Kubernetes 的自动伸缩你用对了吗?
本文翻译自 learnk8s 的 Architecting Kubernetes clusters — choosing the best autoscaling strategy,有增删部分内容。
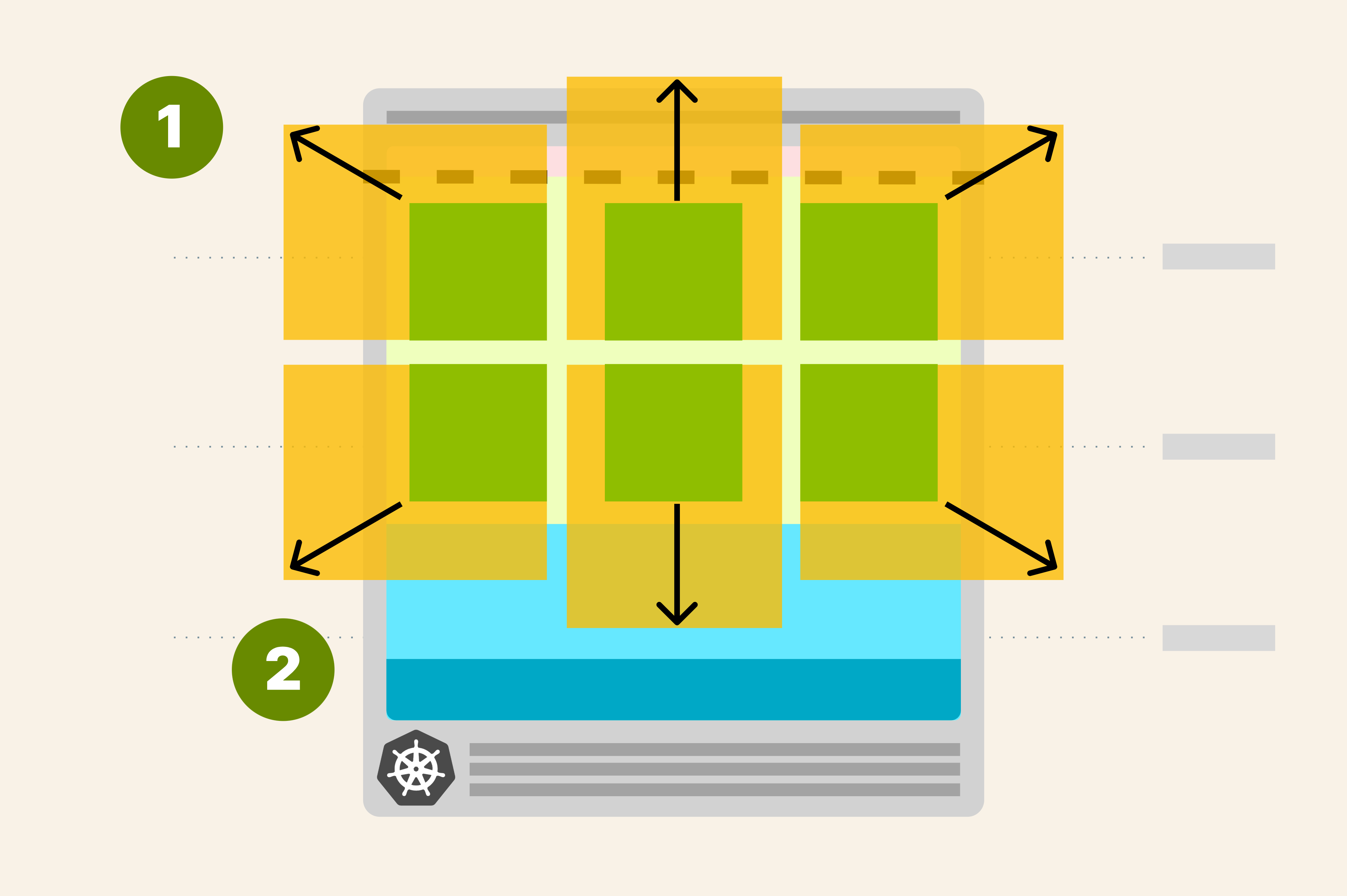
TL;DR: 在默认设置下,扩展 Kubernetes 集群中的 pod 和节点可能需要几分钟时间。了解如何调整集群节点的大小、配置水平和集群自动缩放器以及过度配置集群以加快扩展速度。
自动扩展器
在 Kubernetes 中,常说的“自用扩展”有:
不同类型的自动缩放器,使用的场景不一样。
HPA
HPA 定期检查内存和 CPU 等指标,自动调整 Deployment 中的副本数,比如流量变化:


VPA
有些时候无法通过增加 Pod 数来扩容,比如数据库。这时候可以通过 VPA 增加 Pod 的大小,比如调整 Pod 的 CPU 和内存:


CA
当集群资源不足时,CA 会自动配置新的计算资源并添加到集群中:


自动缩放 Pod 出错时
比如一个应用需要 1.5 GB 内存和 0.25 个 vCPU。一个 8GB 和 2 个 vCPU 的节点,可以容纳 4 个这样的 Pod,完美!
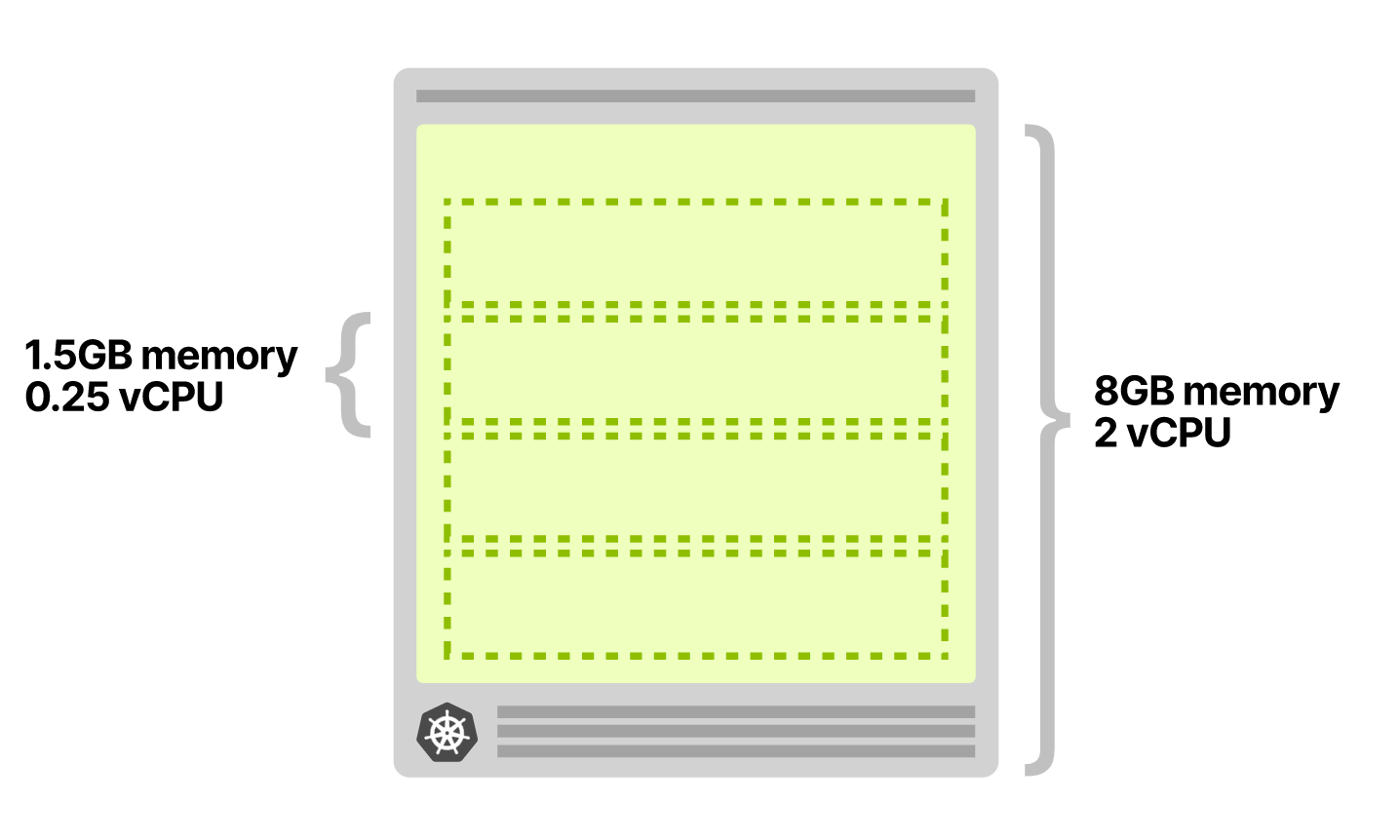
做如下配置:
- HPA:每增加 10 个并发,增加一个副本。即 40 个并发的时候,自动扩展到 4 个副本。(这里使用自定义指标,比如来自 Ingress Controller 的 QPS)
- CA:在资源不足的时候,增加计算节点。
当并发达到 30 的时候,系统是下面这样。完美!HPA 工作正常,CA 没工作。

当增加到 40 个并发的时候,系统是下面的情况:
- HPA 增加了一个 Pod
- Pod 挂起
- CA 增加了一个节点


为什么 Pod 没有部署成功?
节点上的操作系统进程和 kubelet 也会消耗一部分资源,8G 和 2 vCPU 并不是全都可以提供给 Pod 用的。并且还有一个驱逐阈值:在节点系统剩余资源达到阈值时,会驱逐 Pod,避免 OOM 的发生。
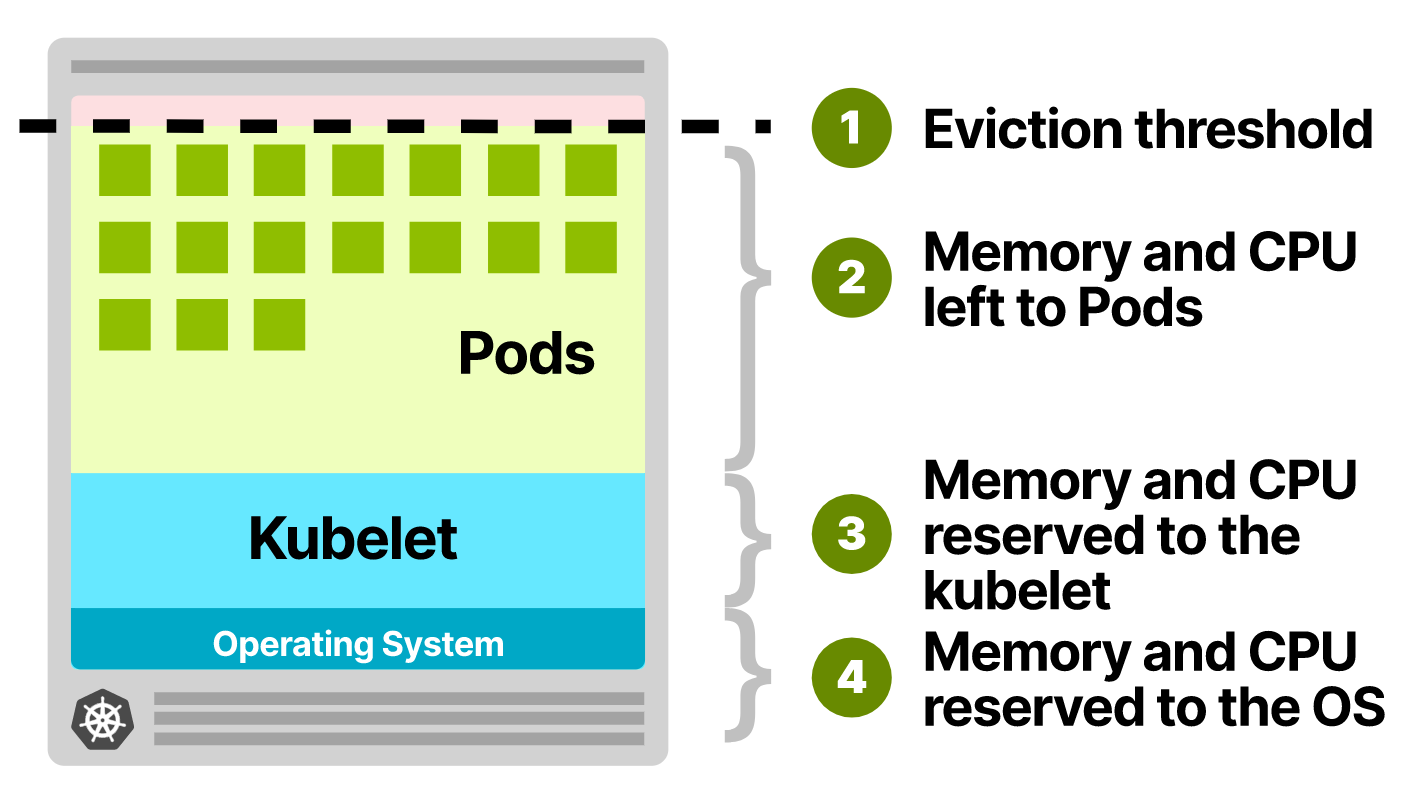
当然上面的这些都是可配置的。
那为什么在创建该 Pod 之前,CA 没有增加新的节点呢?
CA 如何工作?
CA 在触发自动缩放时,不会查看可用的内存或 CPU。
CA 是面向事件工作的,并每 10 秒检查一次是否存在不可调度(Pending)的 Pod。
当调度器无法找到可以容纳 Pod 的节点时,这个 Pod 是不可调度的。
此时,CA 开始创建新节点:CA 扫描集群并检查是否有不可调度的 Pod。
当集群有多种节点池,CA 会通过选择下面的一种策略:
random:默认的扩展器,随机选择一种节点池most-pods:能够调度最多 Pod 的节点池least-waste:选择扩展后,资源空闲最少的节点池price:选择成本最低的节点池priority:选择用户分配的具有最高优先级的节点池
确定类型后,CA 会调用相关 API 来创建资源。(云厂商会实现 API,比如 AWS 添加 EC2;Azure 添加 Virtual Machine;阿里云增加 ECS;GCP 增加 Compute Engine)
计算资源就绪后,就会进行节点的初始化。
注意,这里需要一定的耗时,通常比较慢。
探索 Pod 自动缩放的前置时间
四个因素:
- HPA 的响应耗时
- CA 的响应耗时
- 节点的初始化耗时
- Pod 的创建时间
默认情况下,kubelet 每 10 秒抓取一次 Pod 的 CPU 和内存占用情况。
每分钟,Metrics Server 会将聚合的指标开放给 Kubernetes API 的其他组件使用。

- 少于 100 个节点,且每个节点最多 30 个 Pod,时间不超过 30s。平均延迟大约 5s。
- 100 到 1000个节点,不超过 60s。平均延迟大约 15s。
节点的配置时间,取决于云服务商。通常在 3~5 分钟。

容器运行时创建 Pod:启动容器的几毫秒和下载镜像的几秒钟。如果不做镜像缓存,几秒到 1 分钟不等,取决于层的大小和梳理。

对于小规模的集群,最坏的情况是 6 分 30 秒。对于 100 个以上节点规模的集群,可能高达 7 分钟。
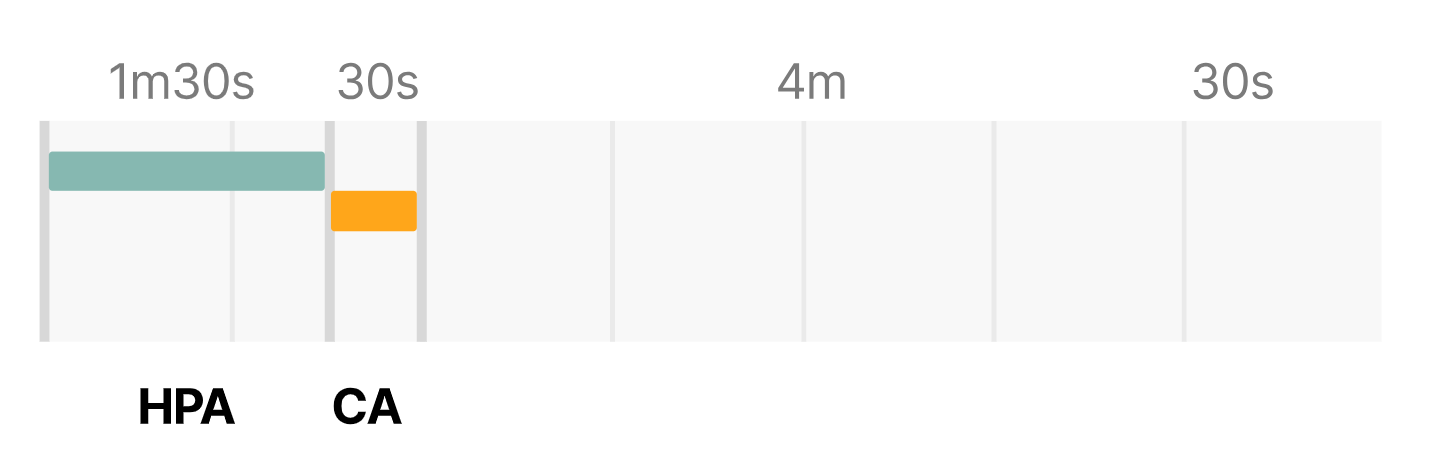
HPA delay: 1m30s +
CA delay: 0m30s +
Cloud provider: 4m +
Container runtime: 0m30s +
=========================
Total 6m30s
突发情况,比如流量激增,你是否愿意等这 7 分钟?
这 7 分钟,如何优化压缩?
- HPA 的刷新时间,默认 15 秒,通过
--horizontal-pod-autoscaler-sync-period标志控制。 - Metrics Server 的指标抓取时间,默认 60 秒,通过
metric-resolution控制。 - CA 的扫描间隔,默认 10 秒,通过
scan-interval控制。 - 节点上缓存镜像,比如 kube-fledged 等工具。
即使调小了上述设置,依然会受云服务商的时间限制。
那么,如何解决?
两种尝试:
- 尽量避免被动创建新节点
- 主动创建新节点
为 Kubernetes 选择最佳规格的节点
这会对扩展策略产生巨大影响。
这样的场景
应用程序需要 1GB 内存和 0.1 vCPU;有一个 4GB 内存和 1 个 vCPU 的节点。
排除操作系统、kubelet 和阈值保留空间后,有 2.5GB 内存和 0.7 个 vCPU 可用。
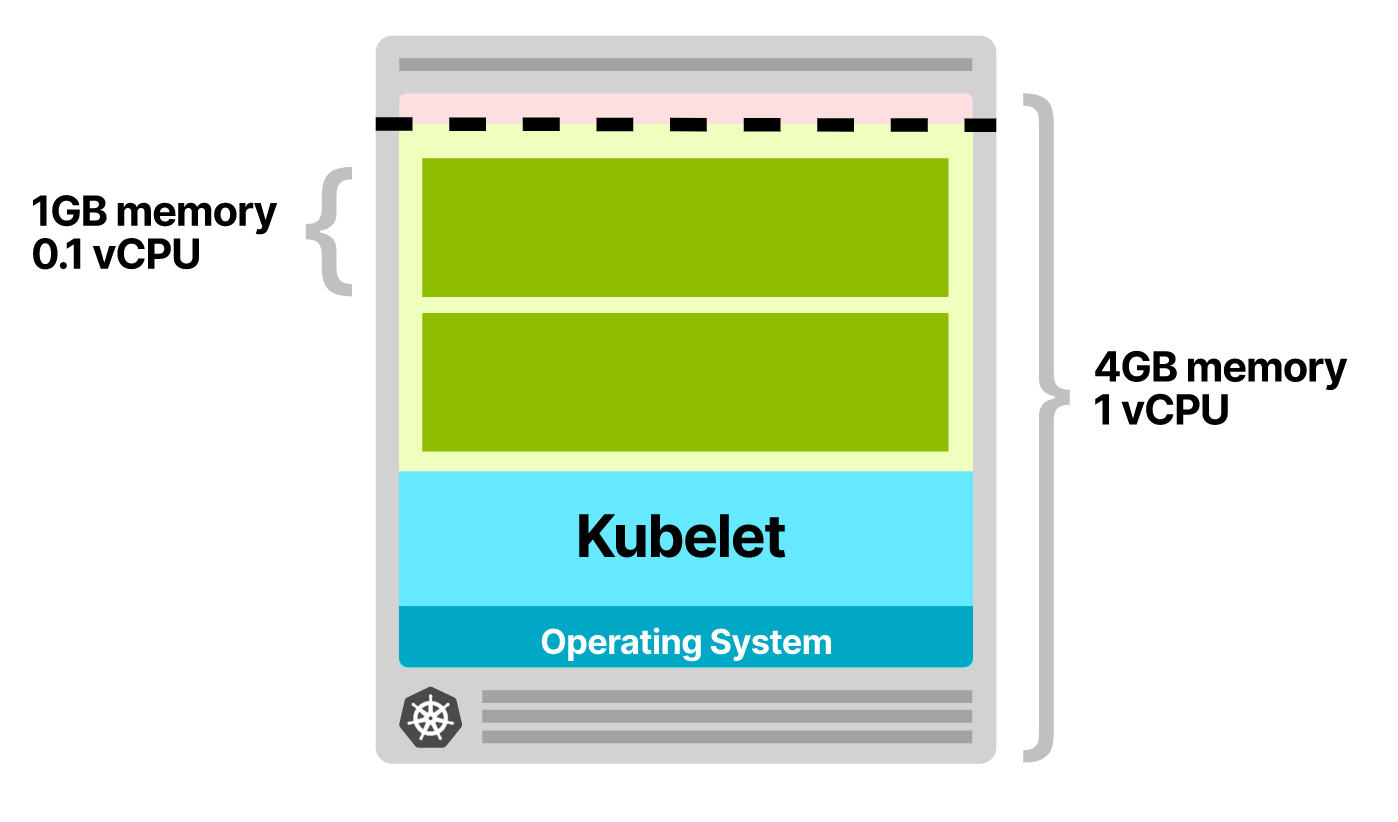
最多只能容纳 2 个 Pod,扩展副本时最长耗时 7 分钟(HPA、CA、云服务商的资源配置耗时)
假如节点的规格是 64GB 内存和 16 个 vCPU,可用的资源为 58.32GB 和 15.8 个 vCPU。
这个节点可以托管 58 个 Pod。只有扩容第 59 个副本时,才需要创建新的节点。
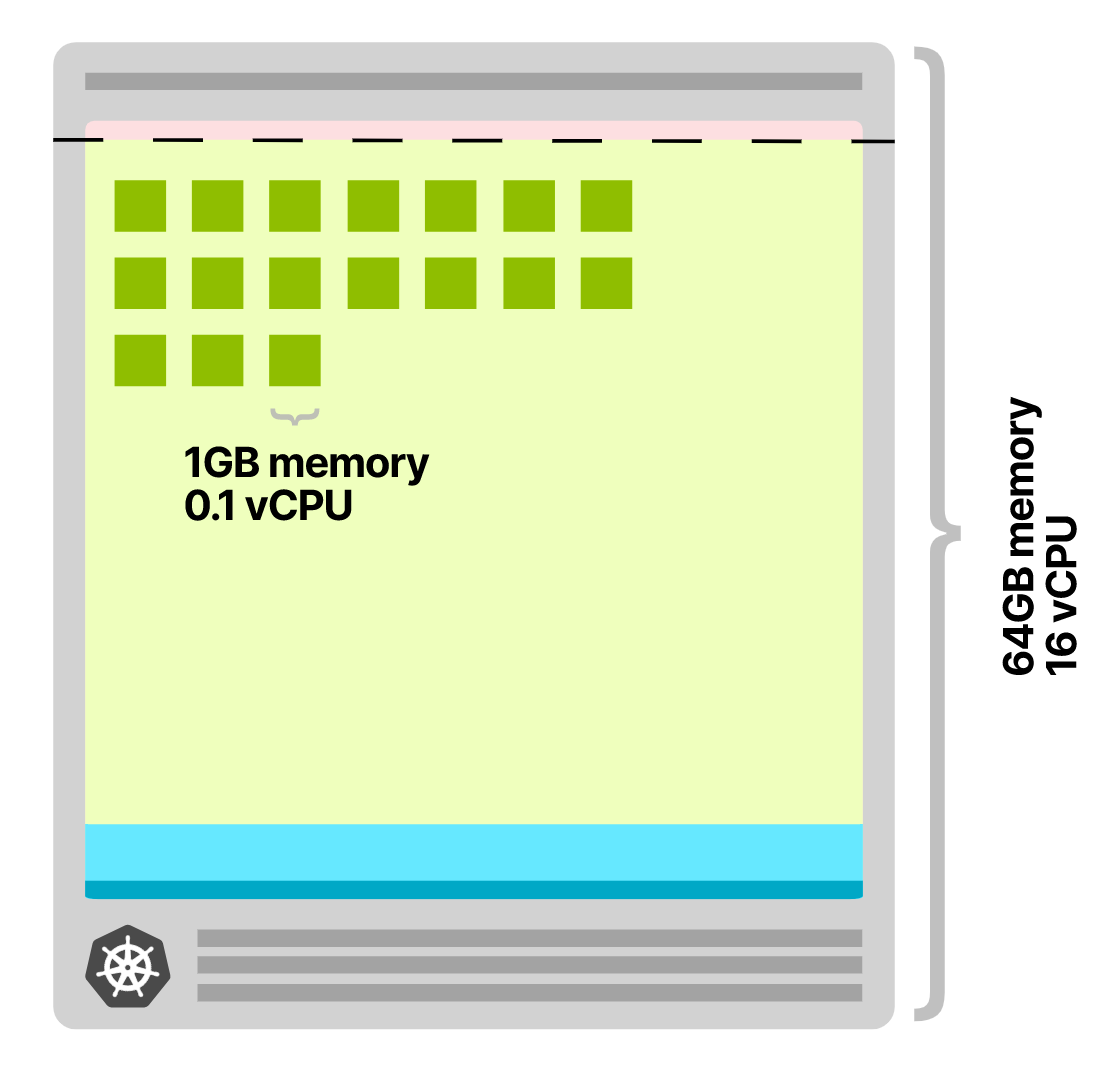
这样触发 CA 的机会更少。
选择大规格的节点,还有另外一个好处:资源的利用率会更高。
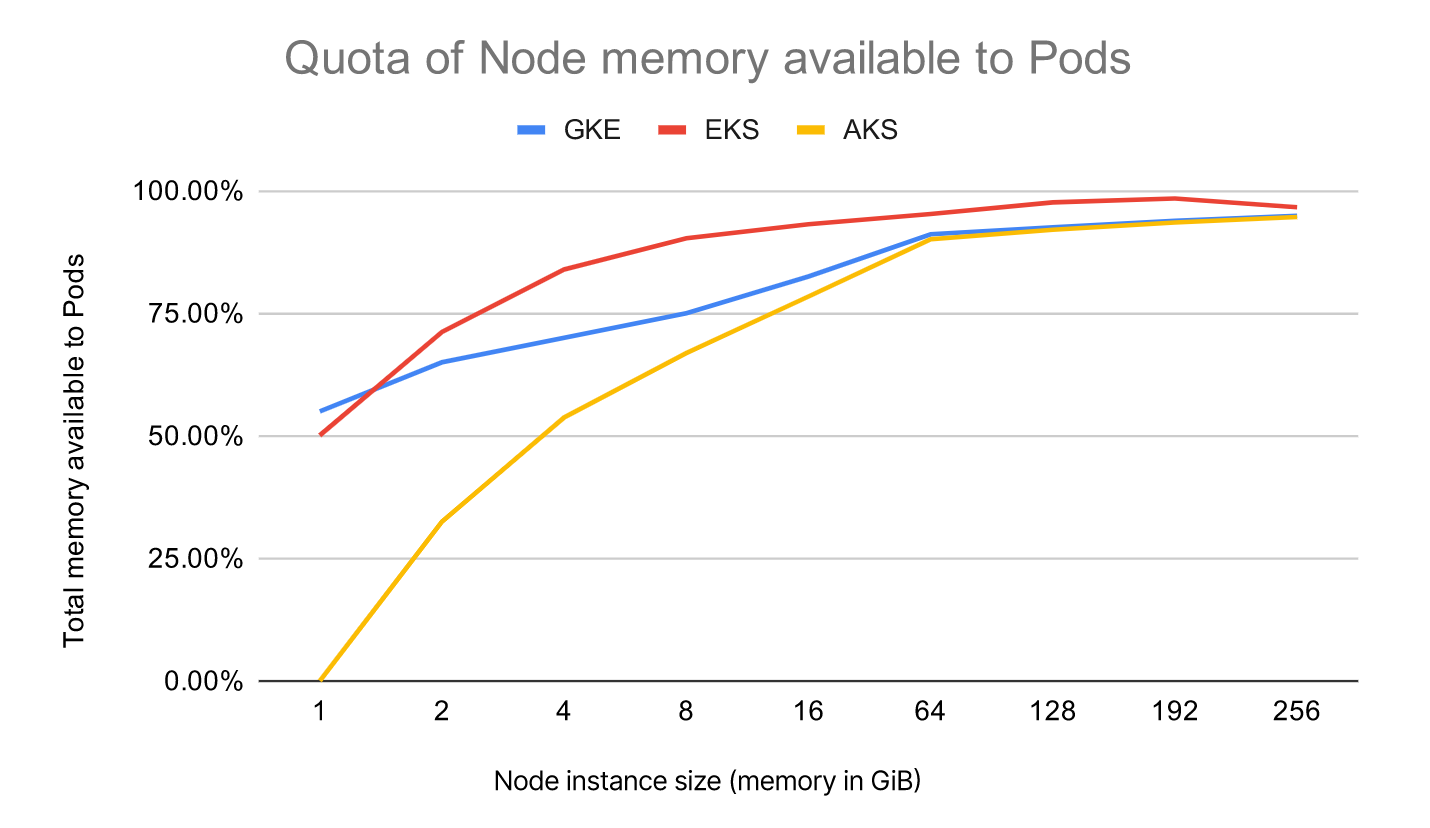
节点上可以容纳的 Pod 数量,决定了效率的峰值。
物极必反!更大的实例,并不是一个好的选择:
- 爆炸半径(Blast radius):节点故障时,少节点的集群和多节点的集群,前者影响更大。
- 自动缩放的成本效益低:增加一个大容量的节点,其利用率会比较低(调度过去的 Pod 数少)
即使选择了正确规格的节点,配置新的计算单元时,延迟仍然存在。怎么解决?
能否提前创建节点?
为集群过度配置节点
即为集群增加备用节点,可以:
- 创建一个节点,并留空 (比如 SchedulingDisabled)
- 一旦空节点中有了一个 Pod,马上创建新的空节点
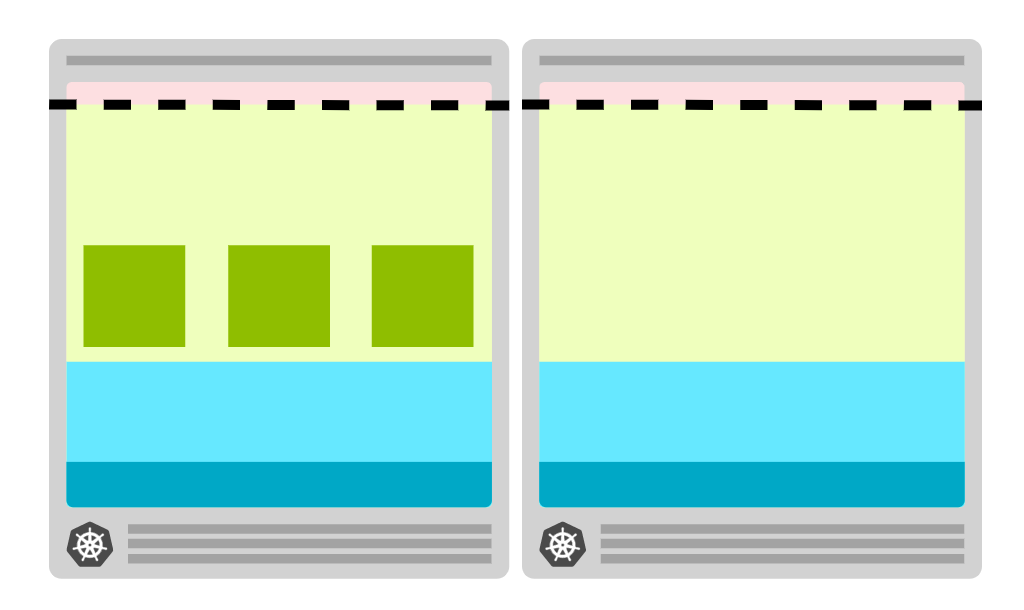
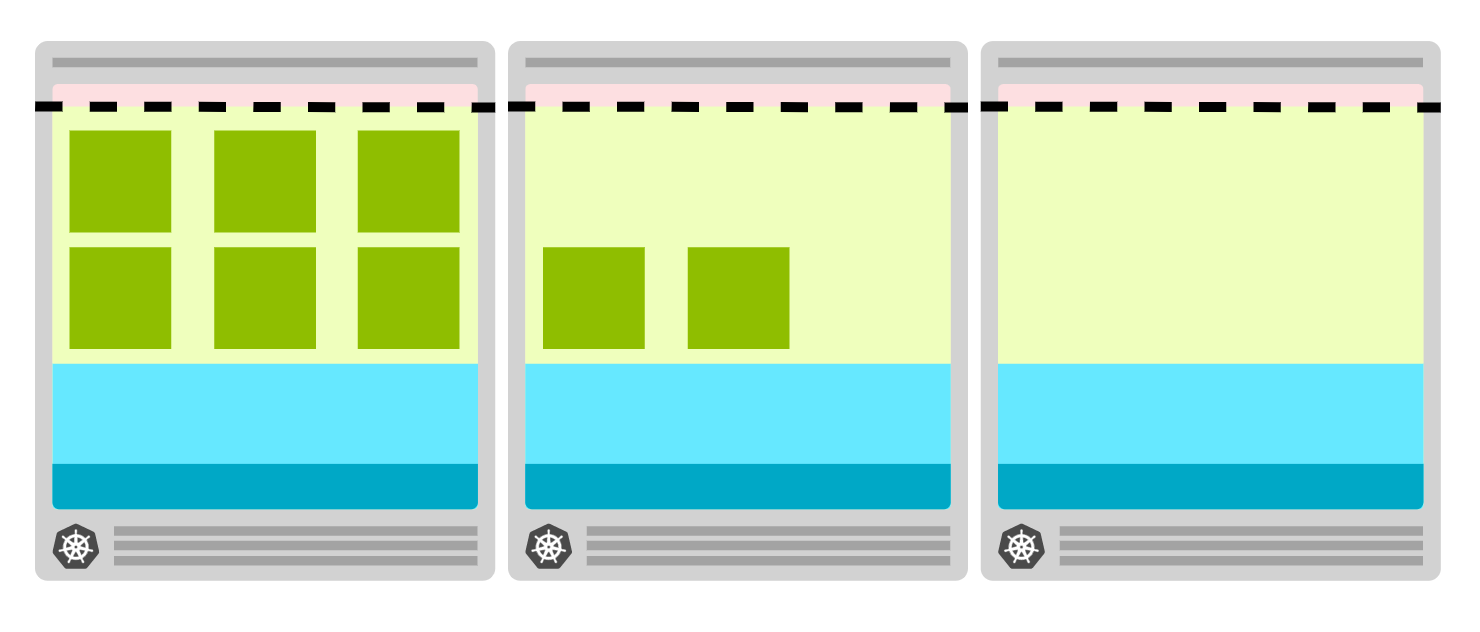
这种会产生额外的成本,但是效率会提升。
CA 并不支持此功能 – 总是保留一个空节点。
但是,可以伪造。创建一个只占用资源,不使用资源的 Pod 占用整个 Node 节点。
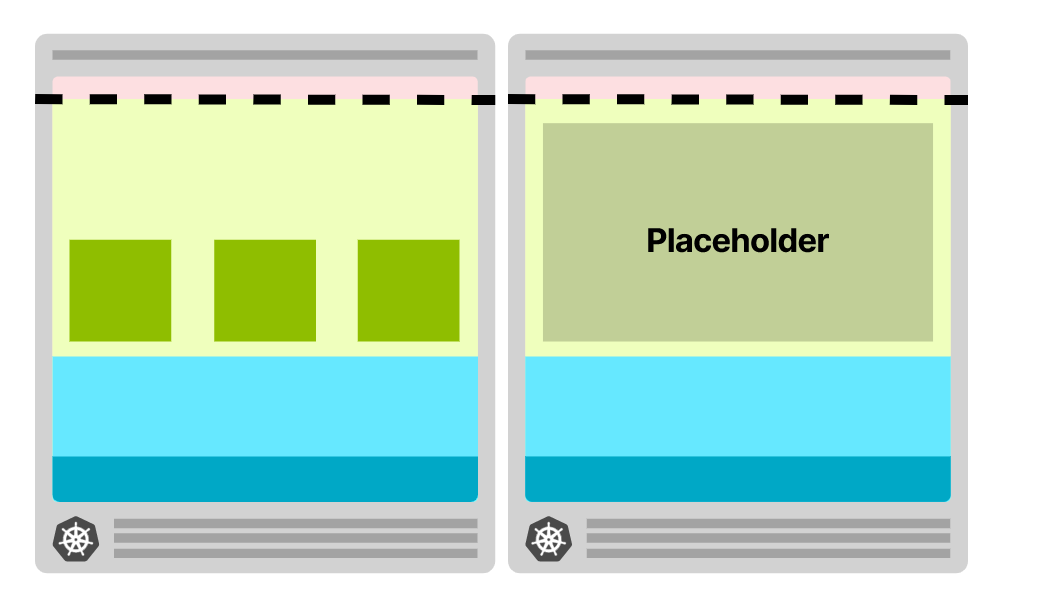
一旦有了真正的 Pod,驱逐占位的 Pod。
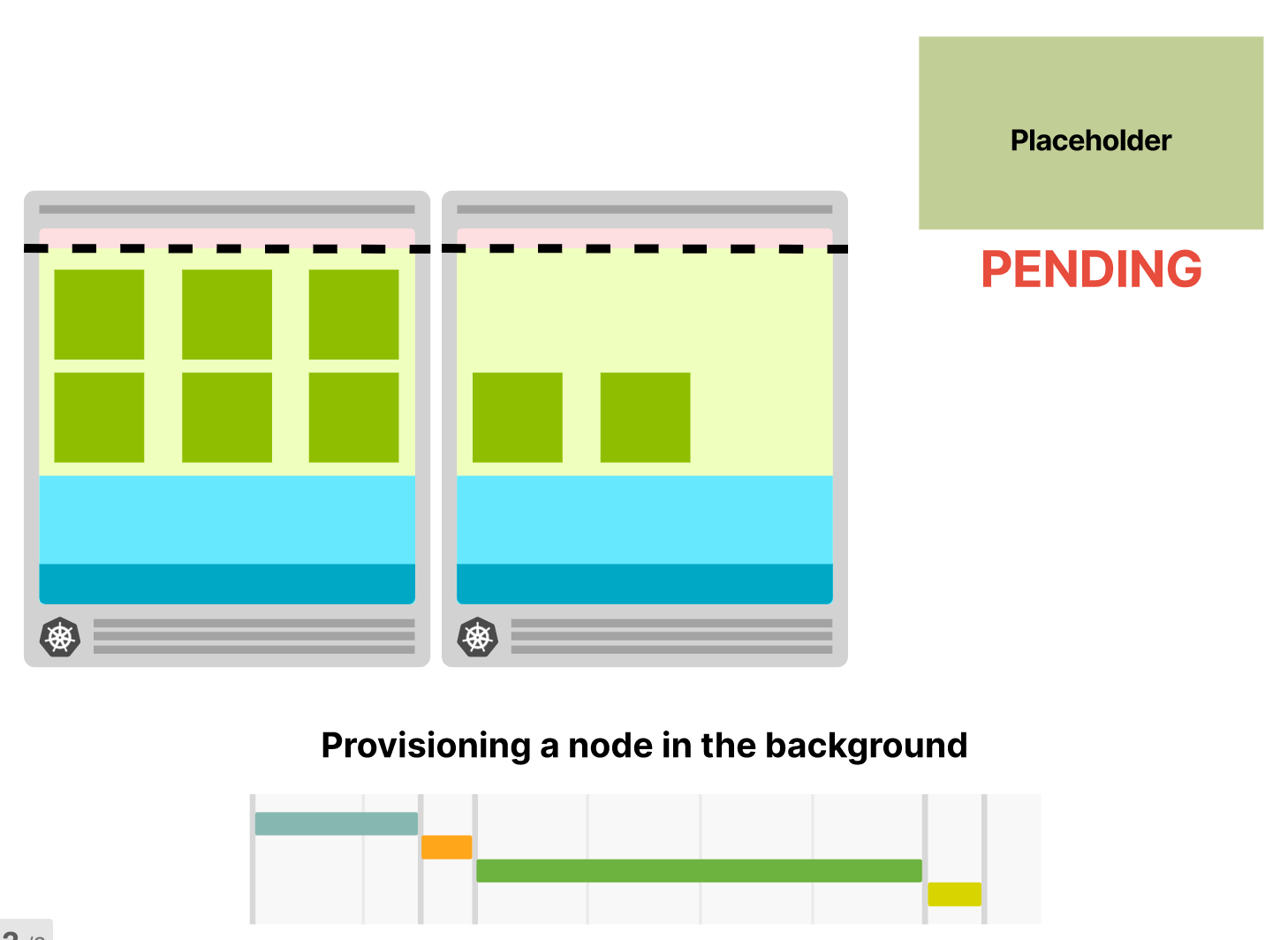
待后台完成新的节点配置后,将“占位” Pod 再次占用整个节点。
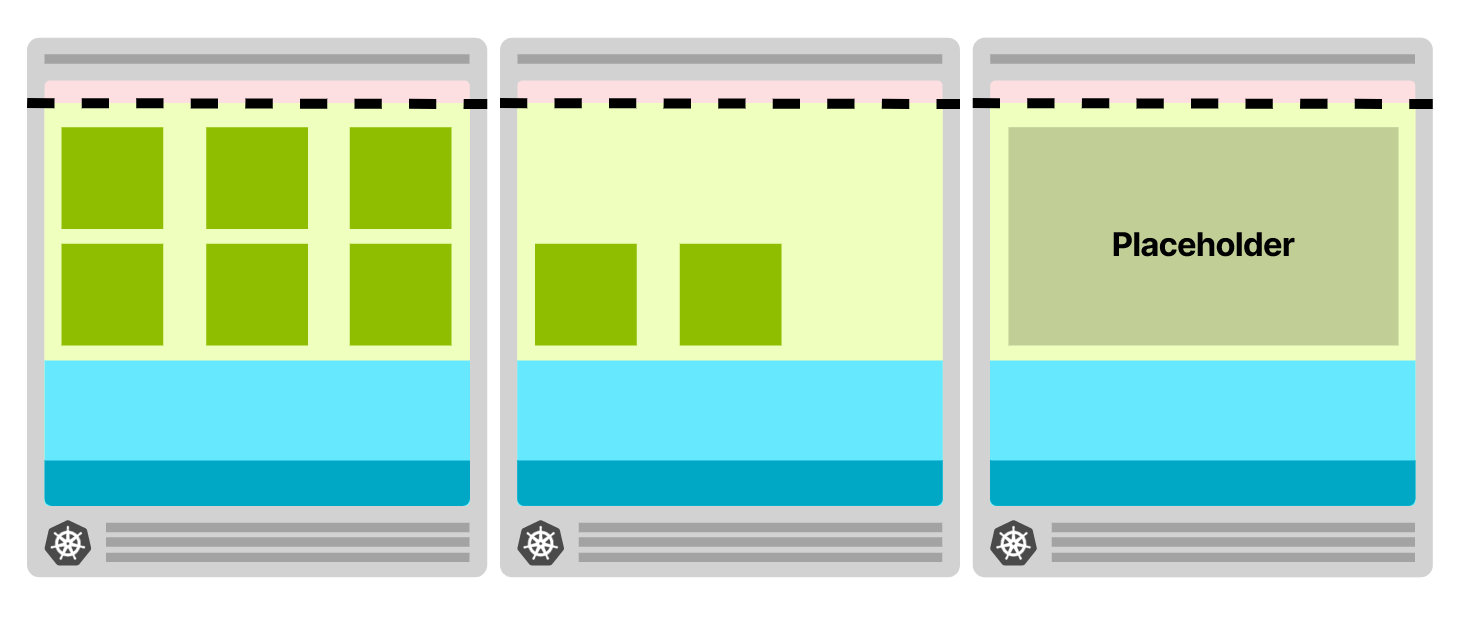
这个“占位”的 Pod 可以通过永久休眠来实现空间的保留。
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: '1739m'
memory: '5.9G'
使用优先级和抢占,来实现创建真正的 Pod 后驱逐“占位”的 Pod。
使用 PodPriorityClass 在配置 Pod 优先级:
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1 #默认的是 0,这个表示比默认的低
globalDefault: false
description: 'Priority class used by overprovisioning.'
为“占位” Pod 配置优先级:
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning #HERE
containers:
- name: reserve-resources
image: k8s.gcr.io/pause
resources:
requests:
cpu: '1739m'
memory: '5.9G'
已经做完过度配置,应用程序是否需要优化?
为 Pod 选择正确的内存和 CPU 请求
Kubernetes 是根据 Pod 的内存和 CPU 请求,为其分配节点。
如果 Pod 的资源请求配置不正确,可能会过晚(或过早)触发自动缩放器。
这样一个场景:
- 应用程序平均负载下消耗 512MB 内存和 0.25 个 vCPU。
- 高峰时,消耗 4GB 内存 和 1 个 vCPU。(即资源限制,Limit)
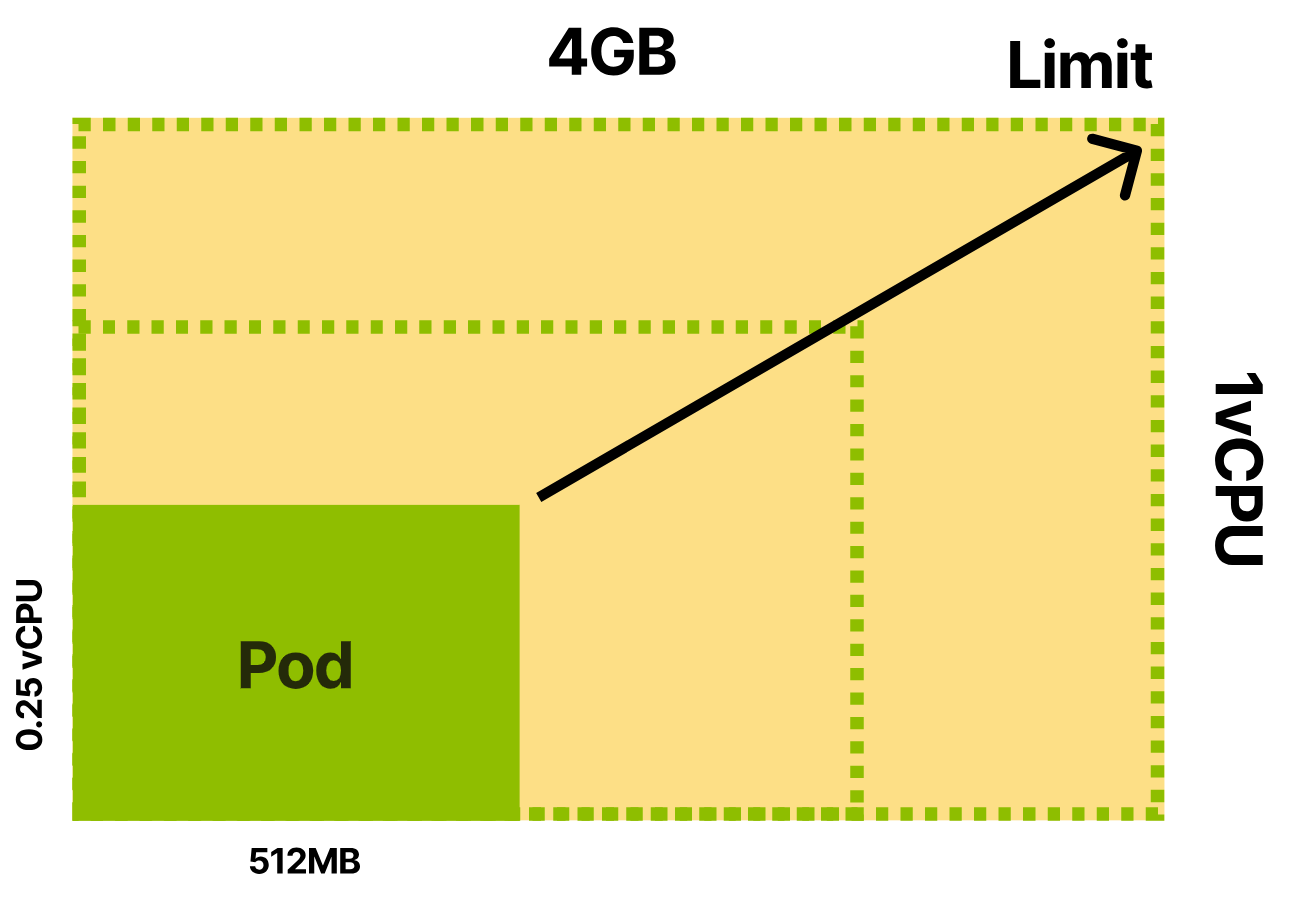
有三种请求的配置选择:
- 远低于平均使用量
- 匹配平均使用量
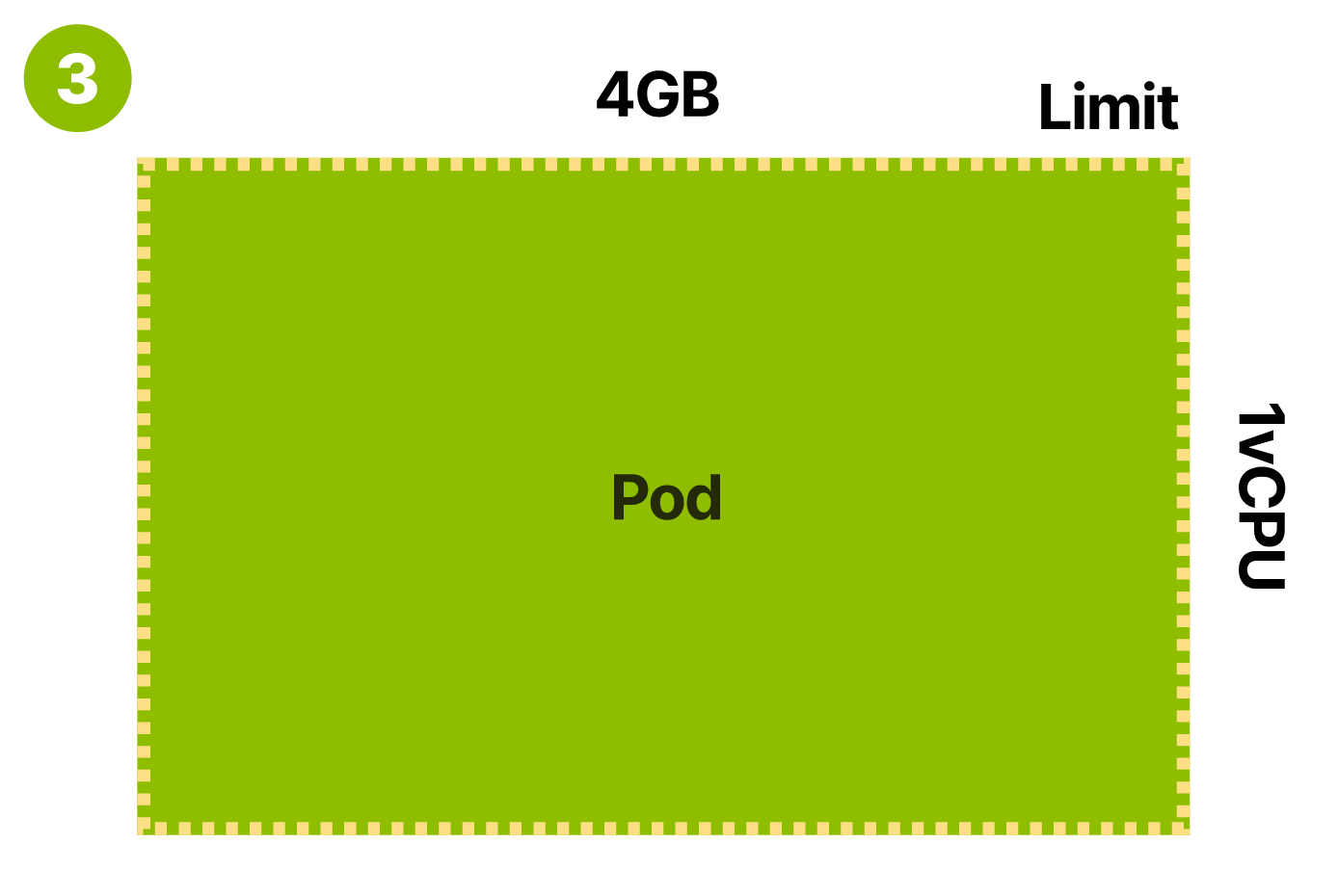
- 尽量接近限制
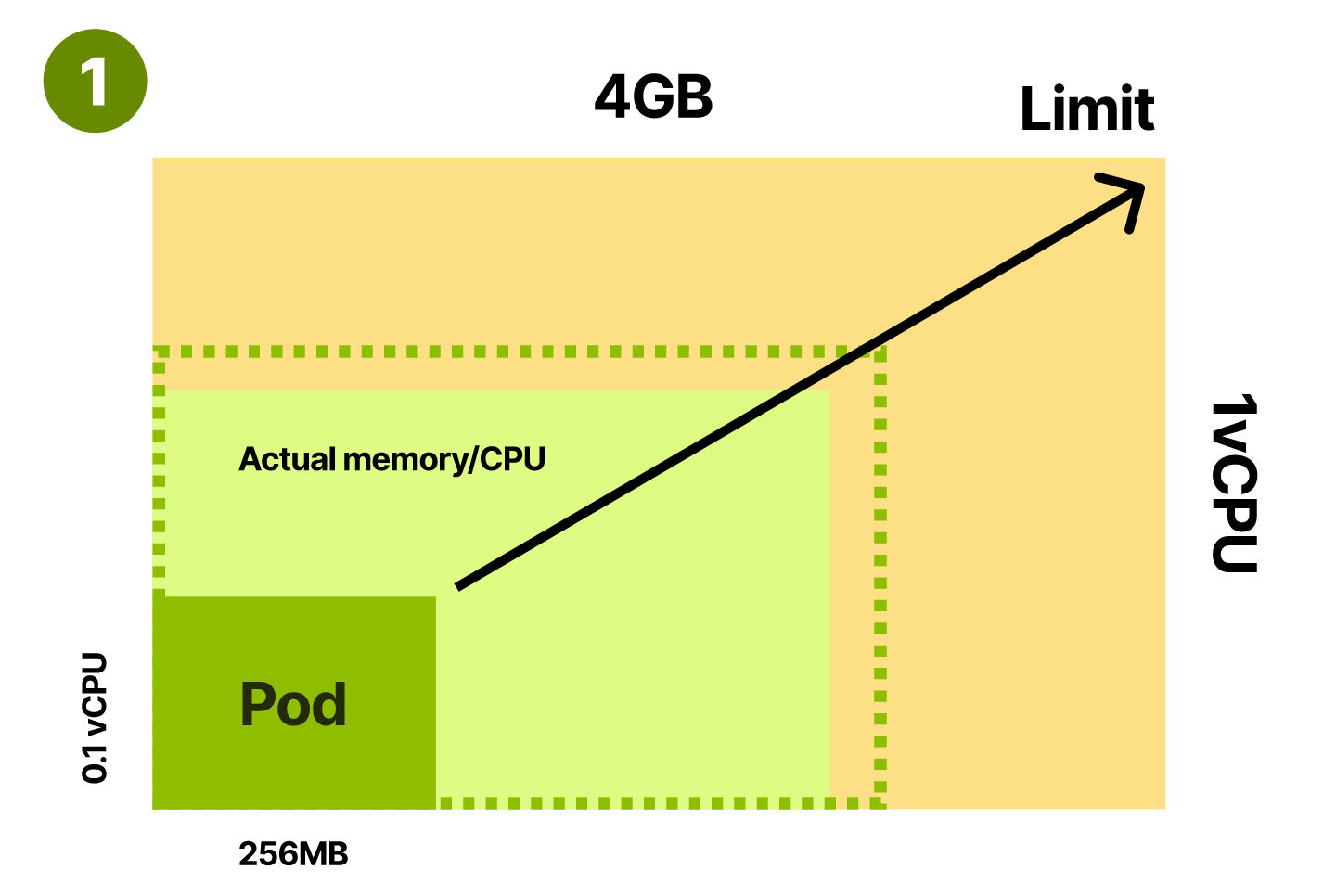
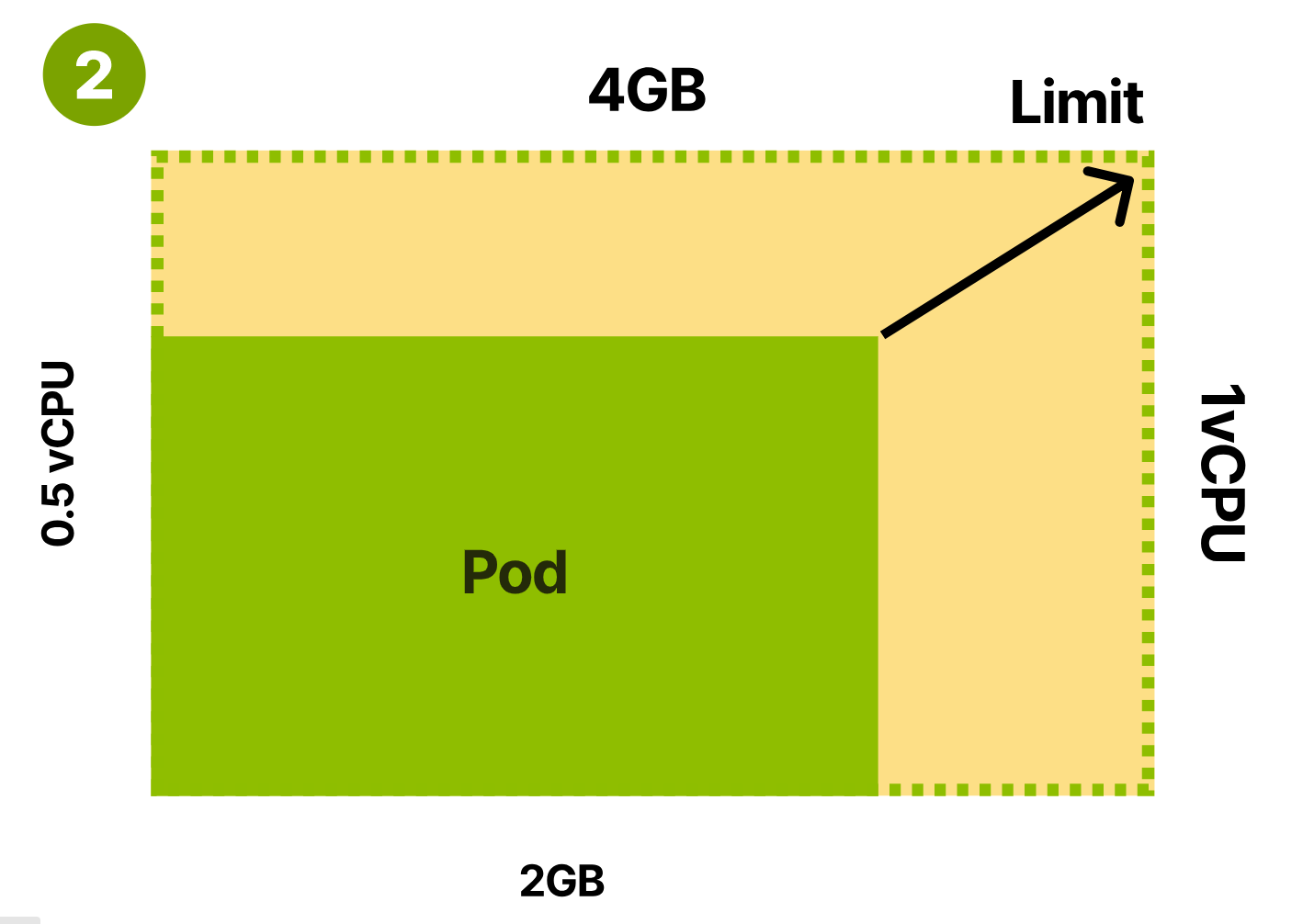
第一种的问题在于超卖严重,过度使用节点。kubelet 负载高,稳定性差。
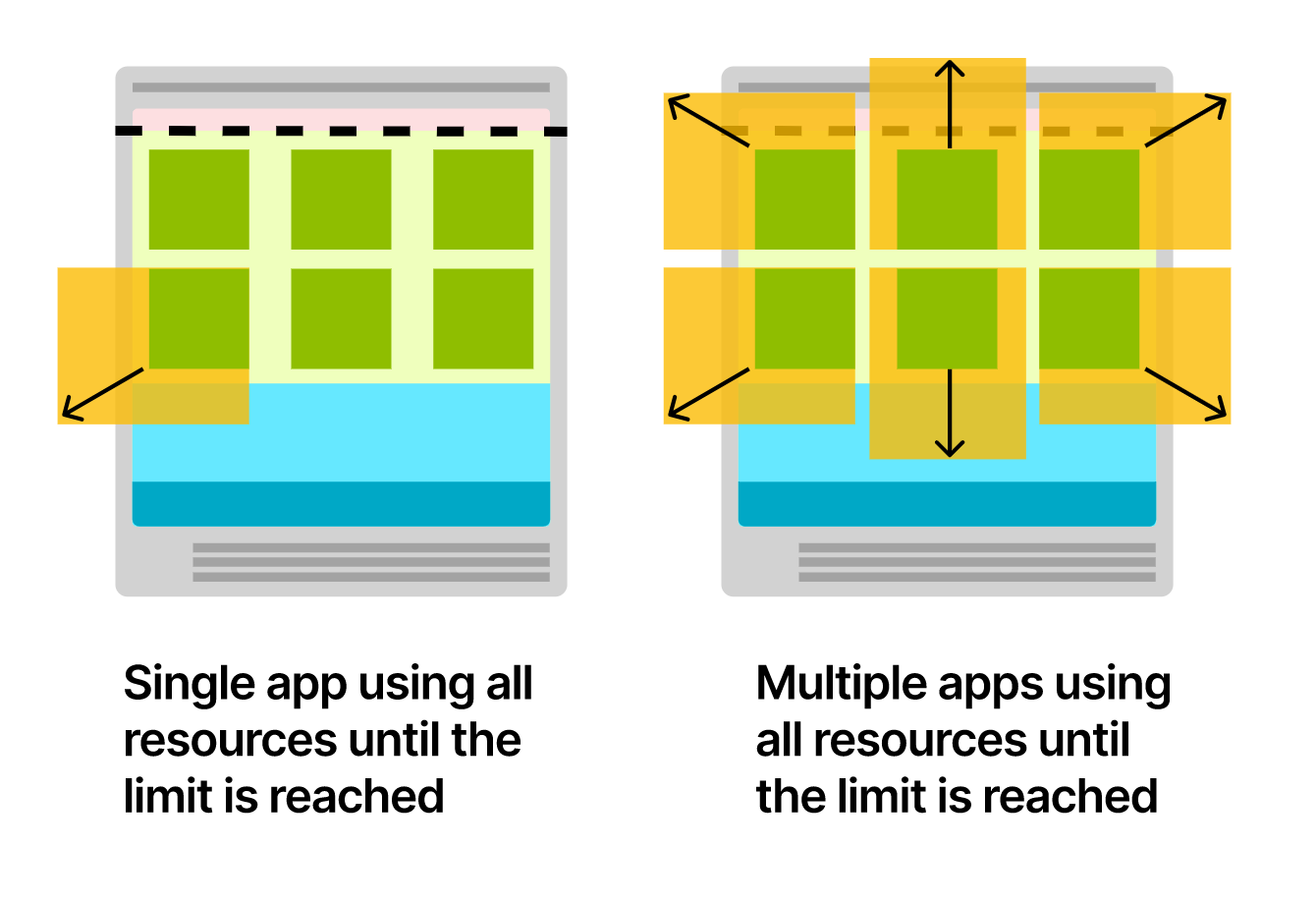
第三种,会造成资源的利用率低,浪费资源。这种通常被称为 QoS:Quality of Service class 中的 Guaranteed 级别,Pod 不会被终止和驱逐。
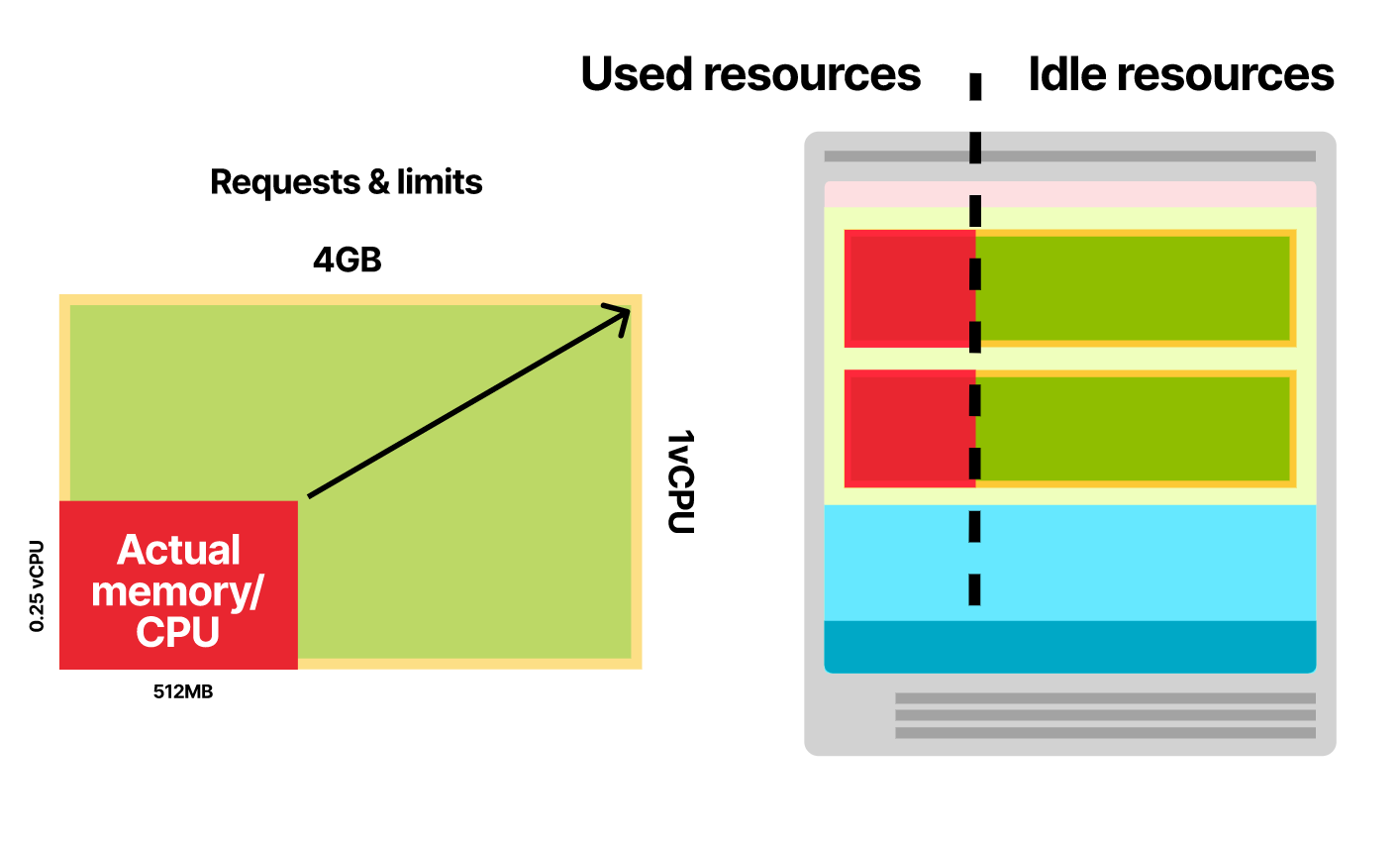
如何在稳定性和资源使用率间做权衡?
这就是 QoS:Quality of Service class 中的 Burstable 级别,即 Pod 偶尔会使用更多的内存和 CPU。
- 如果节点中有可用资源,应用程序会在返回基线(baseline)前使用这些资源。
- 如果资源不足,Pod 将竞争资源(CPU),kubelet 也有可能尝试驱逐 Pod(内存)。
在 Guaranteed 和 Burstable 之前如何做选择?取决于:
- 想尽量减少 Pod 的重新调度和驱逐,应该是用
Guaranteed。 - 如果想充分利用资源时,使用
Burstable。比如弹性较大的服务,Web 或者 REST 服务。
如何做出正确的配置?
应该分析应用程序,并测算空闲、负载和峰值时的内存和 CPU 消耗。
甚至可以通过部署 VPA 来自动调整。
如何进行集群缩容?
每 10 秒,当请求(request)利用率低于 50%时,CA 才会决定删除节点。
CA 会汇总同一个节点上的所有 Pod 的 CPU 和内存请求。小于节点容量的一半,就会考虑对当前节点进行缩减。
需要注意的是,CA 不考虑实际的 CPU 和内存使用或者限制(limit),只看请求(request)。
移除节点之前,CA 会:
检查都通过之后,才会删除节点。
为什么不根据内存或 CPU 进行自动缩放?
基于内存和 CPU 的自动缩放器,不关心 pod。
比如配置缩放器在节点的 CPU 达到总量的 80%,就自动增加节点。
当你创建 3 个副本的 Deployment,3 个节点的 CPU 达到了 85%。这时会创建一个节点,但你并不需要第 4 个副本,新的节点就空闲了。
不建议使用这种类型的自动缩放器。
总结
定义和实施成功的扩展策略,需要掌握以下几点:
- 节点的可分配资源。
- 微调 Metrics Server、HPA 和 CA 的刷新间隔。
- 设计集群和节点的规格。
- 缓存容器镜像到节点。
- 应用程序的基准测试和分析。
配合适当的监控工具,可以反复测试扩展策略并调整集群的缩放速度和成本。

