
Karmada:混合多云下的应用管理
背景
过去几年,公有云凭借着更高扩展性、灵活性、可靠性和安全性,吸引了大量的企业将应用程序部署到公有云上。随着业务规模的不断扩张,企业出于某些原因,如避免厂商锁定、追求更低的延迟、更高的可靠性等,选择将应用部署在更多的公有云上;也有些企业出于数据敏感性等原因,选择将部分应用部署有私有环境中。后者也更像是将上云的过程拉长。不管是多云还是混合云,基础设施都不可避免的存在着差异,企业不得不在适配底层设施上投入了大量的人力物力。
Kubernetes 的出现,完美地解决了这一问题。除了屏蔽基础设施层的差异解决了跨平台的问题,还提供自动化的容器编排、更高的扩展性、弹性和高可用性,其背后更是有着庞大的社区的支持。Kubernetes 的风靡,得到了大量企业的青睐。随着时间的推移,企业使用多个 Kubernetes 集群管理应用的情况越来越普遍。
如何在跨越多个集群、甚至是混合多云的环境下来管理应用成了新的难题。Karmada 的出现正是要解决这一问题。
Karmada
Karmada 是 CNCF(Cloud Native Computing Foundation)下面的一个开源项目,旨在为 Kubernetes 集群提供一个平台来简化跨多个 Kubernetes 集群的应用程序部署和管理,并提高可用性和可扩展性。
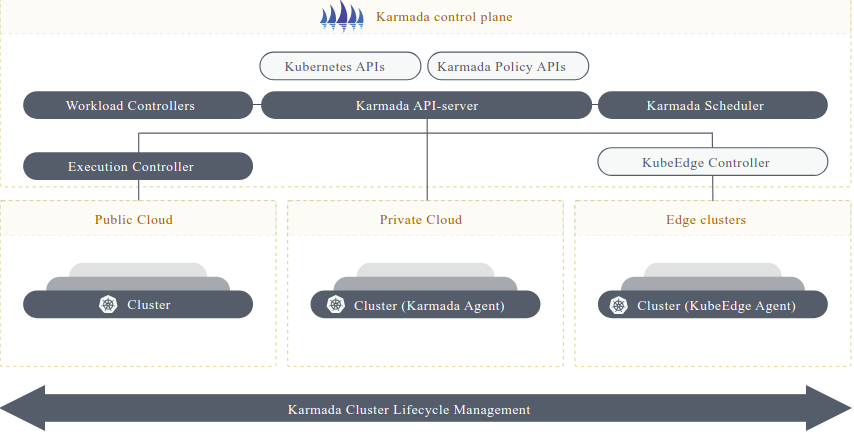
借用一下官网的架构图。从图中可以看到 Karmada 提供了一个集中式控制平面,负责资源和策略的管理,以及资源的调度;数据平面则是其管理的集群,真正运行资源的集群。
控制平面的组件与 Kubernetes 的组件类似,也都是负责资源的调度。不同的是,Kubernetes 的控制平面负责将资源调度到计算节点,而 Karmada 的控制平面是将资源调度到某个集群。
拿 Deployment 的部署来说,在 Kubernetes 集群中,控制平面根据当前节点的资源情况选择某个或某些节点来运行 pod。在 Karmada 多集群下,创建了 Deployment 资源后,Karmada 控制平面根据策略将其调度到目标的集群:在目标集群中创建 Deployment 资源,所有集群中的副本数之和,就是期望的副本数。
下面通过示例来进行说明。
环境搭建
前置条件
- Docker
- k3d
- kubectl
- karmadactl
- 1 台虚拟机(最低配置不低于 4c8g)
我们选择使用 k3d 在容器中创建 4 个 k3s 集群(控制平面集群 control-plane 和成员 cluster-1、cluster-2、cluster-3),这些集群通过本机 IP 地址和独立的端口进行通信。
创建多个集群
创建集群前通过下面的命令获取本地 IP,保存在变量中。
HOST_IP=$(if [ "$(uname)" == "Darwin" ]; then ipconfig getifaddr en0; else ip -o route get to 8.8.8.8 | sed -n 's/.*src \([0-9.]\+\).*/\1/p'; fi)
使用 k3d 的命令创建集群,集群 apiserver 的端口分别为 6444、6445、6446、6447.
API_PORT=6444 #6444 6445 6446 6447
for CLUSTER_NAME in control-plane cluster-1 cluster-2 cluster-3
do
k3d cluster create ${CLUSTER_NAME} \
--image docker.io/rancher/k3s:v1.23.8-k3s2 \
--api-port "${HOST_IP}:${API_PORT}" \
--servers-memory 2g \
--k3s-arg "--disable=traefik@server:0" \
--network multi-clusters \
--timeout 120s \
--wait
((API_PORT=API_PORT+1))
done
创建完集群,为了便于集群的访问,设置如下变量来访问对应的集群。
k3d kubeconfig get control-plane > /tmp/cp.kubeconfig
k3d kubeconfig get cluster-1 > /tmp/c1.kubeconfig
k3d kubeconfig get cluster-2 > /tmp/c2.kubeconfig
k3d kubeconfig get cluster-3 > /tmp/c3.kubeconfig
#使用
k0="kubectl --kubeconfig /tmp/cp.kubeconfig"
k1="kubectl --kubeconfig /tmp/c1.kubeconfig"
k2="kubectl --kubeconfig /tmp/c2.kubeconfig"
k3="kubectl --kubeconfig /tmp/c3.kubeconfig"
安装 Karmada
在控制平面集群上安装 Karmada 进行初始化。
sudo karmadactl --kubeconfig /tmp/cp.kubeconfig init
完成初始化后,同样设置变量 kmd 来方便访问 Karmada 的控制平面,指定使用 Karmada apiserver 的配置文件(该配置文件是在初始化时自动生成的,所以上面的命令用)。
kmd="kubectl --kubeconfig /etc/karmada/karmada-apiserver.config"
加入集群
接下来将其他三个集群加入到联邦中(k3d 自动在集群名前加上了前缀 k3d-)。
karmadactl --kubeconfig /etc/karmada/karmada-apiserver.config join k3d-cluster-1 --cluster-kubeconfig=/tmp/c1.kubeconfig
karmadactl --kubeconfig /etc/karmada/karmada-apiserver.config join k3d-cluster-2 --cluster-kubeconfig=/tmp/c2.kubeconfig
karmadactl --kubeconfig /etc/karmada/karmada-apiserver.config join k3d-cluster-3 --cluster-kubeconfig=/tmp/c3.kubeconfig
返回下面的信息说明集群加入成功。
cluster(k3d-cluster-1) is joined successfully
cluster(k3d-cluster-2) is joined successfully
cluster(k3d-cluster-3) is joined successfully
访问 Karmada 的控制平面查看集群列表。
$kmd get cluster -o wide
NAME VERSION MODE READY AGE APIENDPOINT
k3d-cluster-1 v1.23.8+k3s2 Push True 24m https://10.0.0.8:6445
k3d-cluster-2 v1.23.8+k3s2 Push True 24m https://10.0.0.8:6446
k3d-cluster-3 v1.23.8+k3s2 Push True 23m https://10.0.0.8:6447
至此多集群环境已经搭建完成。
测试
这里选择两种应用:服务端应用响应 HTTP 请求,返回当前 pod 的名字;客户端应用,可以用来发起 HTTP 请求。
部署服务端应用
通过 Karmada 的控制平面创建 2 个副本的 Deployment 和 Service。
$kmd apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: pipy
name: pipy
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: pipy
strategy: {}
template:
metadata:
labels:
app: pipy
spec:
containers:
- image: flomesh/pipy
name: pipy
command: ["pipy"]
args: ["-e", "pipy().listen(8080).serveHTTP(() => new Message(os.env['HOSTNAME'] +'\n'))"]
---
apiVersion: v1
kind: Service
metadata:
labels:
app: pipy
name: pipy
spec:
ports:
- port: 8080
protocol: TCP
targetPort: 8080
selector:
app: pipy
EOF
然后查看 Deployment 的信息,并没有任何副本运行。
$kmd get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
pipy 0/2 0 0 20s
通过 describe 命令发现如下警告,提示没有匹配资源的策略。Karmada 需要根据资源的多集群调度策略 PropagationPolicy 将其调度到目标集群。
Warning ApplyPolicyFailed 47s resource-detector No policy match for resource
Propagation 策略
应用下面的策略将 Deployment 和 Service 资源调度到三个成员集群。
$kmd apply -f - <<EOF
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: pipy-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: pipy
- apiVersion: v1
kind: Service
name: pipy
placement:
clusterAffinity:
clusterNames:
- k3d-cluster-1
- k3d-cluster-2
- k3d-cluster-3
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- k3d-cluster-1
weight: 10
- targetCluster:
clusterNames:
- k3d-cluster-2
weight: 10
- targetCluster:
clusterNames:
- k3d-cluster-3
weight: 10
EOF
在集群 cluster-1 和 cluster-2 中可以看到有 pod 在运行。
$k1 get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
pipy 1/1 1 1 13s
$k2 get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
pipy 1/1 1 1 13s
而 cluster-3 上只找到了 deployment,但期望副本数为 0。这是因为在控制平面中创建的 deployment 只设置了两个副本。
$k3 get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
pipy 0/0 0 0 16s
在控制平面中将副本数调整为 3。
$kmd scale deploy pipy --replicas 3
然后在 cluster-3 就可以看到第三个副本。
$k3 get po
NAME READY STATUS RESTARTS AGE
pipy-8ff5f5987-5nqqw 1/1 Running 0 54s
部署客户端应用
接下来部署客户端应用。
$kmd apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: curl
name: curl
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: curl
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: curl
spec:
containers:
- image: curlimages/curl
name: curl
command: ["sleep", "365d"]
EOF
同样配置多集群调度策略,只调度到集群 cluster-3。
$kmd apply -f - <<EOF
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: curl-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: curl
placement:
clusterAffinity:
clusterNames:
- k3d-cluster-3
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- k3d-cluster-3
weight: 1
EOF
从该 pod 中发起请求访问应用的 8080 端口,成功收到响应。多次请求,都会获得同样的结果。
curl_client=`$k3 get po -l app=curl -o jsonpath='{.items[0].metadata.name}'`
$k3 exec $curl_client -- curl -s http://pipy.default:8080
pipy-8ff5f5987-5nqqw
总结
Karmada 的出现在不改变部署方式的情况下解决了多集群中应用的管理难题,实现了应用在多 Kubernetes 集群中的部署、同步和调度。文中没有展示的还有可观察性,Karmada 控制平面可以汇总成员集群中的监控数据并集中展示。
思考
可能你也发现了,在演示中客户端收到的响应都是来自同集群中的应用。
此时假如将 deployment 的副本数缩减到 2,并再次请求。你会发现请求失败,请求没有被调度到其他集群。
可见,虽然应用的跨集群管理由 Karmada 帮我们完成了,但是流量仍无法跨集群。这说明什么?当你的应用在做多集群部署时,由于应用间彼此依赖需要做近乎全量的部署,那影响和成本可想而知。
在下一篇,我将带大家来尝试来解决这个问题。



