15 Jun 2021
3 分钟阅读

源码解析:一文读懂 Kubelet
本文主要介绍 kubelet 功能、核心组件,以及启动流程的源码分析,总结了 kubelet 的工作原理。
kubelet 简介
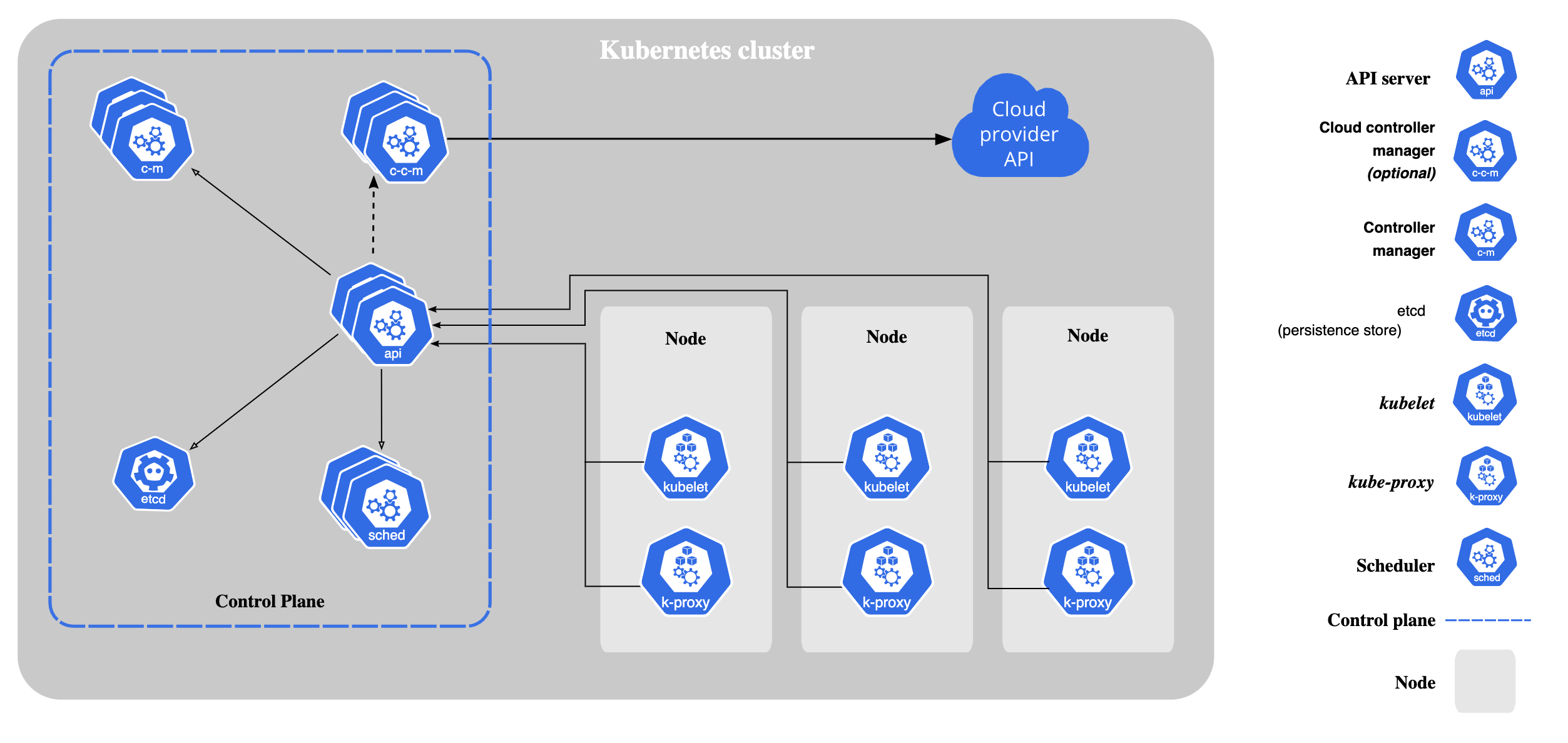
从官方的架构图中很容易就能找到 kubelet
执行 kubelet -h 看到 kubelet 的功能介绍:
- kubelet 是每个 Node 节点上都运行的主要“节点代理”。使用如下的一个向 apiserver 注册 Node 节点:主机的
hostname;覆盖host的参数;或者云提供商指定的逻辑。 - kubelet 基于
PodSpec工作。PodSpec是用YAML或者JSON对象来描述 Pod。Kubelet 接受通过各种机制(主要是 apiserver)提供的一组PodSpec,并确保里面描述的容器良好运行。
除了由 apiserver 提供 PodSpec,还可以通过以下方式提供: