Zipkin dependencies的坑之一: 耗时越来越长
zipkin-dependencies是zipkin调用链的依赖分析工具.
系统上线时使用了当时的最新版本2.0.1, 运行一年之后随着服务的增多, 分析一天的数据耗时越来越多. 从最初的几分钟, 到最慢的几十小时(数据量18m).
最终返现是版本的问题, 升级到>=2.3.0的版本之后吞吐迅速上升.
所以便有了issue: Reminder: do NOT use the version before 2.3.0
但这也引来了另一个坑: 心跳超时和Executor OOM
TL;DR
简单浏览了下zipkin-dependencies的源码, 2.0.1和2.3.2的比较大的差距是依赖的elasticsearch-spark的版本. 前者用的是6.3.2, 后者是7.3.0.
尝试在zipkin-dependencies-2.0.1中使用elasticsearch-spark-7.3.0, 和2.3.2的性能一直.
通过打开log4j debug日志, 发现到elasticsearch-spark两个版本的运行差异:
#7.3.0
19/09/05 18:13:14 INFO DAGScheduler: Submitting 3 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[1] at groupBy at ElasticsearchDependenciesJob.java:185) (first 15 tasks are for partitions Vector(0, 1, 2))
#6.3.2
19/09/05 18:09:56 INFO DAGScheduler: Submitting 214 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[1] at groupBy at ElasticsearchDependenciesJob.java:185) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14))
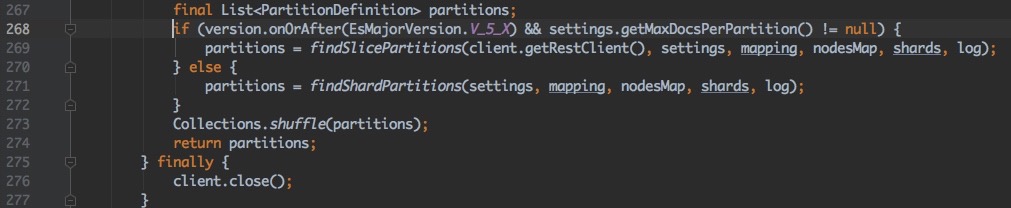
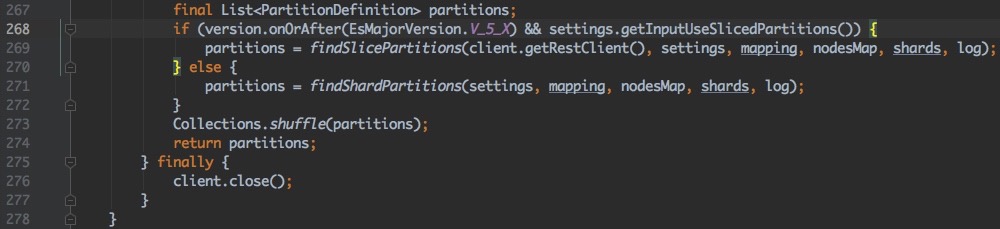
RestService#findPartitions()L268的源码:
7.3.0
6.3.2
7.x es.input.max.docs.per.partition为null 计算出partitions=3 (实际分区数为3, 使用方法#findShardPartitions())
6.x es.input.use.sliced.partitions为true, 计算出partitions=214 (使用方法#findSlicePartitions())
在7.x中, 可以通过设置es.input.max.docs.per.partition的值来设置切片数量(对单个partition进行切分, 通过增加并行任务数量来提高吞吐)
**该行代码的commit message: **
Remove default setting for max documents per partition We added support for sliced scrolls back in 5.0, which allows subdividing scrolls into smaller input splits. there are some cases where the added subdivision of the scroll operations causes high amounts of overhead when reading very large shards. in most cases, shards should be small enough that a regular read operation over them should complete in reasonable time. In order to avoid performance degradation at higher levels, we are removing the default value of 100k from this setting, and instead, checking if it is set. Additionally, the ’es.input.use.sliced.partitions’ setting has been removed as it is now redundant.
