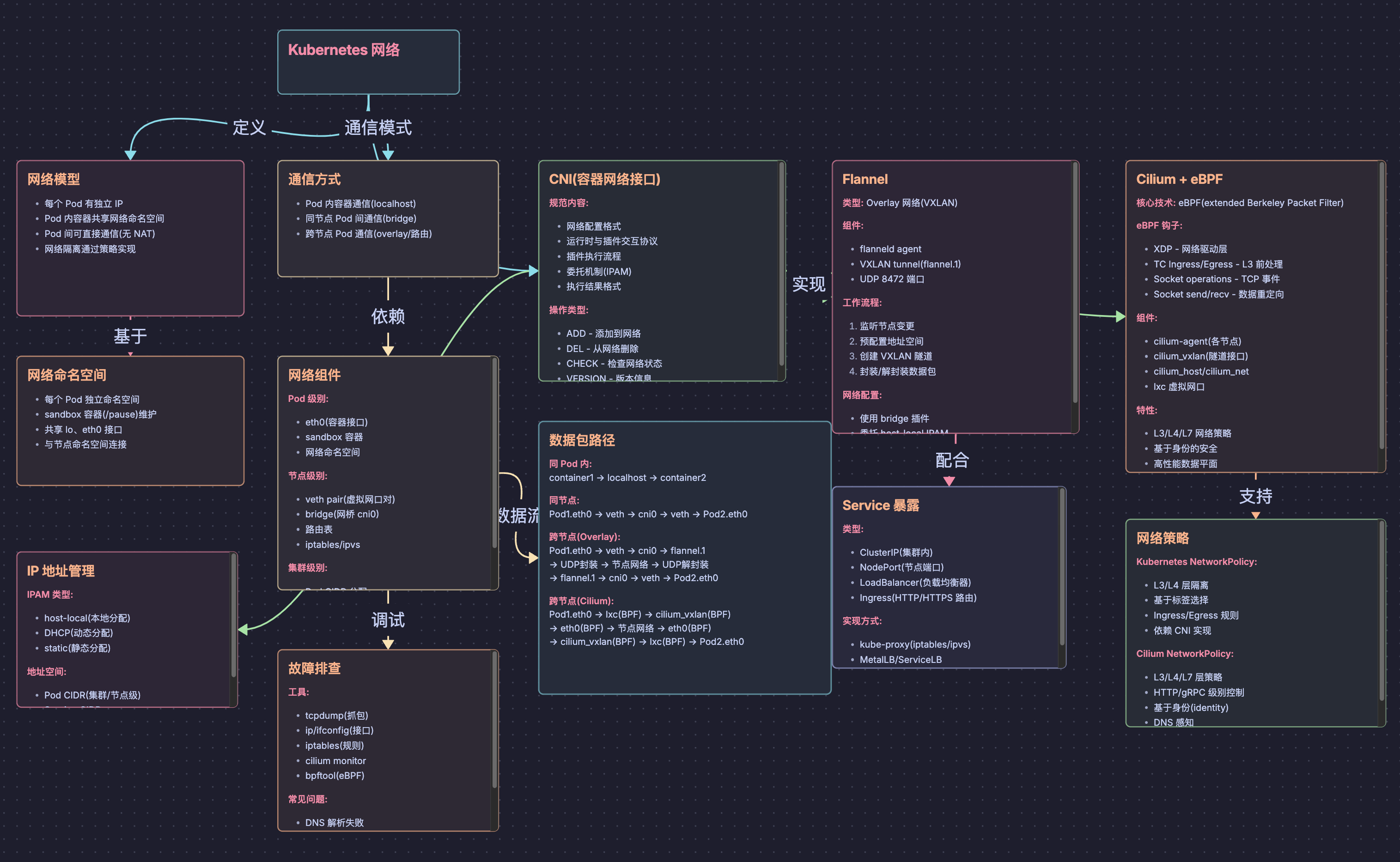
通过 Canvas Skill 可以实现
- 自动发现关联:AI 理解笔记之间的语义关系,无需手动指定连接
- 层次化组织:通过分组(Group)展示知识的层次结构
- 可视化知识网络:一目了然地看到各个主题之间的关系
- 动态更新:当添加新笔记时,可以快速更新 Canvas,保持知识图谱的完整性
- 嵌入原文:Canvas 中的节点是实际的笔记文件,可以直接查看和编辑内容
这种可视化特别适合:
- 学术研究:整理文献综述,梳理研究脉络
- 技术学习:构建知识体系,理清概念关系
- 项目管理:展示项目文档间的依赖关系
- 内容创作:规划系列文章的结构和关联



