
深入探索 Kubernetes 网络模型和网络通信
这是 Kubernetes 网络学习的第一篇笔记。
- 深入探索 Kubernetes 网络模型和网络通信(本篇)
- 认识一下容器网络接口 CNI
- 源码分析:从 kubelet、容器运行时看 CNI 的使用
- 从 Flannel 学习 Kubernetes VXLAN 网络
- Kubernetes 网络学习之 Cilium 与 eBPF
Kubernetes 定义了一种简单、一致的网络模型,基于扁平网络结构的设计,无需将主机端口与网络端口进行映射便可以进行高效地通讯,也无需其他组件进行转发。该模型也使应用程序很容易从虚拟机或者主机物理机迁移到 Kubernetes 管理的 pod 中。
这篇文章主要深入探索 Kubernetes 网络模型,并了解容器、pod 间如何进行通讯。对于网络模型的实现将会在后面的文章介绍。
Kubernetes 网络模型
该模型定义了:
- 每个 pod 都有自己的 IP 地址,这个 IP 在集群范围内可达
- Pod 中的所有容器共享 pod IP 地址(包括 MAC 地址),并且容器之前可以相互通信(使用
localhost) - Pod 可以使用 pod IP 地址与集群中任一节点上的其他 pod 通信,无需 NAT
- Kubernetes 的组件之间可以相互通信,也可以与 pod 通信
- 网络隔离可以通过网络策略实现
上面的定义中提到了几个相关的组件:
- Pod:Kubernetes 中的 pod 有点类似虚拟机有唯一的 IP 地址,同一个节点上的 pod 共享网络和存储。
- Container:pod 是一组容器的集合,这些容器共享同一个网络命名空间。pod 内的容器就像虚拟机上的进程,进程之间可以使用
localhost进行通信;容器有自己独立的文件系统、CPU、内存和进程空间。需要通过创建 Pod 来创建容器。 - Node:pod 运行在节点上,集群中包含一个或多个节点。每个 pod 的网络命名空间都会连接到节点的命名空间上,以打通网络。
讲了这么多次网络命名空间,那它到底是如何运作的呢?
网络命名空间如何工作
在 Kubernetes 的发行版 k3s 创建一个 pod,这个 pod 有两个容器:发送请求的 curl 容器和提供 web 服务的 httpbin 容器。
虽然使用发行版,但是其仍然使用 Kubernetes 网络模型,并不妨碍我们了解网络模型。
apiVersion: v1
kind: Pod
metadata:
name: multi-container-pod
spec:
containers:
- image: curlimages/curl
name: curl
command: ["sleep", "365d"]
- image: kennethreitz/httpbin
name: httpbin
登录到节点上,通过 lsns -t net 当前主机上的网络命名空间,但是并没有找到 httpbin 的进程。有个命名空间的命令是 /pause,这个 pause 进程实际上是每个 pod 中 不可见 的 sandbox 容器进程。关于 sanbox 容器的作用,将会在下一篇容器网络和 CNI 中介绍。
lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531992 net 126 1 root unassigned /lib/systemd/systemd --system --deserialize 31
4026532247 net 1 83224 uuidd unassigned /usr/sbin/uuidd --socket-activation
4026532317 net 4 129820 65535 0 /run/netns/cni-607c5530-b6d8-ba57-420e-a467d7b10c56 /pause
既然每个容器都有独立的进程空间,我们换下命令查看进程类型的空间:
lsns -t pid
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 127 1 root /lib/systemd/systemd --system --deserialize 31
4026532387 pid 1 129820 65535 /pause
4026532389 pid 1 129855 systemd-network sleep 365d
4026532391 pid 2 129889 root /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
通过进程 PID 129889 可以找到其所属的命名空间:
ip netns identify 129889
cni-607c5530-b6d8-ba57-420e-a467d7b10c56
然后可以在该命名空间下使用 exec 执行命令:
ip netns exec cni-607c5530-b6d8-ba57-420e-a467d7b10c56 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if17: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether f2:c8:17:b6:5f:e5 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.42.1.14/24 brd 10.42.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::f0c8:17ff:feb6:5fe5/64 scope link
valid_lft forever preferred_lft forever
从结果来看 pod 的 IP 地址 10.42.1.14 绑定在接口 eth0 上,而 eth0 被连接到 17 号接口上。
在节点主机上,查看 17 号接口信息。veth7912056b 是主机根命名空间下的虚拟以太接口(vitual ethernet device),是连接 pod 网络和节点网络的 隧道,对端是 pod 命名空间下的接口 eth0。
ip link | grep -A1 ^17
17: veth7912056b@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
link/ether d6:5e:54:7f:df:af brd ff:ff:ff:ff:ff:ff link-netns cni-607c5530-b6d8-ba57-420e-a467d7b10c56
上面的结果看到,该 veth 连到了个网桥(network bridge)cni0 上。
网桥工作在数据链路层(OSI 模型的第 2 层),连接多个网络(可多个网段)。当请求到达网桥,网桥会询问所有连接的接口(这里 pod 通过 veth 以网桥连接)是否拥有原始请求中的 IP 地址。如果有接口响应,网桥会将匹配信息(IP -> veth)记录,并将数据转发过去。
那如果没有接口响应怎么办?具体流程就要看各个网络插件的实现了。我准备在后面的文章中介绍常用的网络插件,比如 Calico、Flannel、Cilium 等。
接下来看下 Kubernetes 中的网络通信如何完成,一共有几种类型:
- 同 pod 内容器间通信
- 同节点上的 pod 间通信
- 不同节点上的 pod 间通信
Kubernetes 网络如何工作
同 pod 内的容器间通信
同 pod 内的容器间通信最简单,这些容器共享网络命名空间,每个命名空间下都有 lo 回环接口,可以通过 localhost 来完成通信。
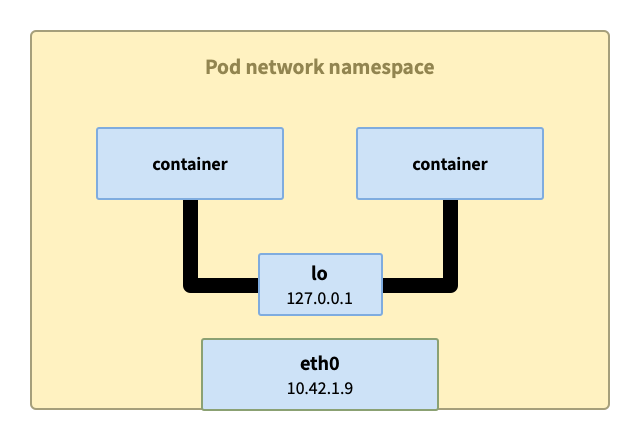
同节点上的 pod 间通信
当我们将 curl 容器和 httpbin 分别在两个 pod 中运行,这两个 pod 有可能调度到同一个节点上。curl 发出的请求根据容器内的路由表到达了 pod 内的 eth0 接口。然后通过与 eth0 相连的隧道 veth1 到达节点的根网络空间。
veth1 通过网桥 cni0 与其他 pod 相连虚拟以太接口 vethX 相连,网桥会询问所有相连的接口是否拥有原始请求中的 IP 地址(比如这里的 10.42.1.9)。收到响应后,网桥会记录映射信息(10.42.1.9 => veth0),同时将数据转发过去。最终数据经过 veth0 隧道进入 pod httpbin 中。
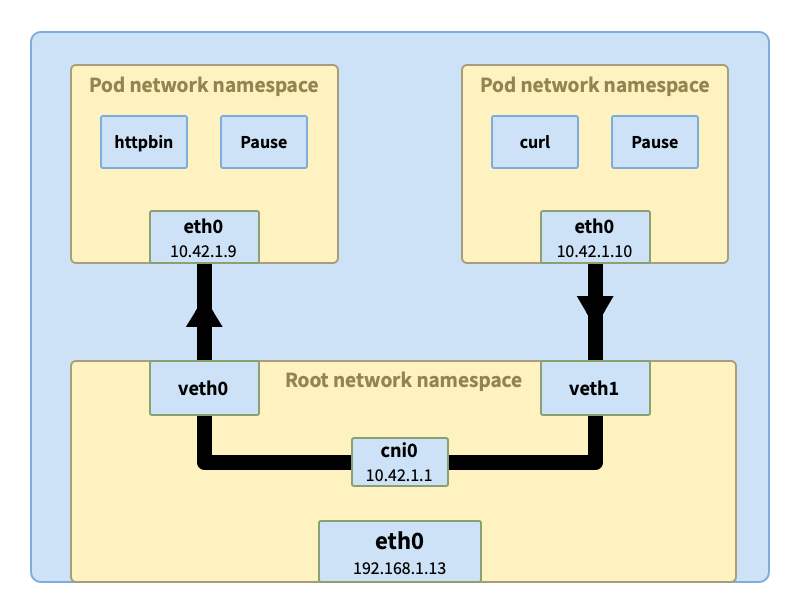
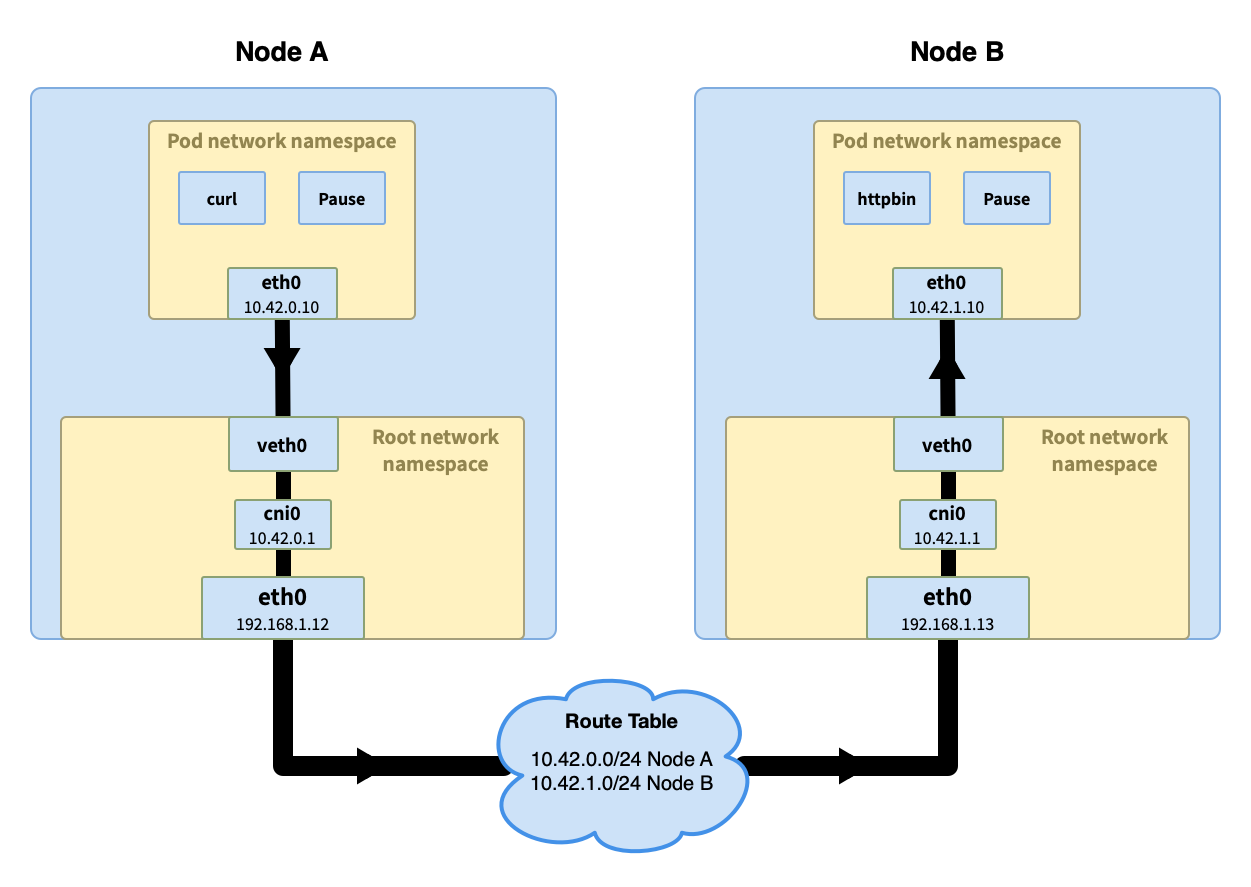
不同节点的 pod 间通信
跨节点的 pod 间通信会复杂一些,且 不同网络插件的处理方式不同,这里选择一种容易理解的方式来简单说明下。
前半部分的流程与同节点 pod 间通信类似,当请求到达网桥,网桥询问哪个 pod 拥有该 IP 但是没有得到回应。流程进入主机的路由寻址过程,到更高的集群层面。
在集群层面有一张路由表,里面存储着每个节点的 Pod IP 网段(节点加入到集群时会分配一个 Pod 网段(Pod CIDR),比如在 k3s 中默认的 Pod CIDR 是 10.42.0.0/16,节点获取到的网段是 10.42.0.0/24、10.42.1.0/24、10.42.2.0/24,依次类推)。通过节点的 Pod IP 网段可以判断出请求 IP 的节点,然后请求被发送到该节点。
总结
现在应该对 Kubernetes 的网络通信有初步的了解了吧。
整个通信的过程需要各种组件的配合,比如 Pod 网络命名空间、pod 以太网接口 eth0、虚拟以太网接口 vethX、网桥(network bridge) cni0 等。其中有些组件与 pod 一一对应,与 pod 同生命周期。虽然可以通过手动的方式创建、关联和删除,但对于 pod 这种非永久性的资源会被频繁地创建和销毁,太多人工的工作也是不现实的。
实际上这些工作都是由容器委托给网络插件来完成的,而网络插件所遵循的规范 CNI(Container Network Interface)。
网络插件都做了什么?
- 创建 pod(容器)的网络命名空间
- 创建接口
- 创建 veth 对
- 设置命名空间网络
- 设置静态路由
- 配置以太网桥接器
- 分配 IP 地址
- 创建 NAT 规则
- …



