可编程网关 Pipy 第二弹:编程实现 Metrics 及源码解读
由于要给团队做一下关于 Flomesh 的分享,准备下材料。
“分享是最好的学习方法。”
上一回初探可编程网关 Pipy,领略了 Pipy 的“风骚”。从 Pipy 的 GUI 交互深入了解了 Pipy 的配置加载流程。
今天看一下 Pipy 如何实现 Metrics 的功能,顺便看下数据如何在多个 Pipeline 中进行流转。
前置
首先,需要对 Pipy 有一定的了解,如果不了解看一下上一篇文章。
其次构建好 Pipy 环境,关于构建还是去看上一篇文章。
Metrics 功能实现
至于 Pipy 实现 Metrics 的方式,源码中就有,位于 test/006-metrics/pipy.js。
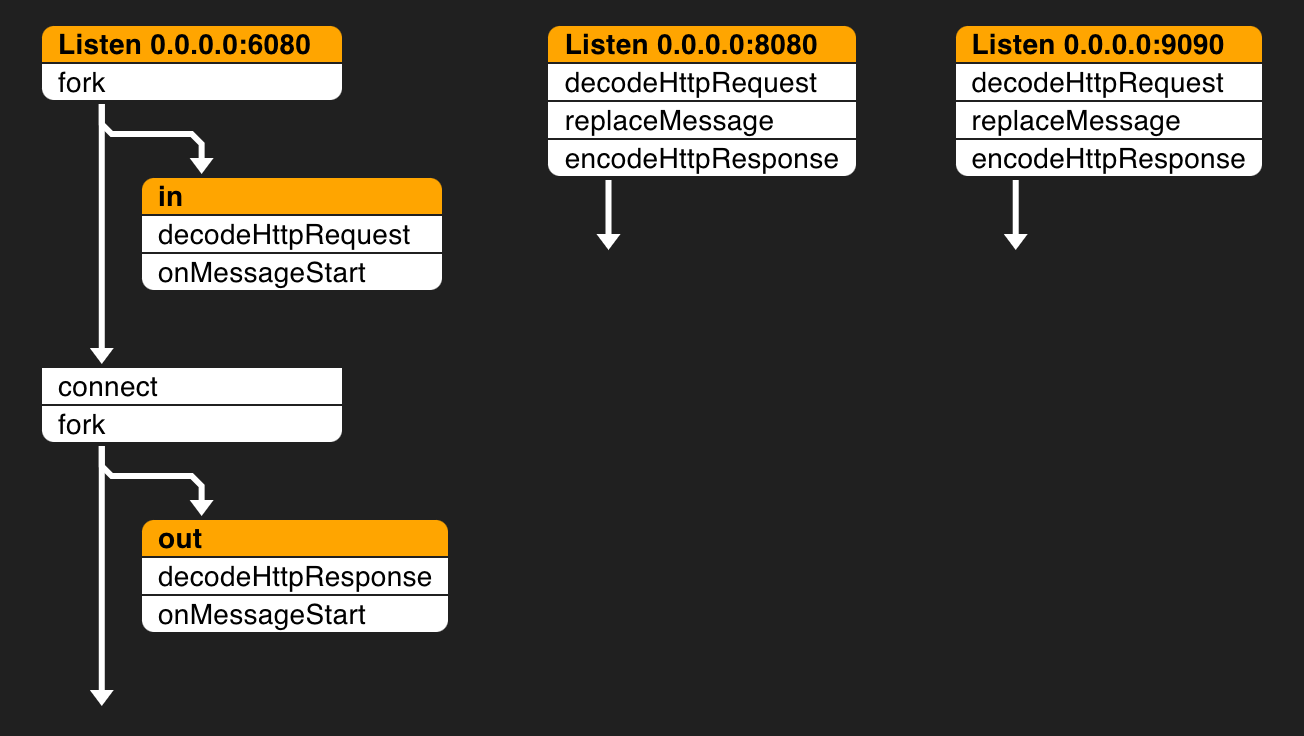
- 代理监听
6080端口,后端服务在8080端口,Metrics 在9090端口 - 共有 5 个 Pipeline:3 个 listen 类型,2 个 Pipeline 类型
- 7 种过滤器:
fork、connect、decodeHttpRequest、onMessageStart、decodeHttpResponse、encodeHttpRespnse、replaceMessage
贴一下源码:
pipy({
_metrics: {
count: 0,
},
_statuses: {},
_latencies: [
1,2,5,7,10,15,20,25,30,40,50,60,70,80,90,100,
200,300,400,500,1000,2000,5000,10000,30000,60000,
Number.POSITIVE_INFINITY
],
_buckets: [],
_timestamp: 0,
})
.listen(6080)
.fork('in')
.connect('127.0.0.1:8080')
.fork('out')
// Extract request info
.pipeline('in')
.decodeHttpRequest()
.onMessageStart(
() => (
_timestamp = Date.now(),
_metrics.count++
)
)
// Extract response info
.pipeline('out')
.decodeHttpResponse()
.onMessageStart(
e => (
((status, latency, i) => (
status = e.head.status,
latency = Date.now() - _timestamp,
i = _latencies.findIndex(t => latency <= t),
_buckets[i]++,
_statuses[status] = (_statuses[status]|0) + 1
))()
)
)
// Expose as Prometheus metrics
.listen(9090)
.decodeHttpRequest()
.replaceMessage(
() => (
(sum => new Message(
[
`count ${_metrics.count}`,
...Object.entries(_statuses).map(
([k, v]) => `status{code="${k}"} ${v}`
),
..._buckets.map((n, i) => `bucket{le="${_latencies[i]}"} ${sum += n}`)
]
.join('\n')
))(0)
)
)
.encodeHttpResponse()
// Mock service on port 8080
.listen(8080)
.decodeHttpRequest()
.replaceMessage(
new Message('Hello!\n')
)
.encodeHttpResponse()
测试
使用 ab 做请求模拟 ab -n 2000 -c 10 http://localhost:6080/,然后检查下记录的指标。
$ http :9090 --body
count 2000
status{code="200"} 2000
bucket{le="1"} 1762
bucket{le="2"} 1989
bucket{le="5"} 1994
bucket{le="7"} 1999
bucket{le="10"} 2000
分析
TL;DR:本次示例的核心是 fork,从字面意思就很容易理解:新开一个处理分支(Pipeline),与主线并行执行。
在 src/inbound.cpp:104 109 处,Pipy 接收一个新的连接。

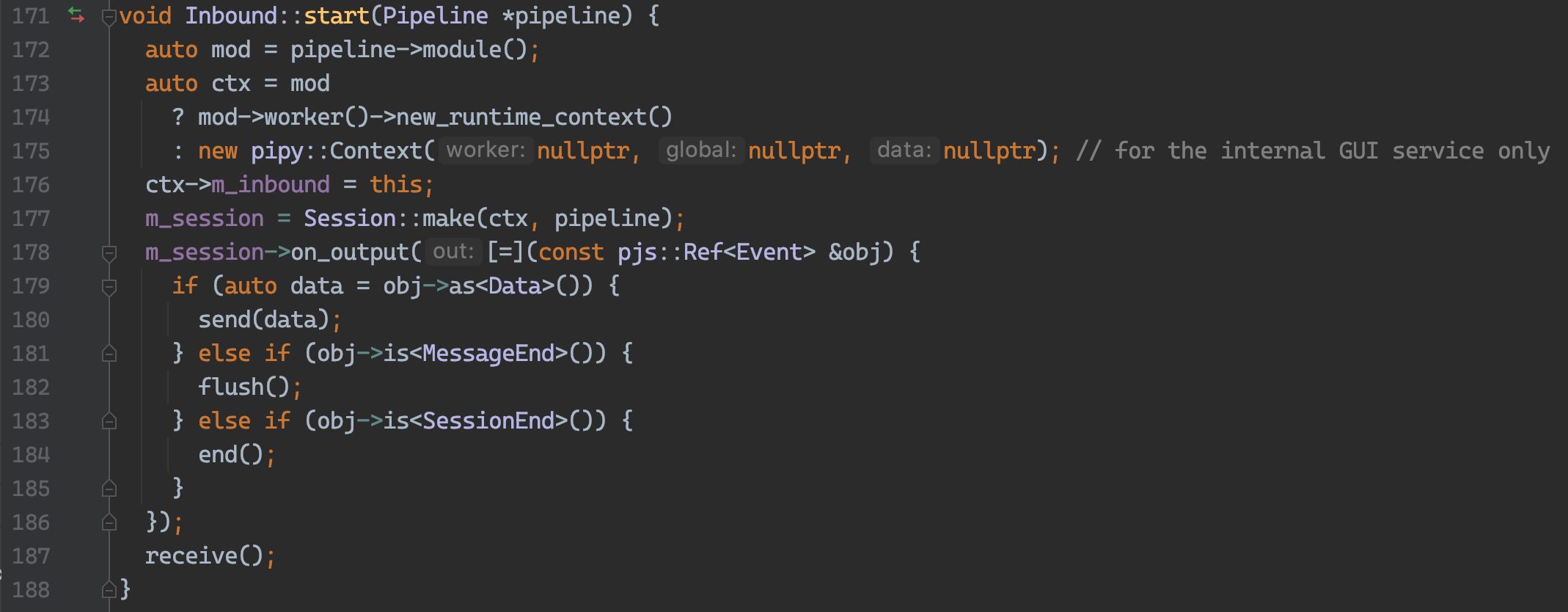
创建 Context 和 Session,并在 L178 处注册事件的处理器,然后在 L187 处开始接收数据。
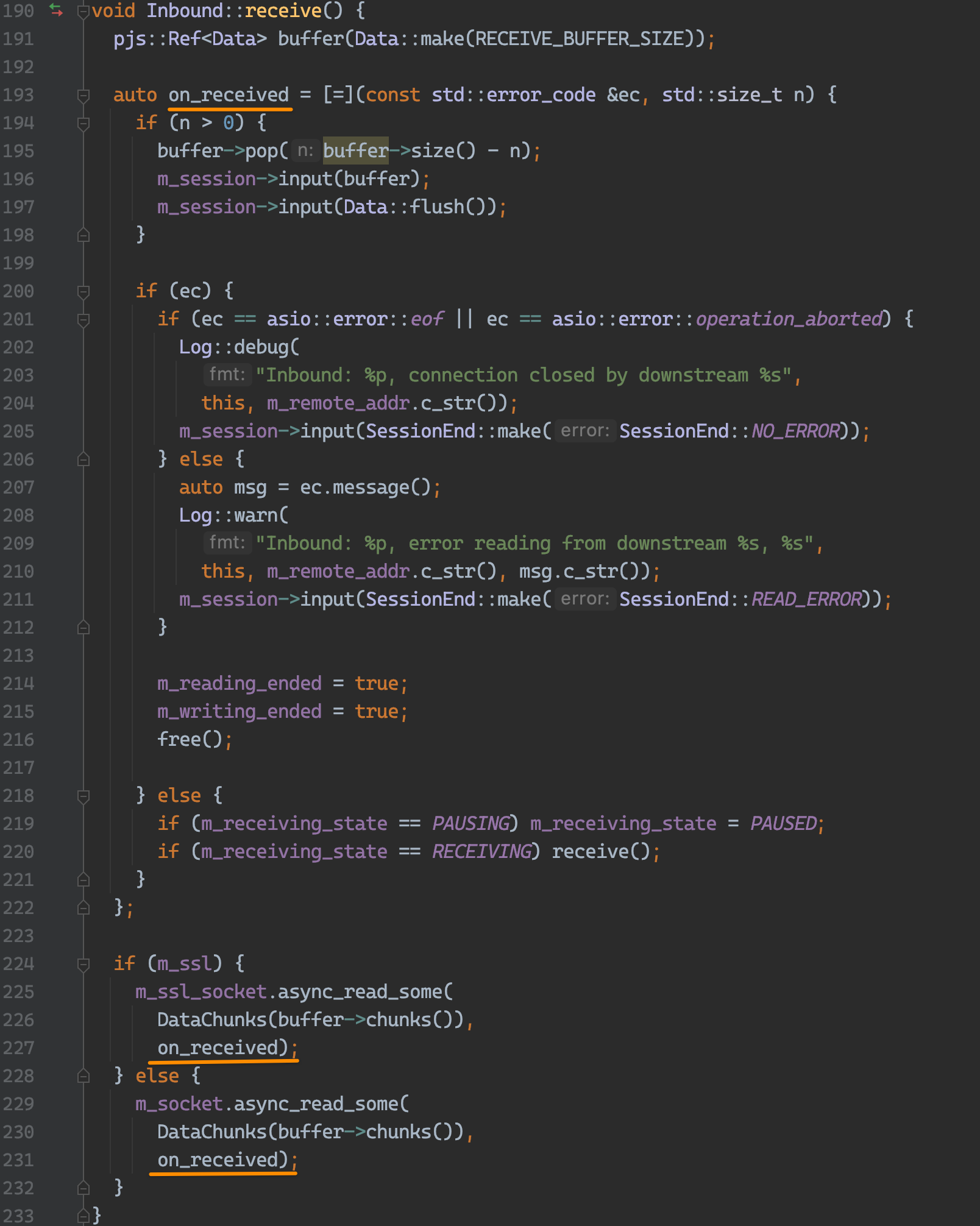
在 #receive 方法中,定义了数据接收处理器:将读到的数据写入 buffer 中。这个 buffer 存储的是 Event类型数据。(所以说 Pipy 是基于数据流事件,将一些封装成了事件)
接着调用 Session#input。
实际上调用的是 ReusableSession#input,调用 m_filters 的 #process 方法。m_filters 实际上是 Filter 类型。
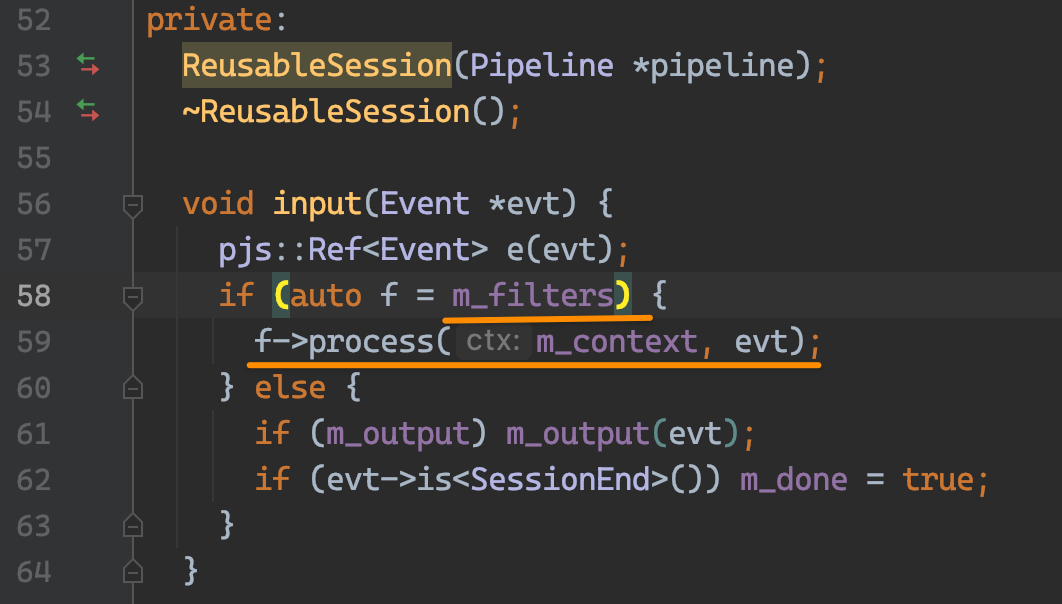
为什么只有一个 Filter?重点来了,看下 ReusableSession 的构造过程就能明白了(这里用了个反向迭代器)。output 是当前 Filter 处理完要执行的,实现类似链式的执行。
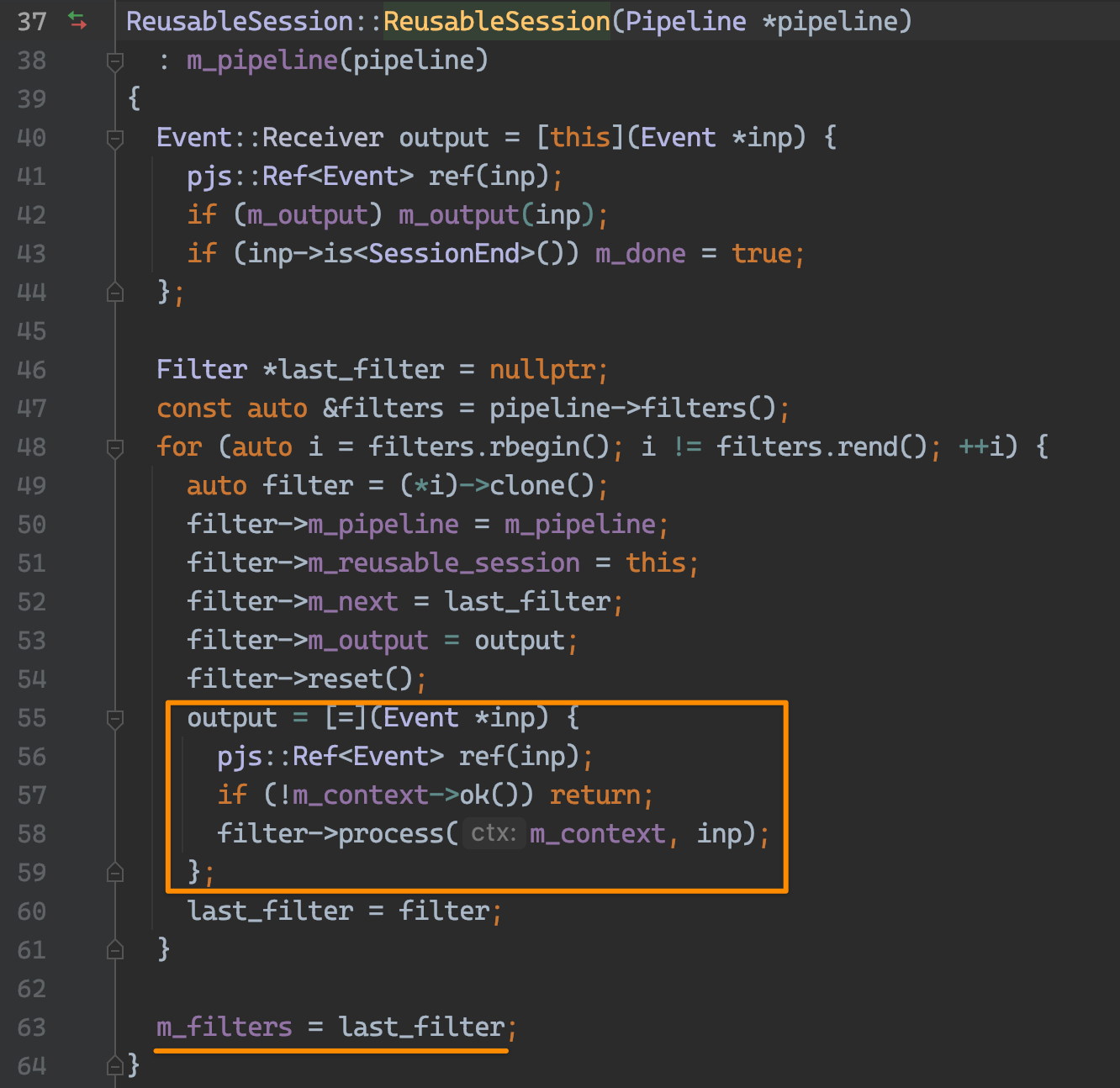
再回头看上面的示例,可以想象 fork 就是 Session 的 m_filters。
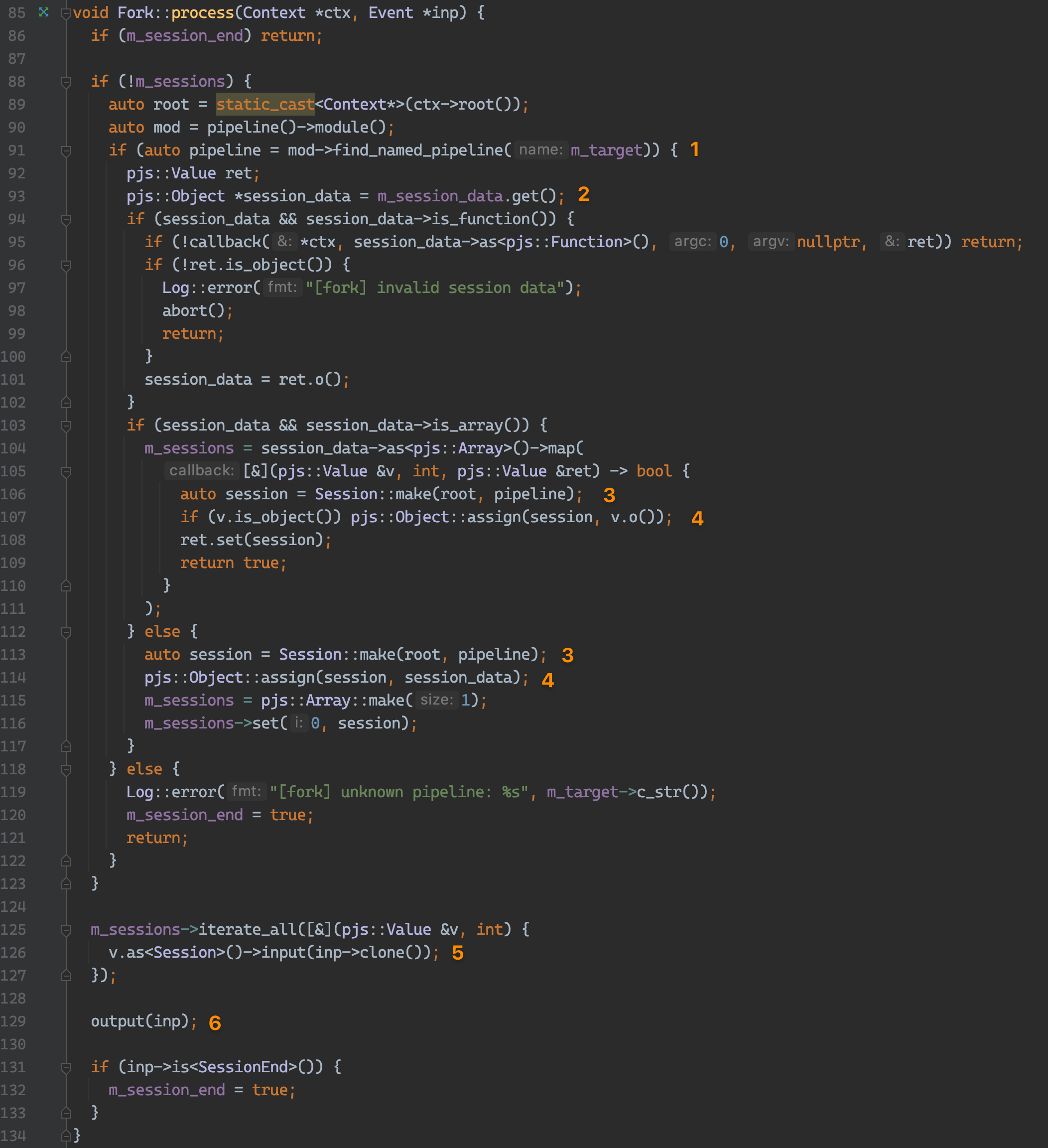
src/filters/fork.cpp:85,在 fork 过滤器中,在 1 处从 module 中获取到目标 Pipeline,并在 3 和 4 处 创建了新的 Session 并保存原 Session 的数据。
然后在 5 处将原 Event 输入到新的 Session 中,触发目标 Pipeline 的 Filter 链。值得注意的是,这里是基于事件的处理,并不是阻塞的。这就意味着,fork 的目标 pipline,与 fork 所在的 pipeline 是并行执行的。 在示例中,就是 Pipeline ‘in’ 与 主 Pipeline 的 connect 是并行执行的。
最终在 6 处,继续使用原 Session 的 Filter 链。