
可编程网关 Pipy 第三弹:事件模型设计
自从参加了 Flomesh 的 workshop,了解了可编程网关 Pipy。对这个“小东西”充满了好奇,前后写了两篇文章,看了部分源码解开了其部分面纱。但始终未见其全貌,没有触及其核心设计。
不是有句话,“好奇害死猫”。其实应该还有后半句,“满足了就没事”(见维基百科)。
所有就有了今天的这一篇,对前两篇感兴趣的可以跳转翻看。
言归正传。
事件模型
上篇写了 Pipy 基于事件的信息流转,其实还未深入触及其核心的事件模型。既然是事件模型,先看事件。
src/event.hpp:41 中定义了 Pipy 的四种事件:
DataMessageStartMessageEndSessionEnd
翻看源码可知(必须吐槽文档太少)这几种事件其实是有顺序的:MessageStart -> Data -> MessageEnd -> SessionEnd。
这种面向事件模型,必然有生产者和消费者。又是翻看源码可知,生产者和消费者都是 pipy::Filter。我们在上篇文章中讲过:每个 Pipeline 都有一个过滤器链,类似单向链表的数据结构。
那是不是按照上面说的,事件是从一个 Filter 流向下一个 Filter?也对,也不对。
矛盾?
先看 Filter 如何向下传递事件,src/session.cpp:55 处,Filter 持有 output 变量,类似为 Event::Receiver(参数为 Event 的 std::function 的别名,作为外行的笔者并不懂 c++,但不妨碍了解程序设计)。通过 Receiver 调用下一个 Filter 的 #process 方法。
这里的 Receiver 就可以理解为事件发送的窗口,而 #process(Context *ctx, Event *inp) 就是事件的接收窗口。
这就是前面为什么说 “事件是从一个 Filter 流向下一个 Filter” 是正确的。
为什么不对?首先,一个 Filter 会产生多个事件,比如 decodeHttpRequest 可能会产生 MessageStart、Data 和 MessageEnd 事件,并且每产生一个事件都会通过Receiver 向下传递,不会等 #process 流程结束才传递事件;再就是下一个 Filter 可能并不会对某个事件感兴趣(下一个 Filter 的 #process 方法不做任何处理就返回了)。
可能看下图会更容易理解(图中 no output 表明事件不会向下传递):
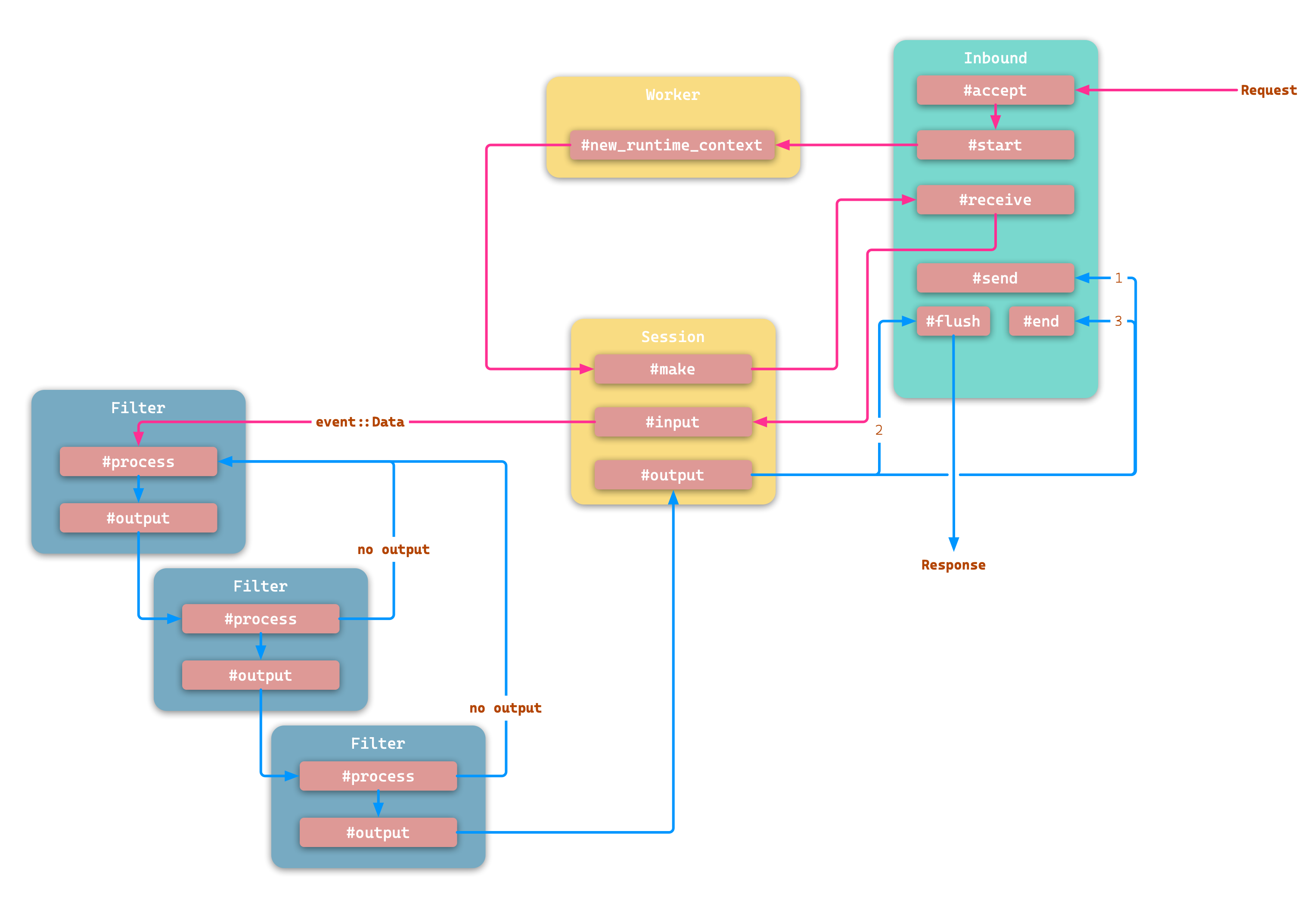
最简单的示例
在 test/001-echo/pipy.js 提供了的示例:
pipy()
.listen(6080)
.decodeHttpRequest()
.encodeHttpResponse()
发起请求
$ curl -X POST localhost:6080 -d '{}'
{}
HTTP 消息体
#request
POST / HTTP/1.1
Content-Type: application/javascript
User-Agent: PostmanRuntime/7.28.1
Accept: */*
Postman-Token: fc84b575-7fea-487b-a55d-f6085bc62cf7
Host: localhost:6080
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Content-Length: 2
{}
#response
HTTP/1.1 200 OK
postman-token: fc84b575-7fea-487b-a55d-f6085bc62cf7
accept-encoding: gzip, deflate, br
host: localhost:6080
accept: */*
user-agent: PostmanRuntime/7.28.1
content-type: application/javascript
Connection: keep-alive
Content-Length: 2
{}
这里我们以过滤器 decodeHttpRequest 为例,官方的说明是 Deframes an HTTP request message。前面提到它会产生 3 个事件,都是在 deframe 的过程中发出的。

Session 调用第一个 Filter 时,传入的事件类型是 event::Data。decodeHttpRequest 关注该事件,并按照 HTTP 协议开始解析。
在上图可以看到解析的不同阶段,会发出不同的事件。调用 Receiver 传输事件,调用 encodeHttpResponse 的 #process() 方法。
这里又会好奇,假如上面的示例中去掉两个过滤器中的任何一个,或者都去掉,能不能正常工作?
答案是都不能!响应状态码都是 502 Bad Gateway(curl/httpie)。
分析
这里需要结合本文的第一张图 event-handling-flow。
去掉两个过滤器
假如两个都去掉了,HTTP Request 请求消息会被直接回传给客户端,协议错误。
去掉 decodeHttpRequest
前面提到 Session 传给第一个 Filter 的事件是 event::Data。而 encodeHttpResponse 针对该事件只会将其保存到 buffer 中。
然后整个链路在此结束,没有回传任何数据。客户端会等待响应,超时退出(curl)。

去掉 encodeHttpResponse
先说结果,与前面一样超时退出。
为什么会这样,明明 decodeHttpRequest 产生了 3 个时间,Session 里的 Receiver 也有收到,也确实写回了请求 body 里的 {}。
encodeHttpResponse 过滤器有写回响应头,缺少了这些信息,响应就不并不是合法的 HTTP 协议,只是普通的 TCP 协议。
总结
Pipy 基于事件模型的设计,提供了强大的灵活性。允许我们在“规则”中使用不同过滤器针对不同的事件,对请求和响应的信息进行处理。
“规则” 就是业务逻辑的核心,而 Pipy 就是这逻辑的执行引擎。
最后,“好奇心是成长的驱动力,永远保持好奇心。”



